This documents compares results obtained when reproducing the experiments from Peter Heist with the latest version of TCP Prague as well as BBRv1 (from the latest Linux kernel, 5.4-rc3 at the time).
Summary plots are shown and discussed in this document, while the full set of results (including packet traces) is available here.
We use the flent tests from P.Heist nearly as-is, and use separate physical machines for all nodes. We diverge from the previous test in how the delays are applied to the scenario: instead of an ingress mirroring action, we use dedicated delaying nodes. Although un-necessary from a RTT/TCP point of view, we kept the original design and applied symmetrical delays in both directions on the delay node.
This is a sanity check to make sure the tools worked, and evaluate some basics.
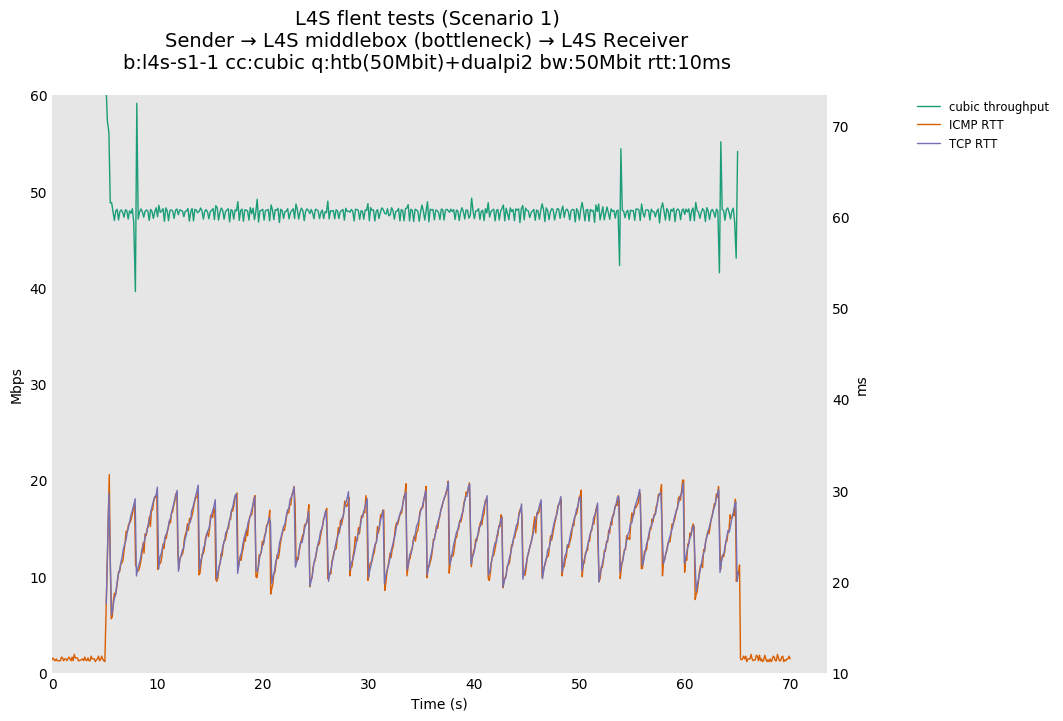
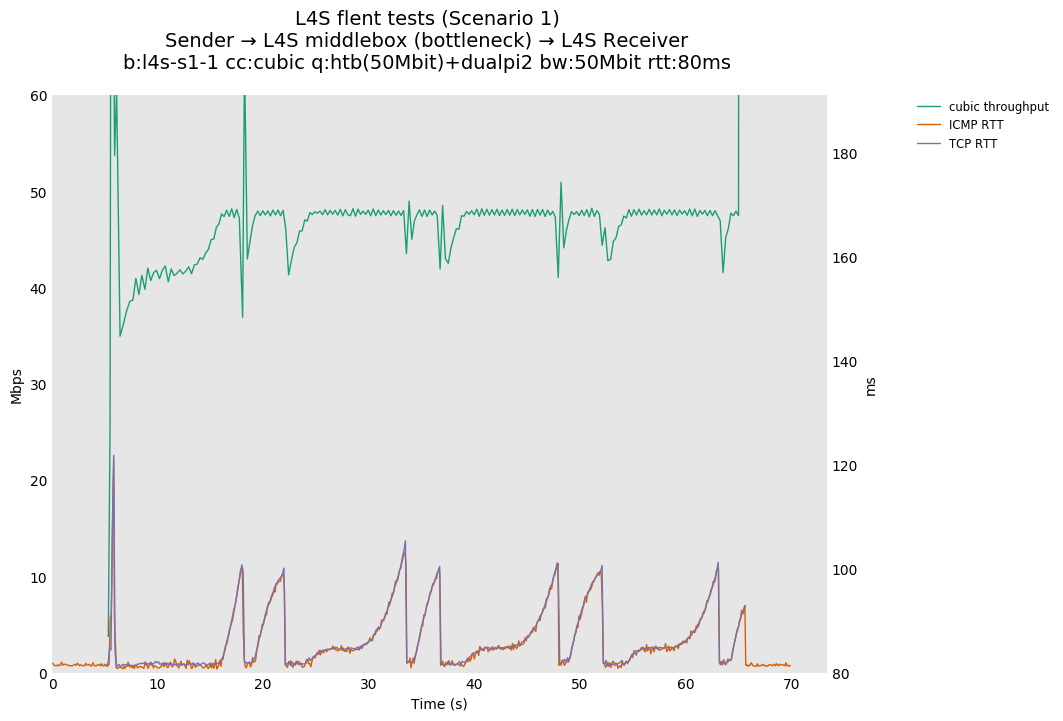
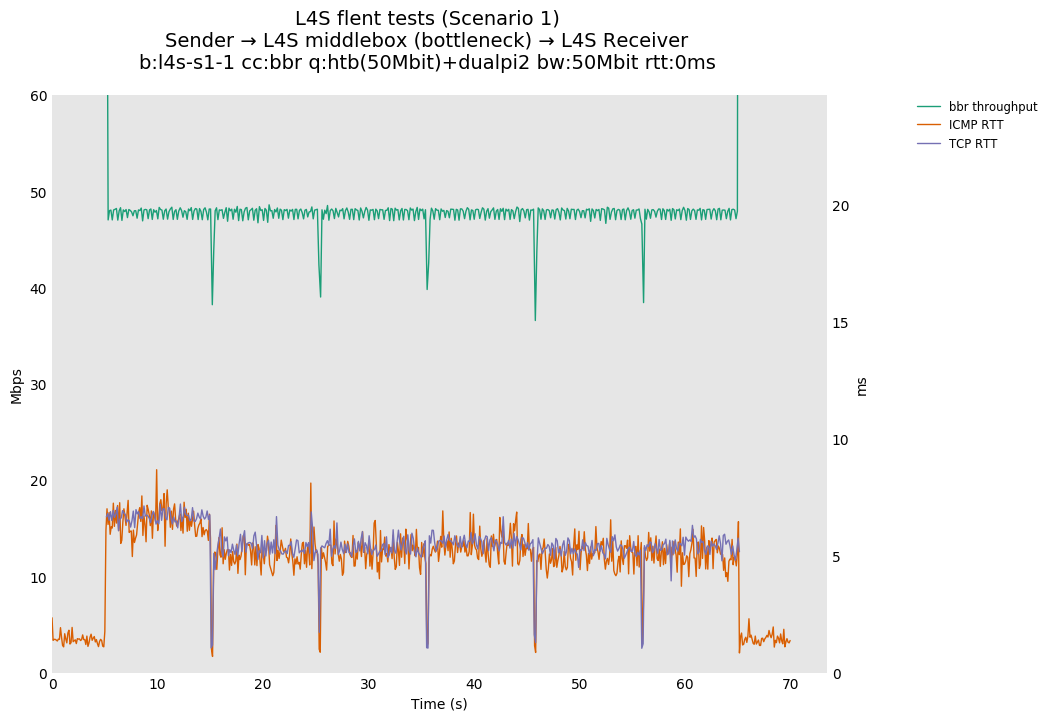
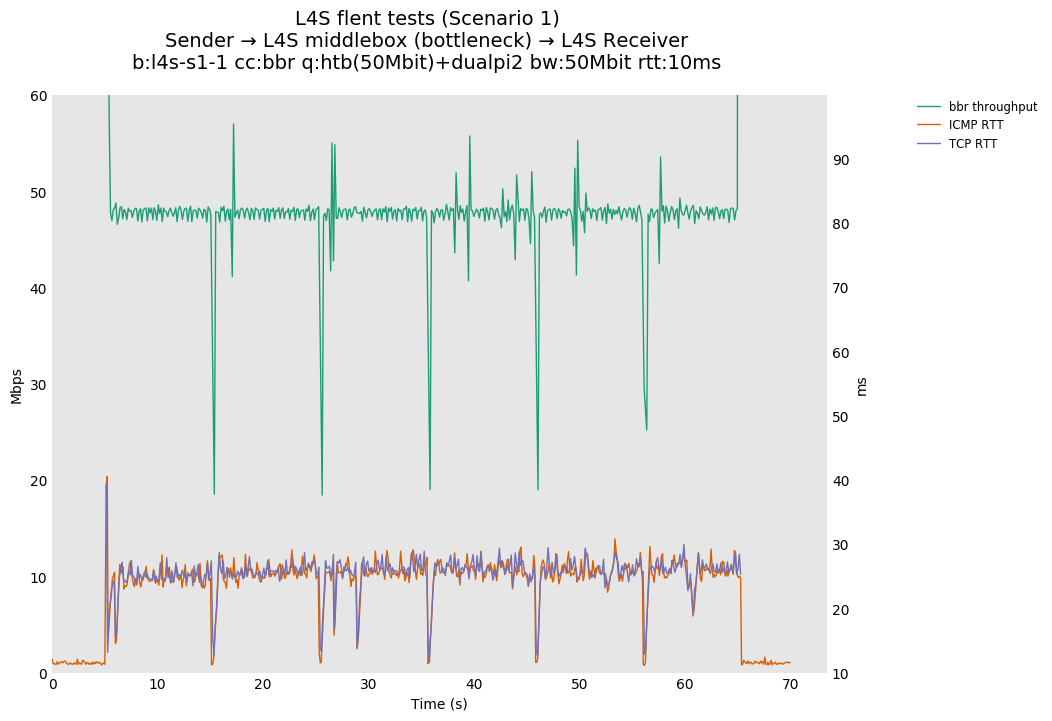
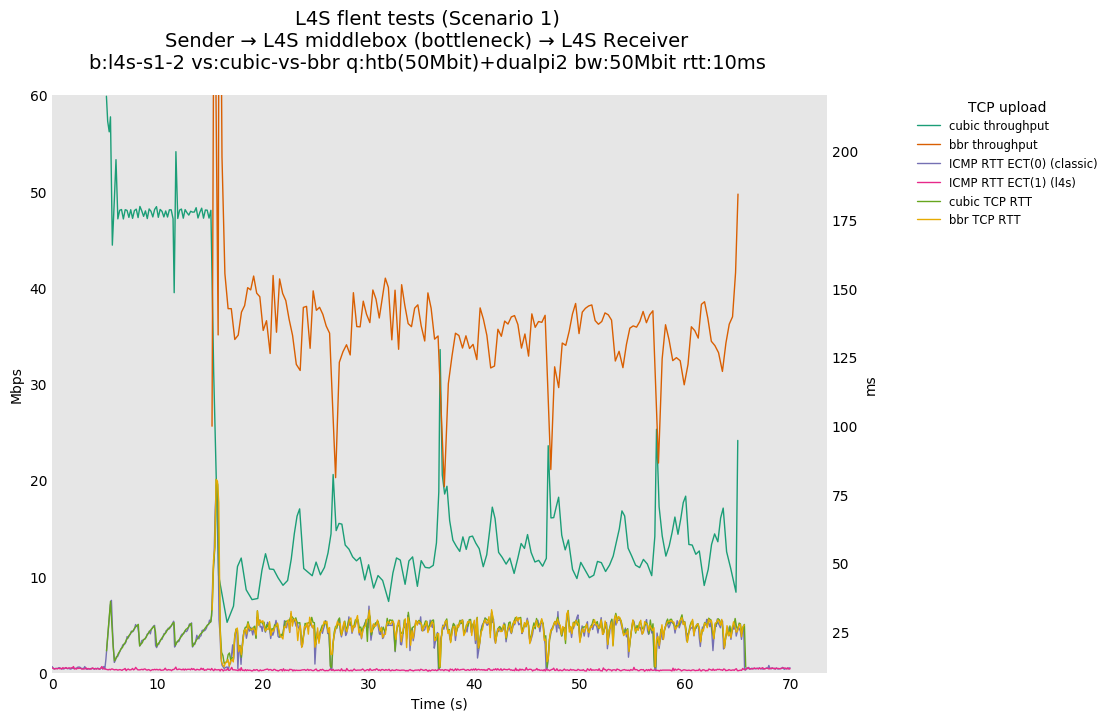
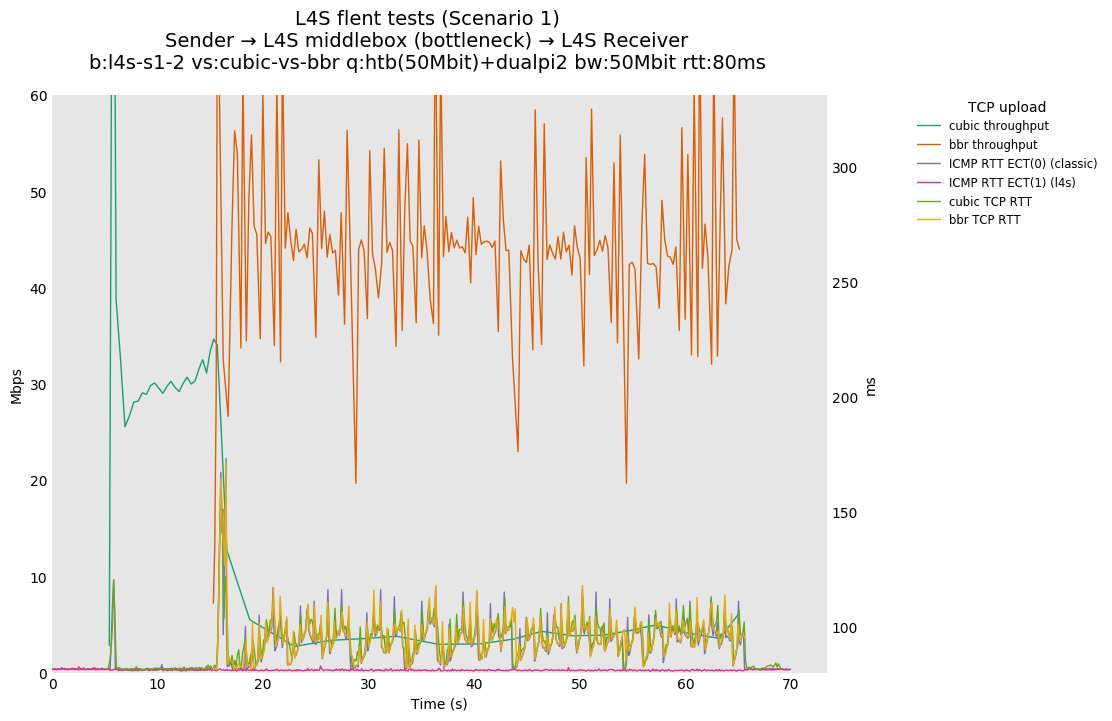
L4S: Sender → L4S middlebox (bottleneck) → L4S Receiver
| 50Mb-0ms | 50Mb-10ms | 50Mb-80ms |
|---|---|---|
| cubic | cubic | cubic |
| bbr | bbr | bbr |
| prague | prague | prague |
| prague-vs-prague | prague-vs-prague | prague-vs-prague |
| cubic-vs-prague | cubic-vs-prague | cubic-vs-prague |
| cubic-vs-bbr | cubic-vs-bbr | cubic-vs-bbr |
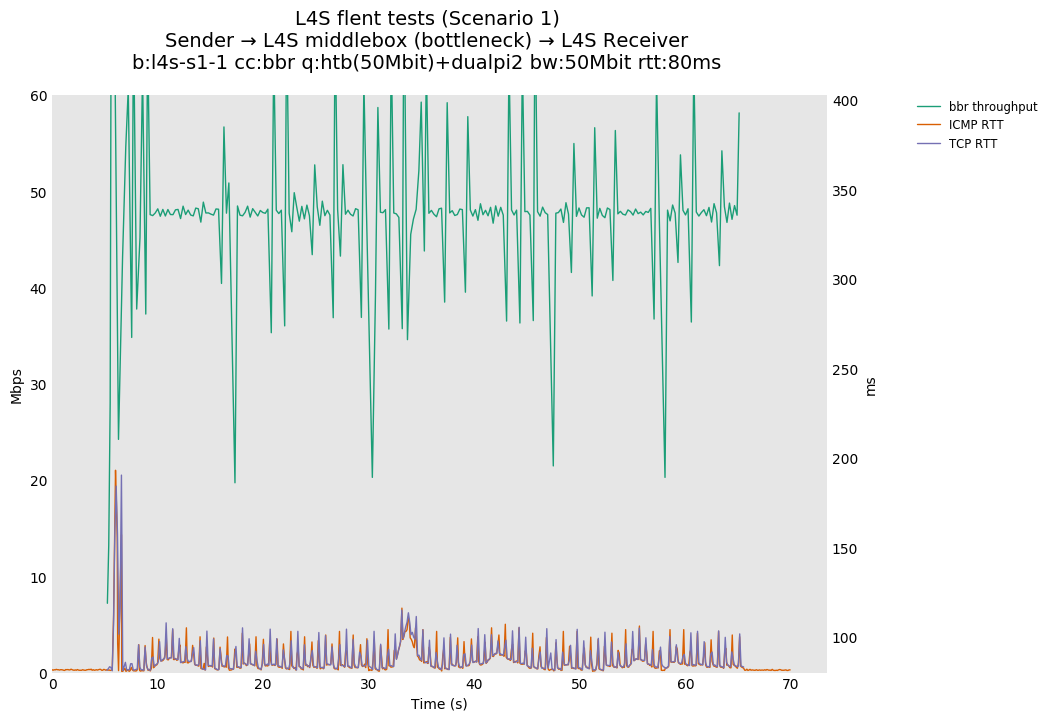
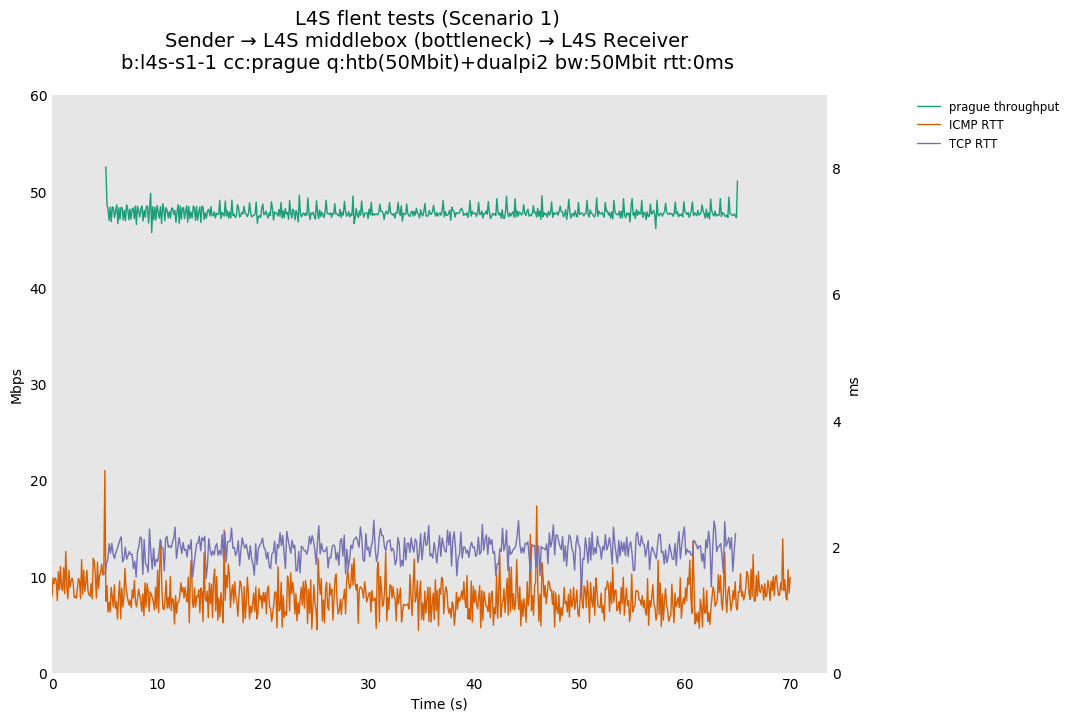
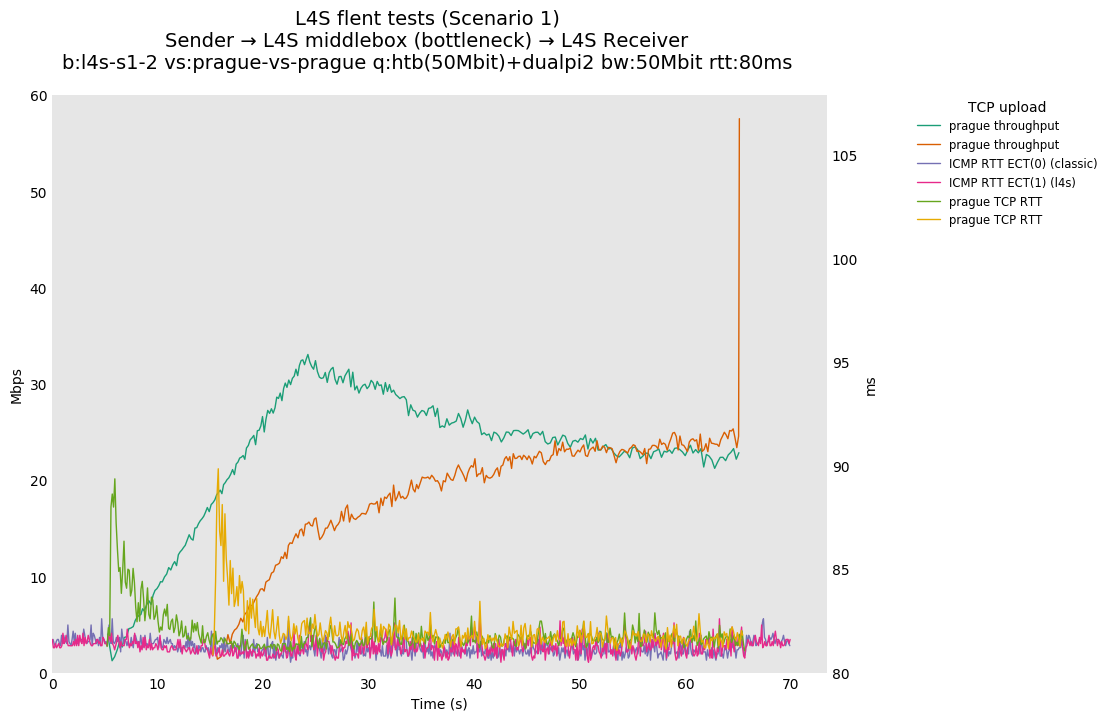
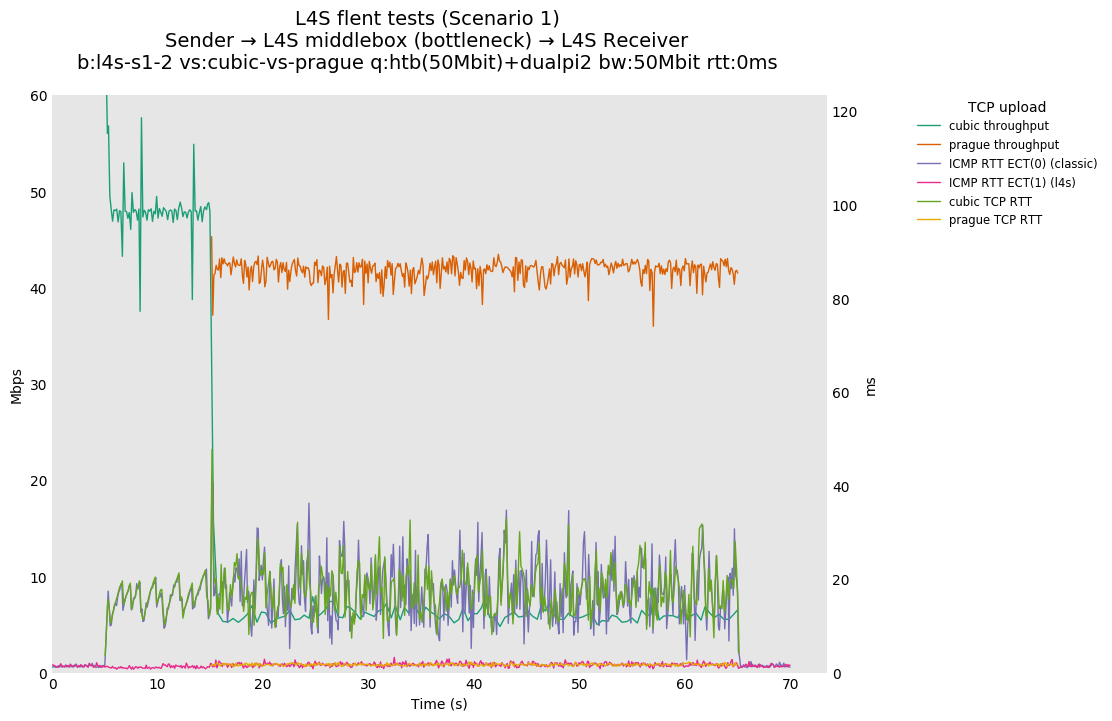
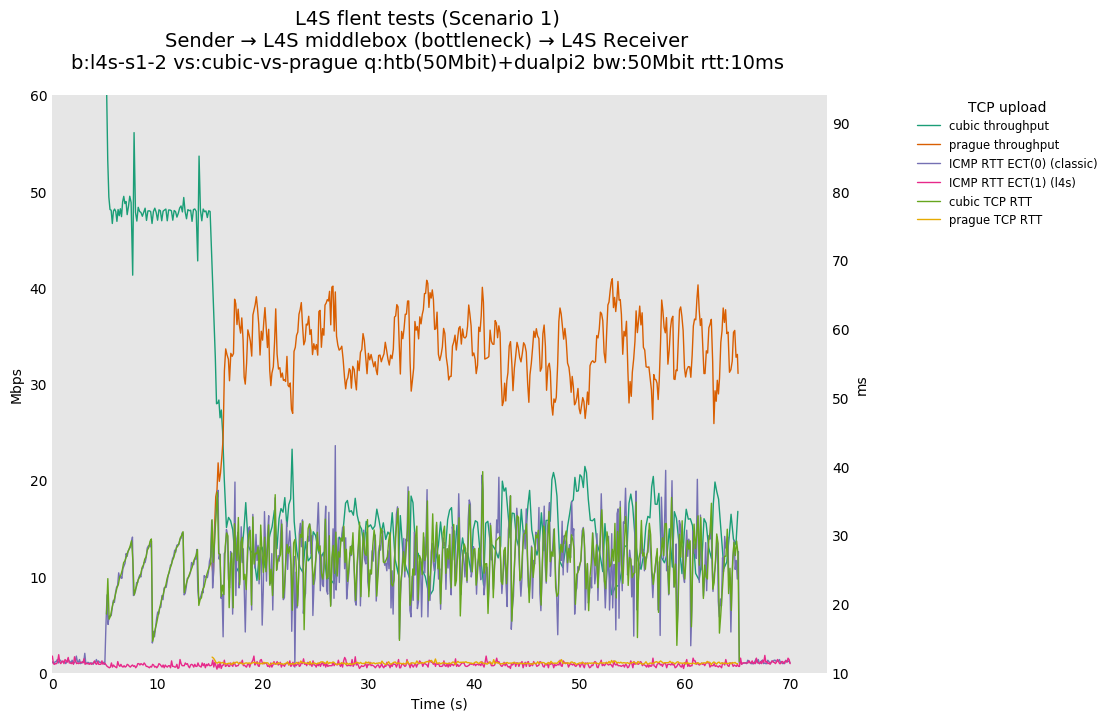
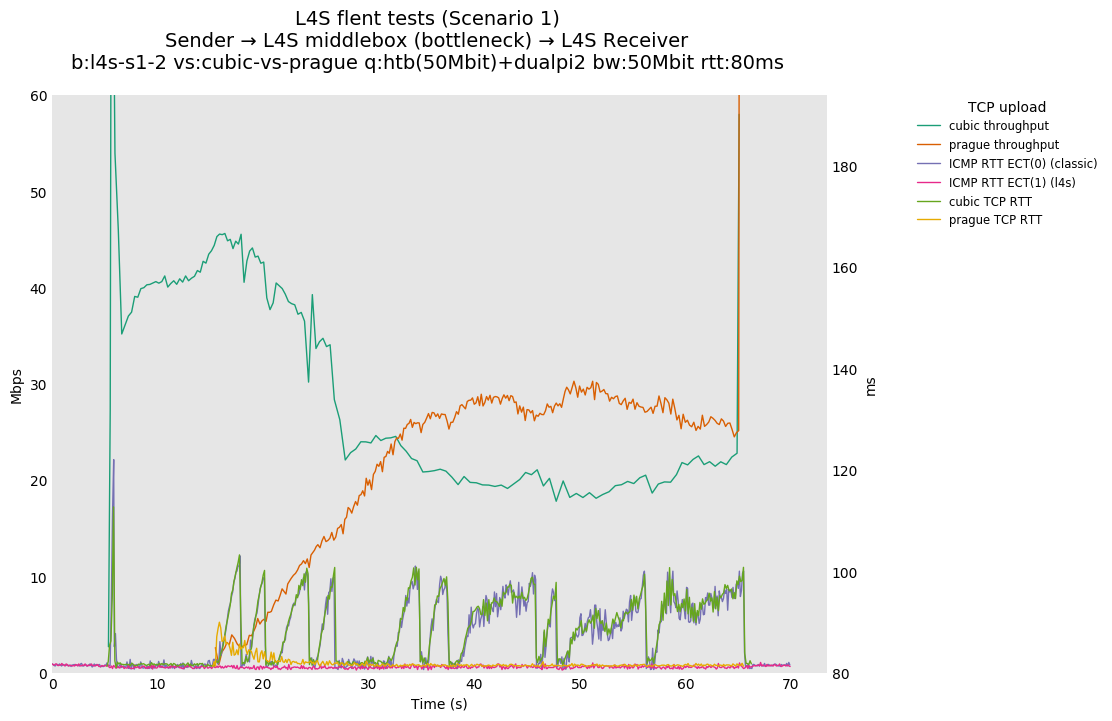
In isolation, dualpi2 achieves its latency target for both queues: - The C queue (cubic, bbr) buffers about 15ms of data on average (the configured PI2 target), which enables the link to be fully utilized even at higher base RTTs - The L queue (prague) keeps the additional latency to a minimum (1ms), without sacrificing throughput. We note that TCP Prague takes longer to converge, as it relies on the traditional Reno additive increase. Alternatives are being explored, such as Paced-chirping, or hystart derivatives.
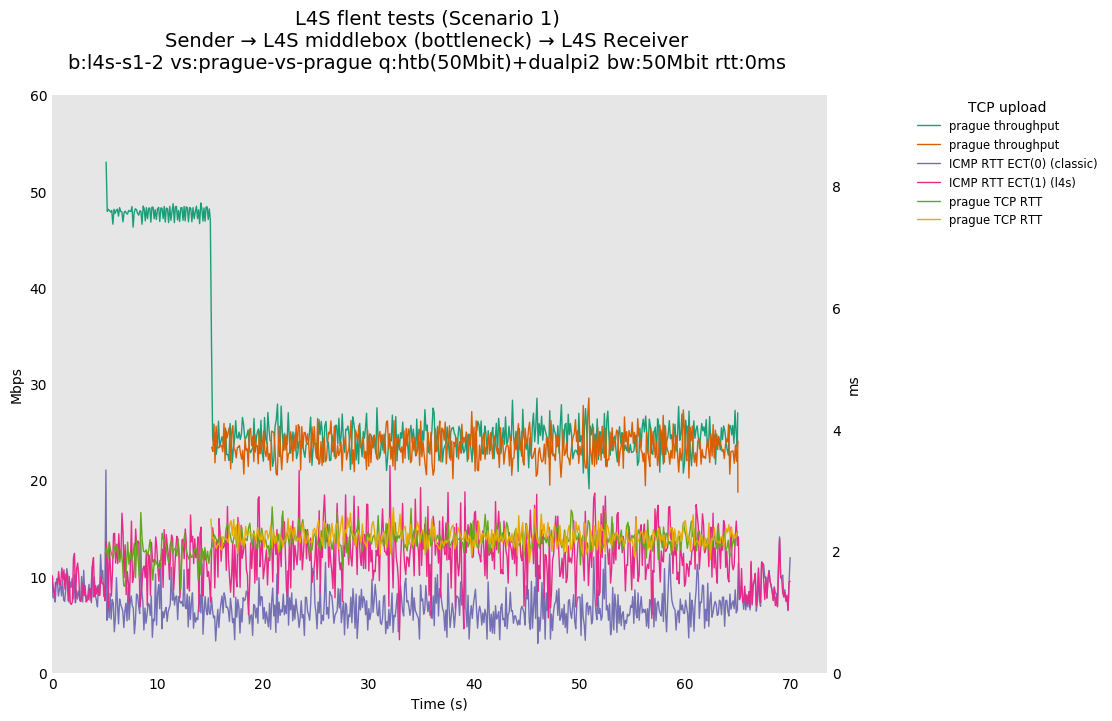
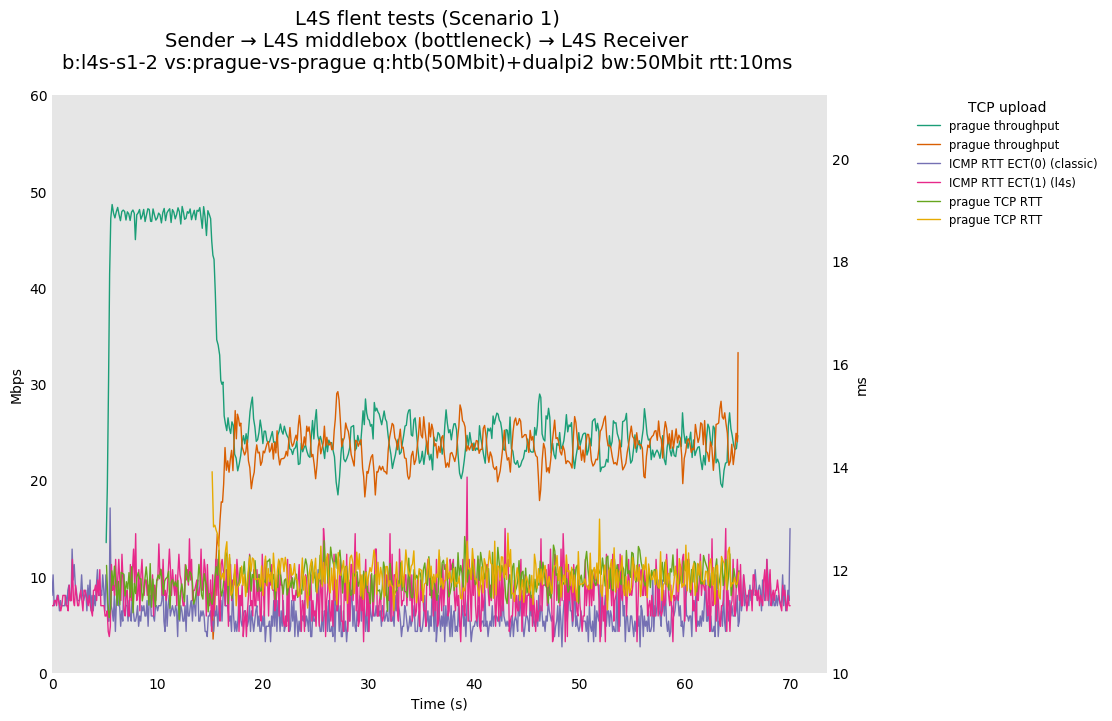
With multiple flows: - prague-vs-prague shows that if dualpi2 only sees L4S traffic, the L queue is solely driven by its immediate (step) AQM, enabling it to achieve its target delay - cubic-vs-prague shows the effect of the coupling of dualpi2, which achieves window fairness across both queues. - cubic-vs-bbr shows that bbr drives PI2 to a high marking rate, which pushes cubic away. The magnitude of this effect is RTT dependent.
This is the most favourable-to-L4S topology that incorporates a non-L4S component that we could easily come up with.
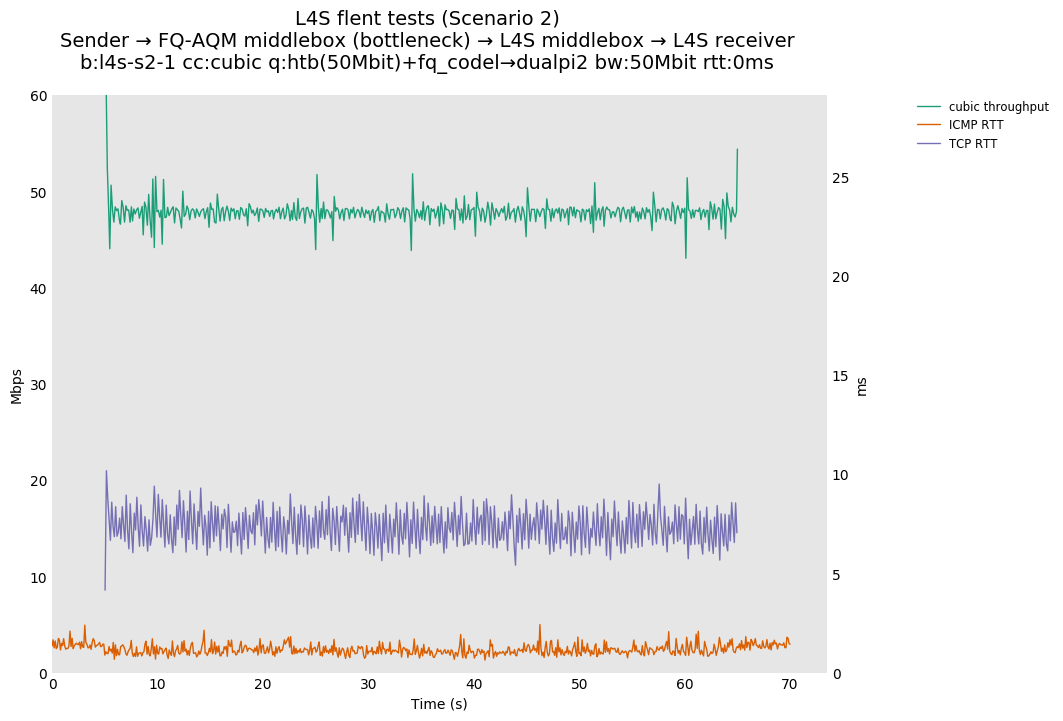
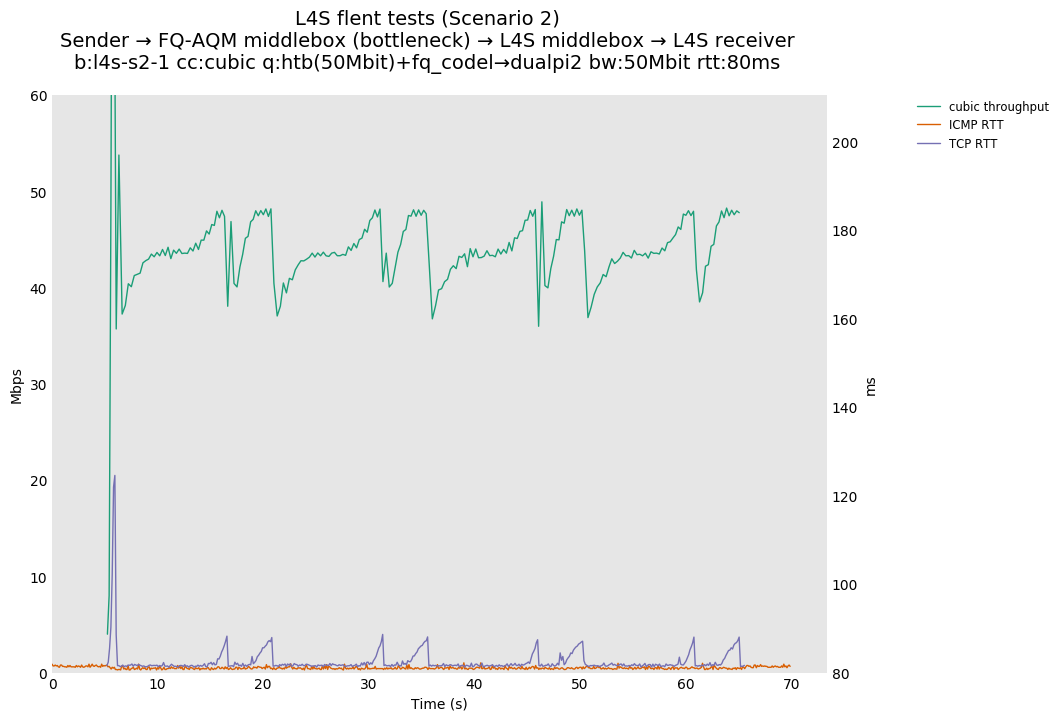
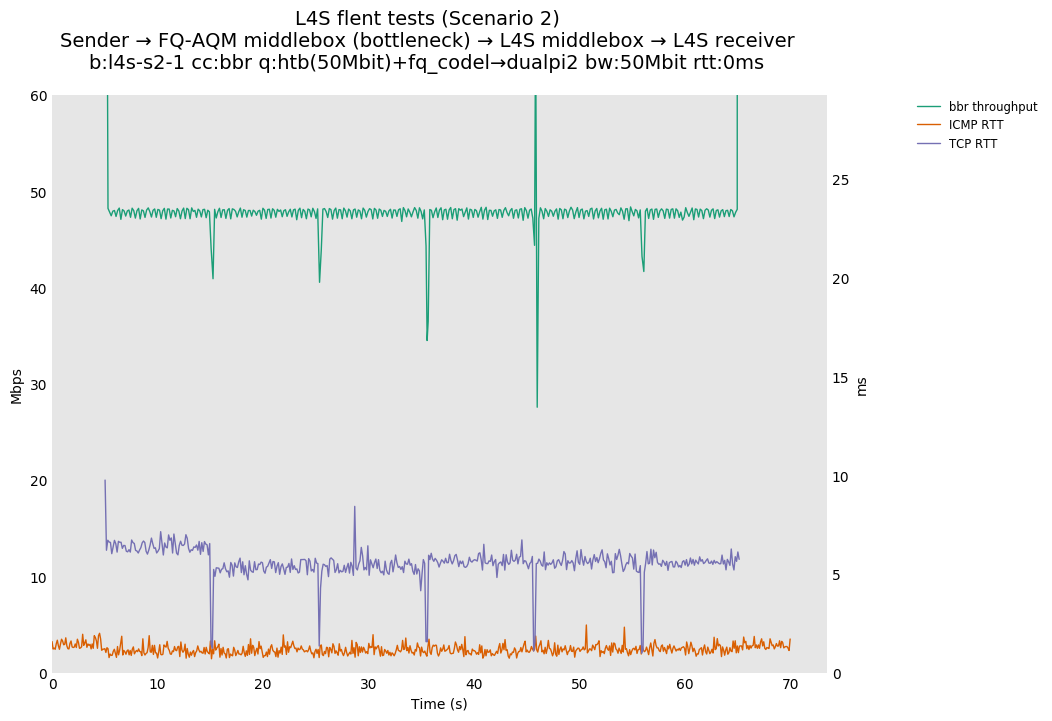
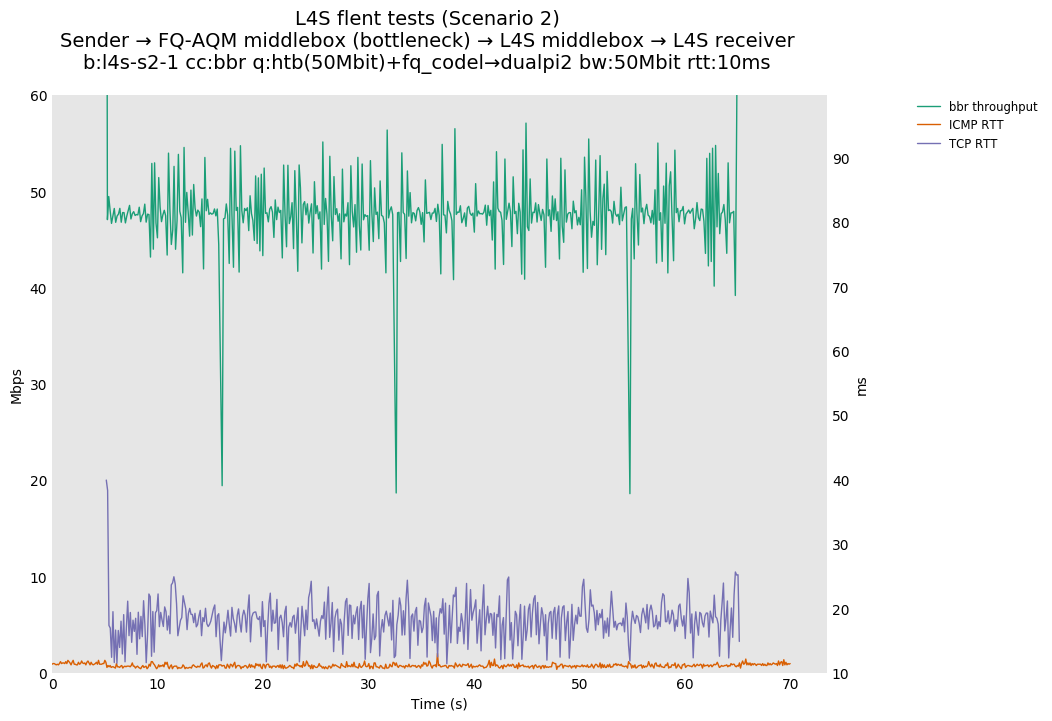
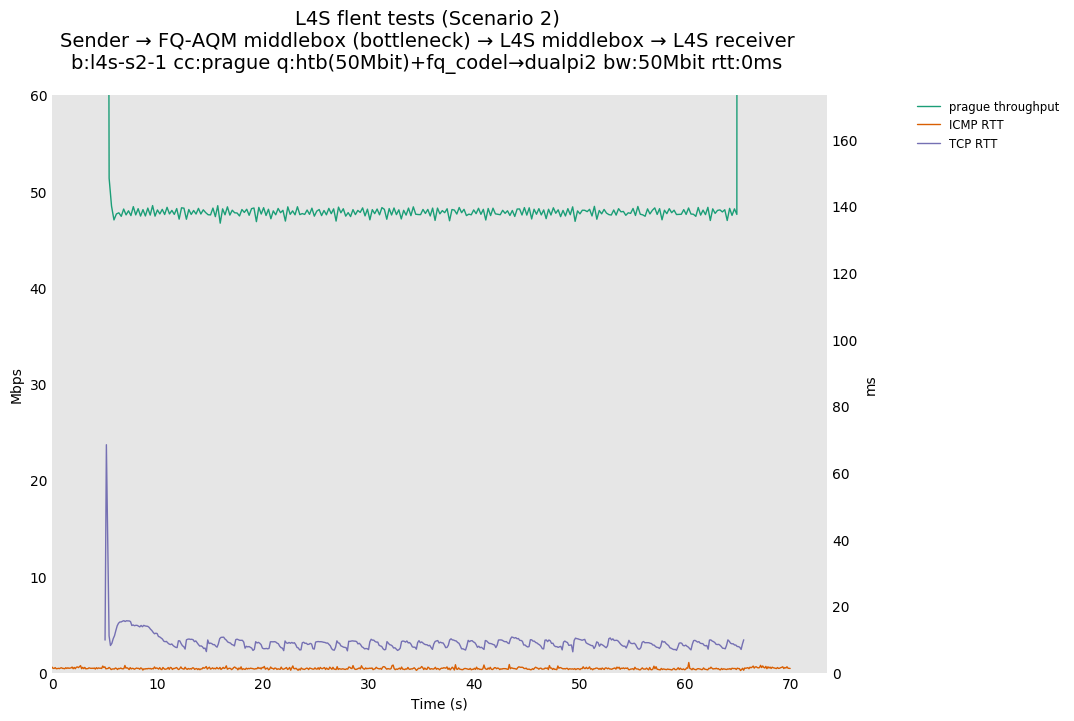
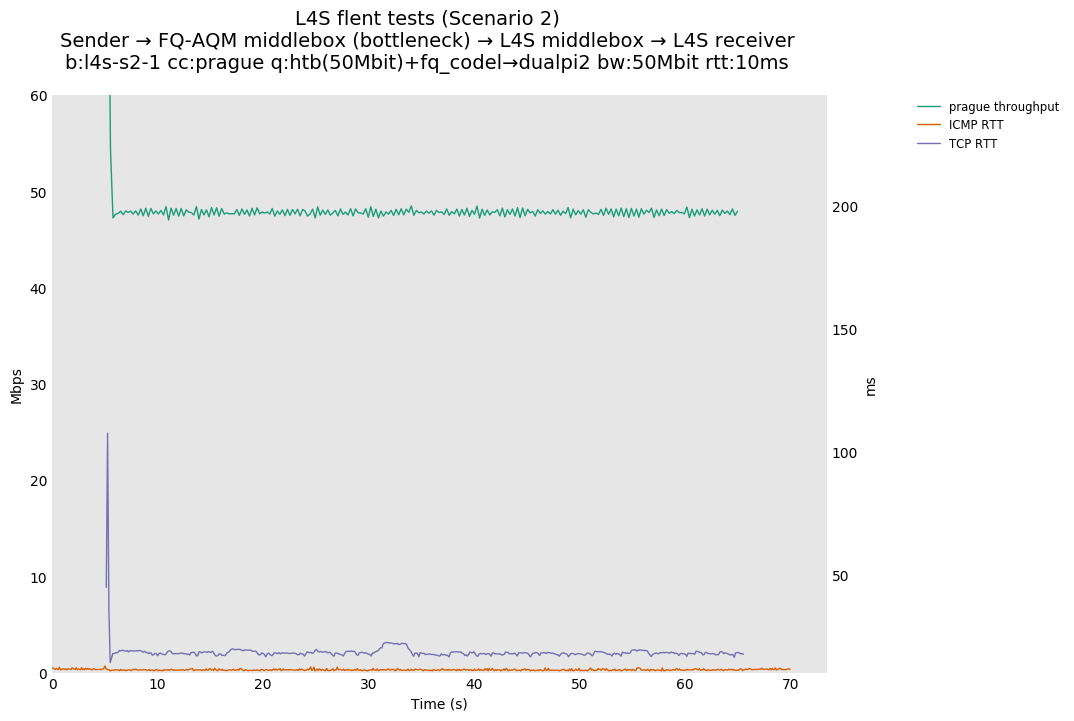
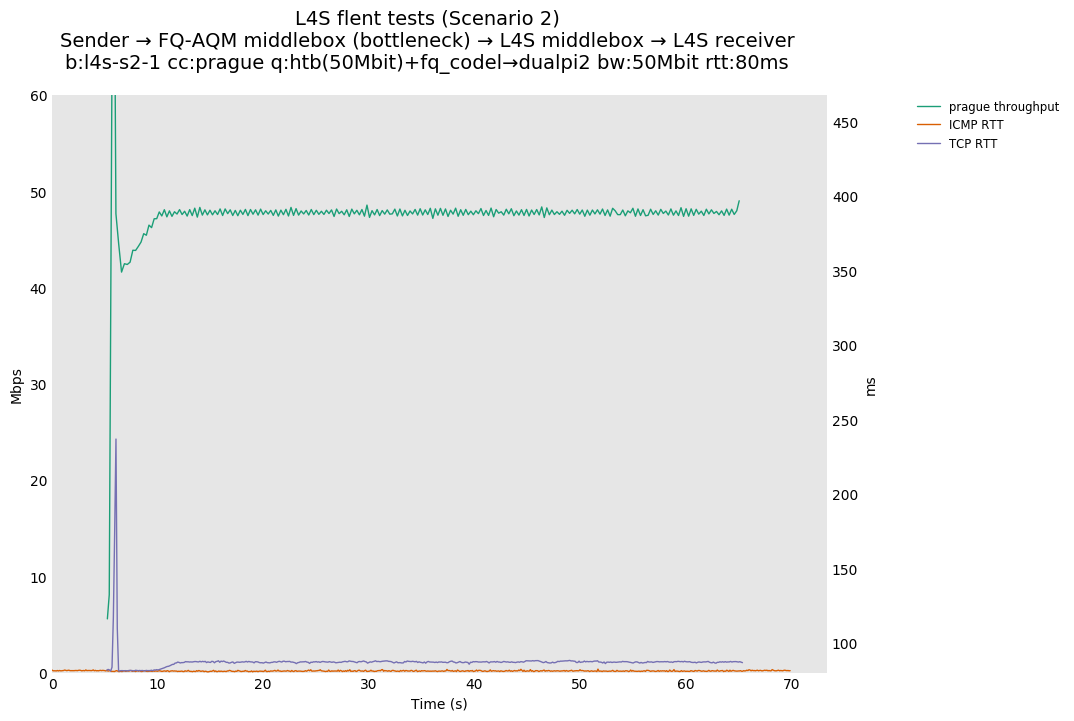
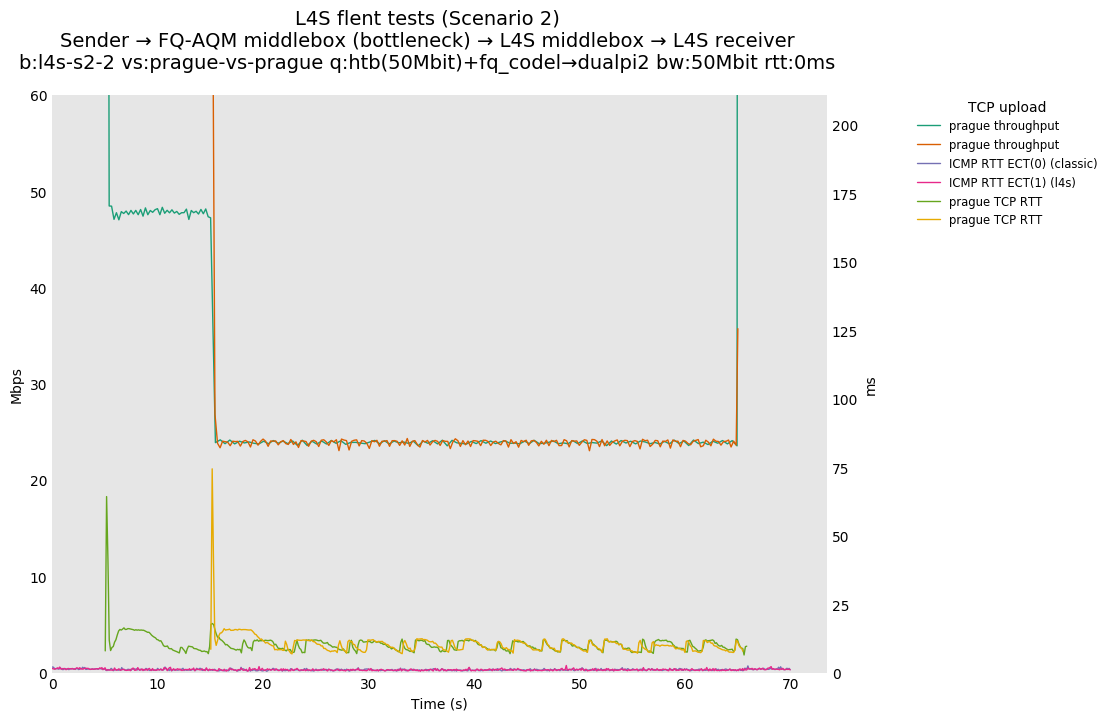
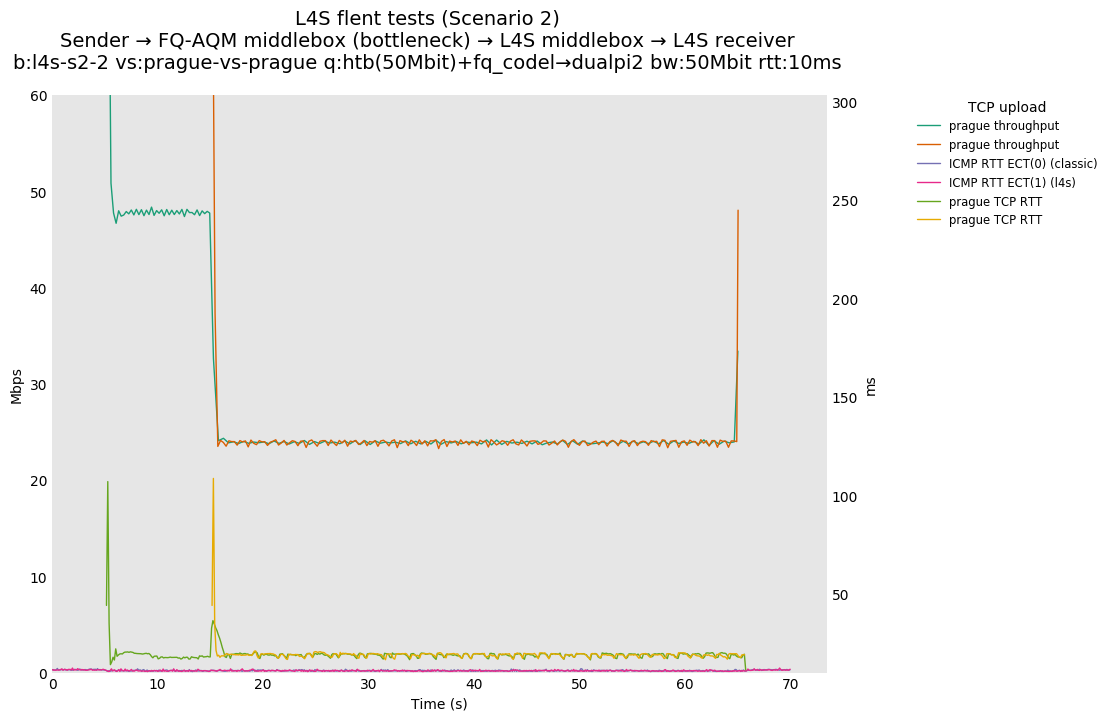
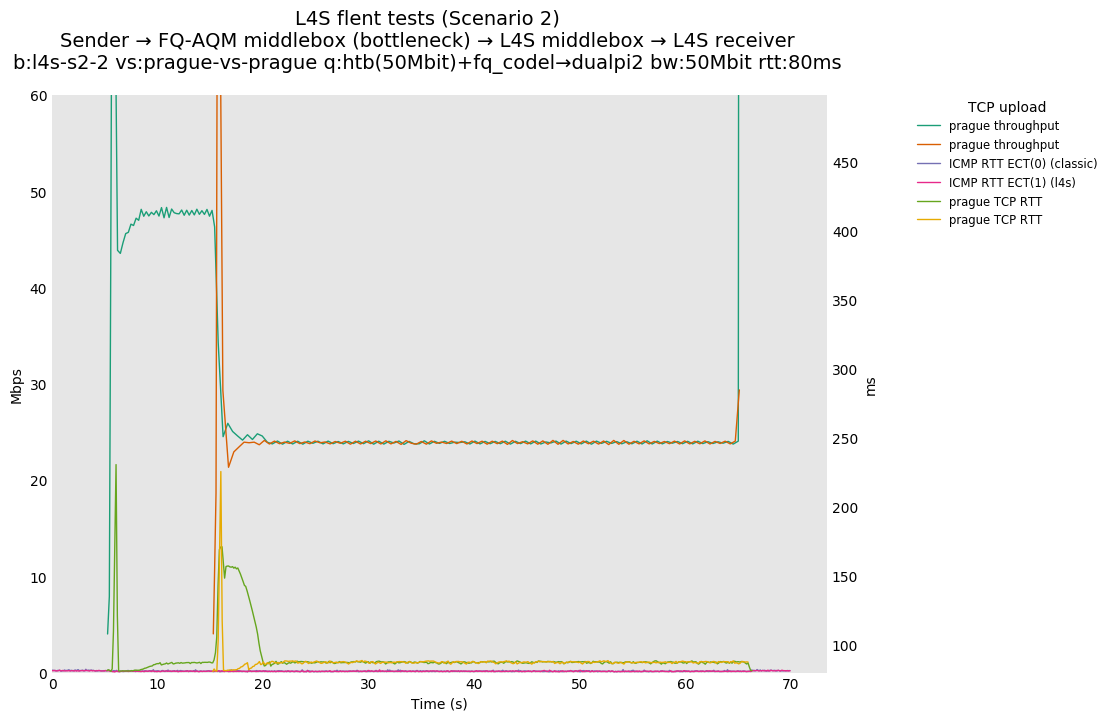
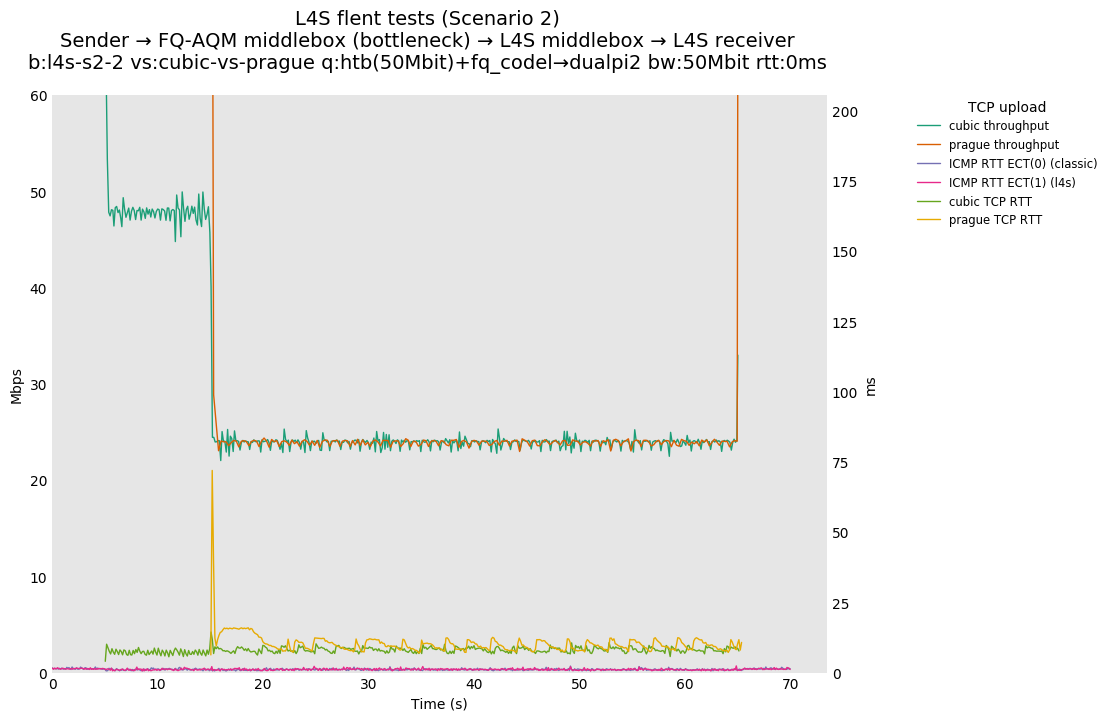
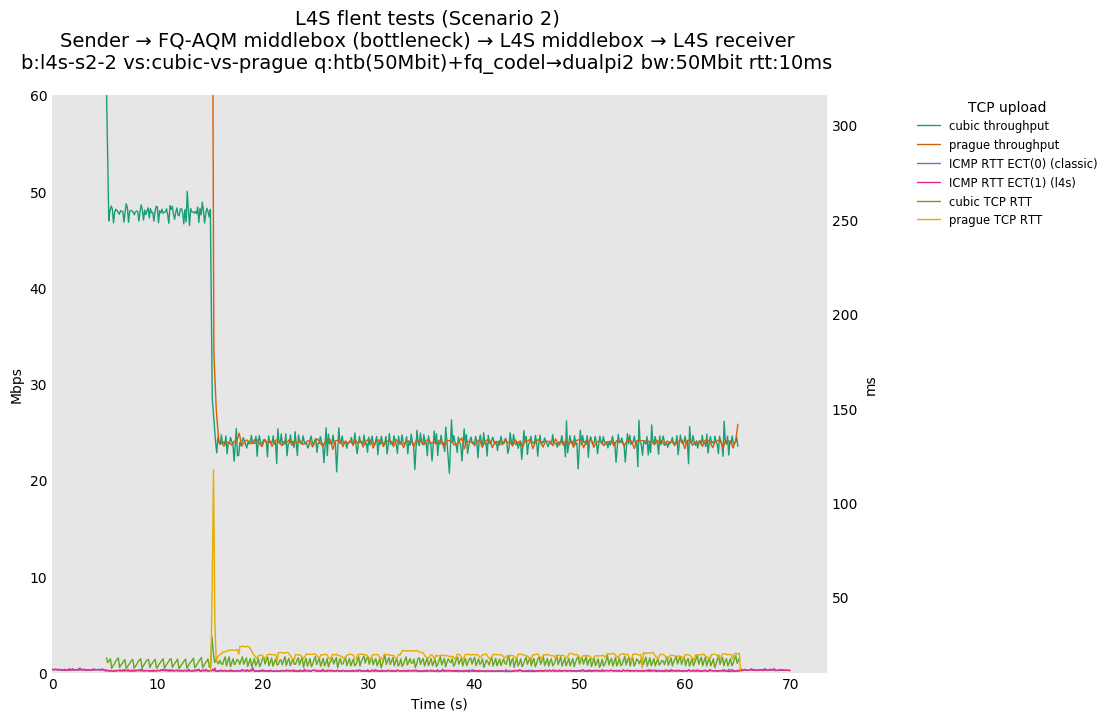
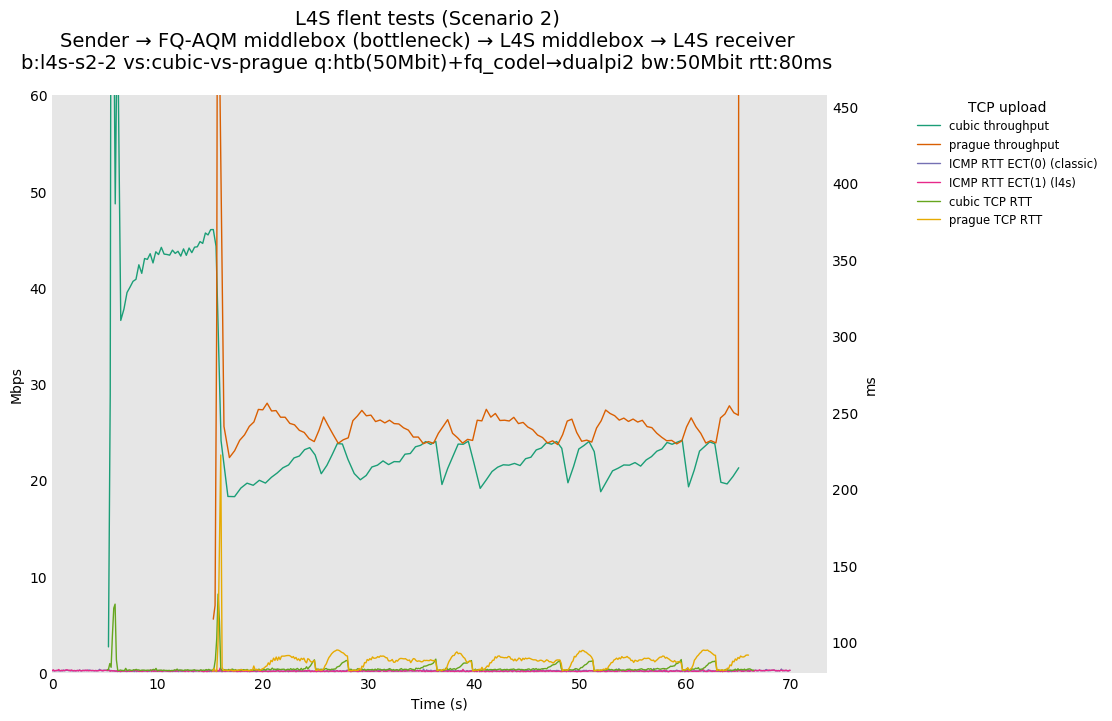
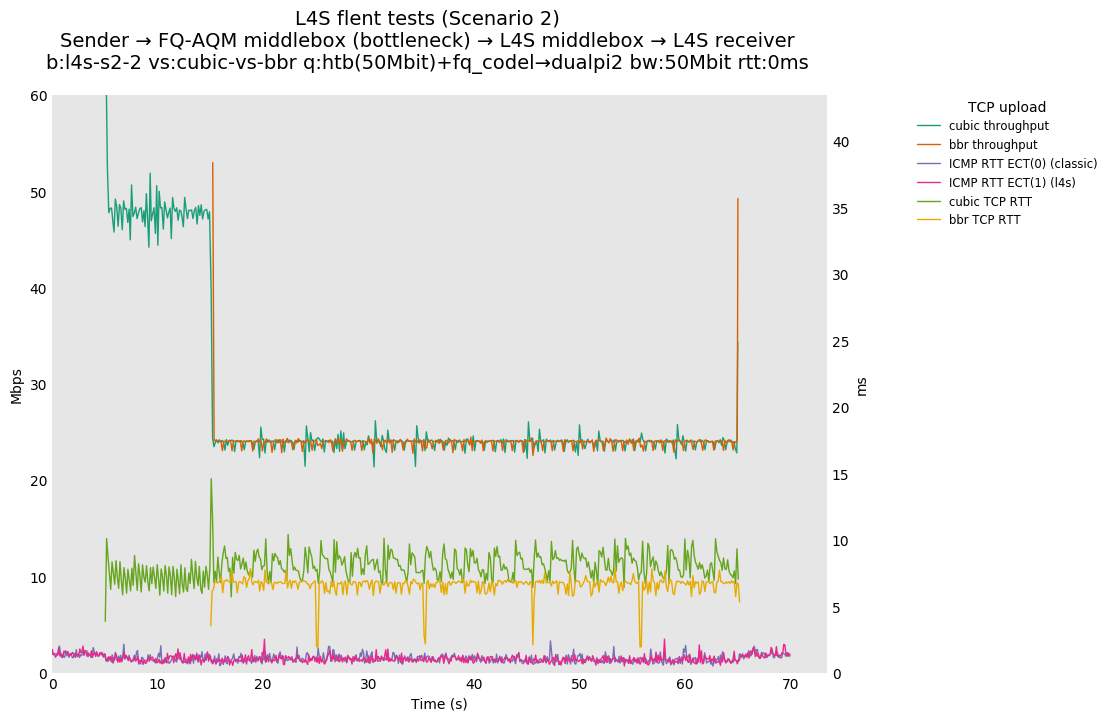
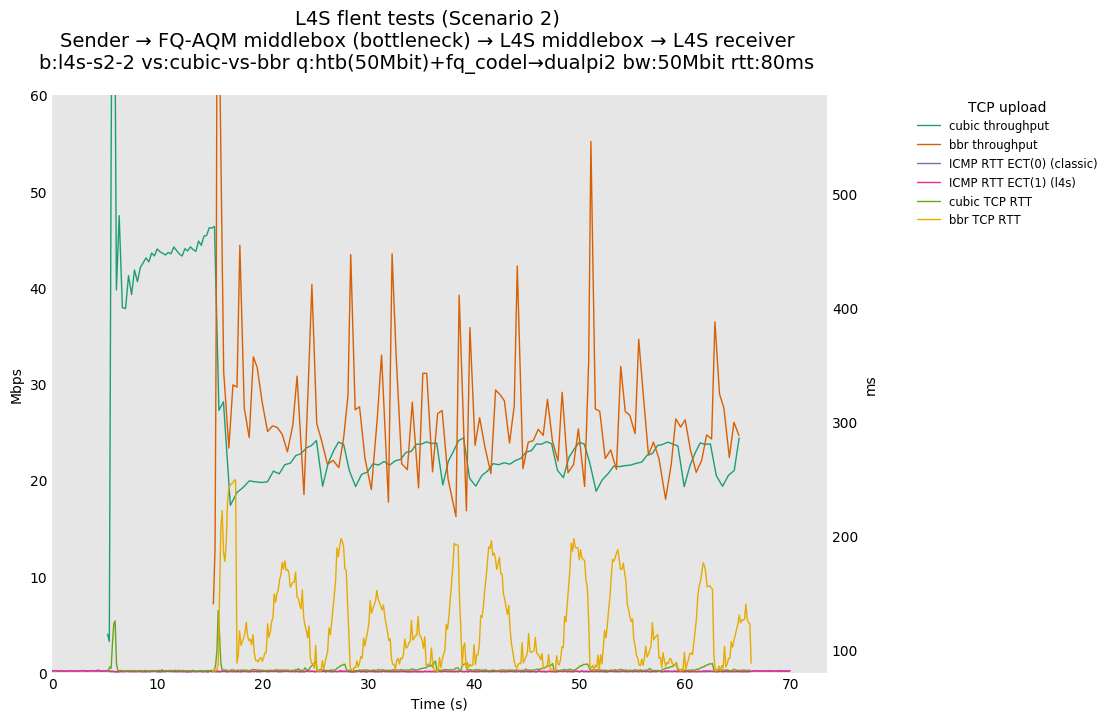
L4S: Sender → FQ-AQM middlebox (bottleneck) → L4S middlebox → L4S receiver
| 50Mb-0ms | 50Mb-10ms | 50Mb-80ms |
|---|---|---|
| cubic | cubic | cubic |
| bbr | bbr | bbr |
| prague | prague | prague |
| prague-vs-prague | prague-vs-prague | prague-vs-prague |
| cubic-vs-prague | cubic-vs-prague | cubic-vs-prague |
| cubic-vs-bbr | cubic-vs-bbr | cubic-vs-bbr |
These results differs from the first scenario in their target latency, as the flows are controlled by CoDel instances. We see that both Prague and bbr (as well as cubic at 80ms RTT) experience a short-lived high latency when exiting slow-start.
We also see that CoDel struggles to keep cubic RTTs under control when it fully utilizes the link at 10ms, or achieves its target at 80ms by under-utilizing the link by 10%.
This scenario is obtained from topology 2 by adding the
flows 1parameter to fq_codel, making it a single queue AQM. Any queueing delays will affect all other flows in the queue.
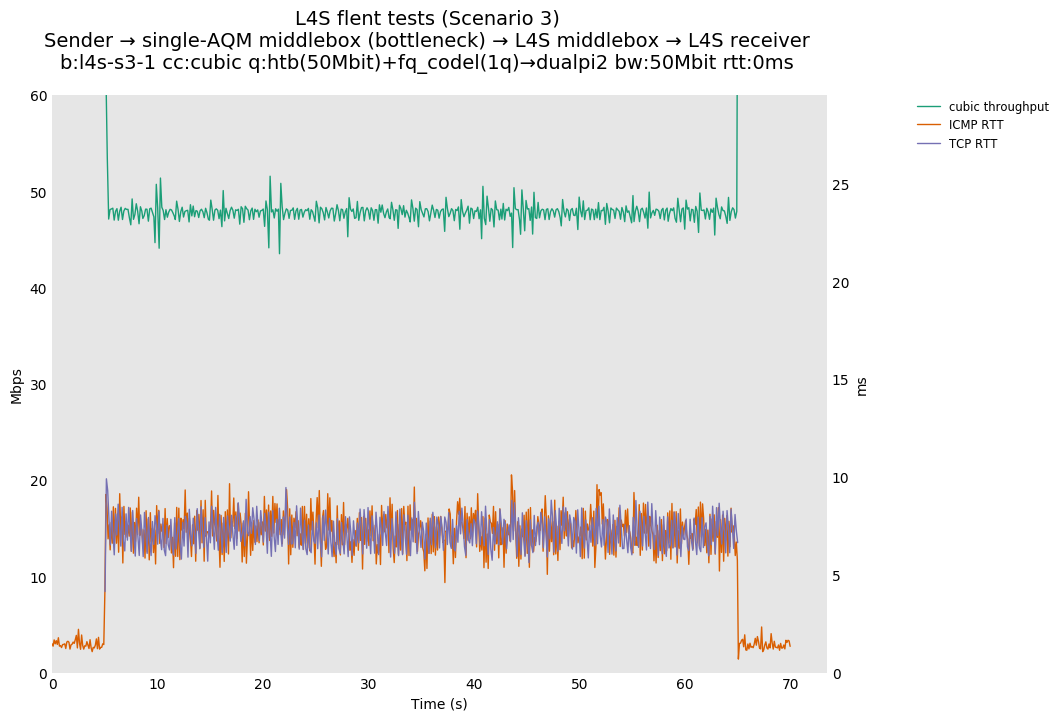
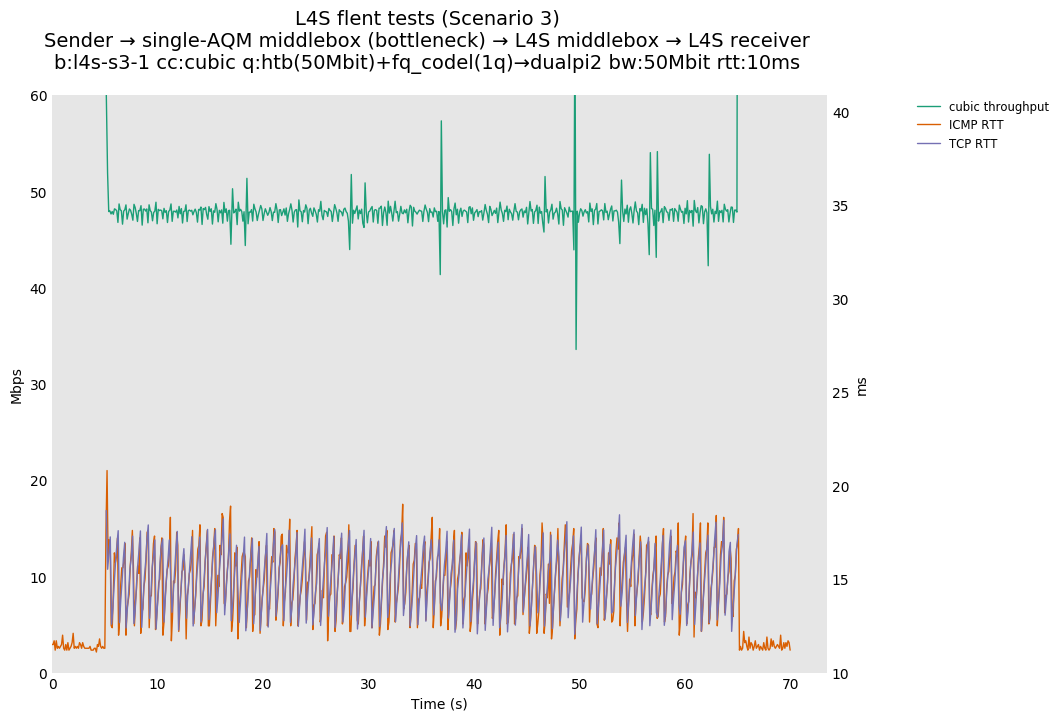
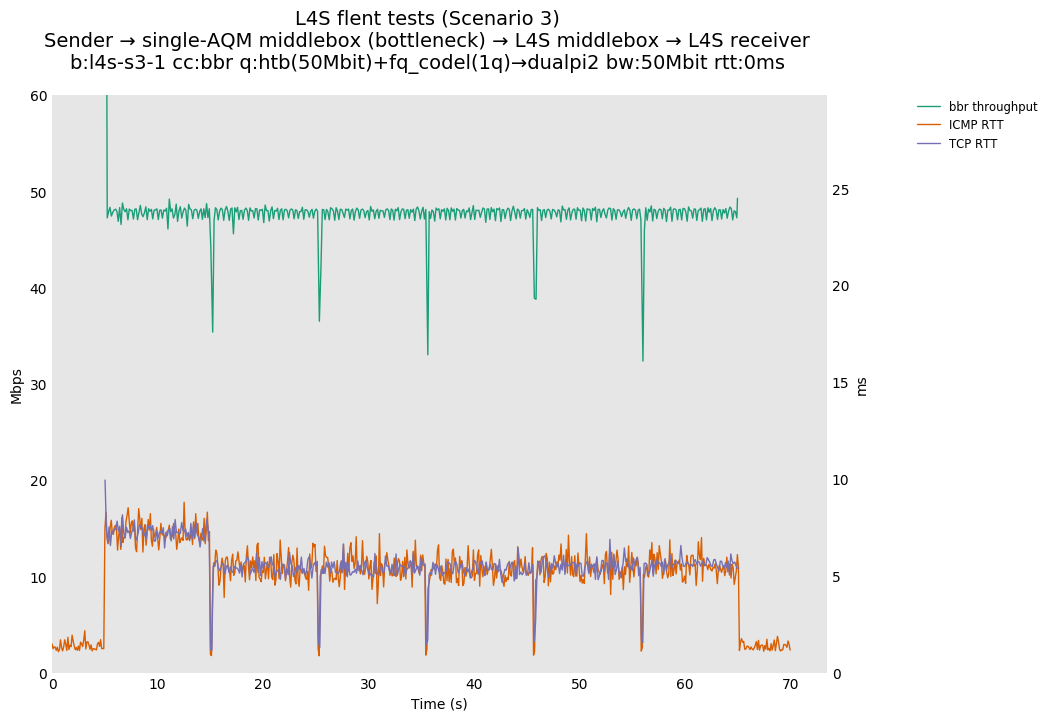
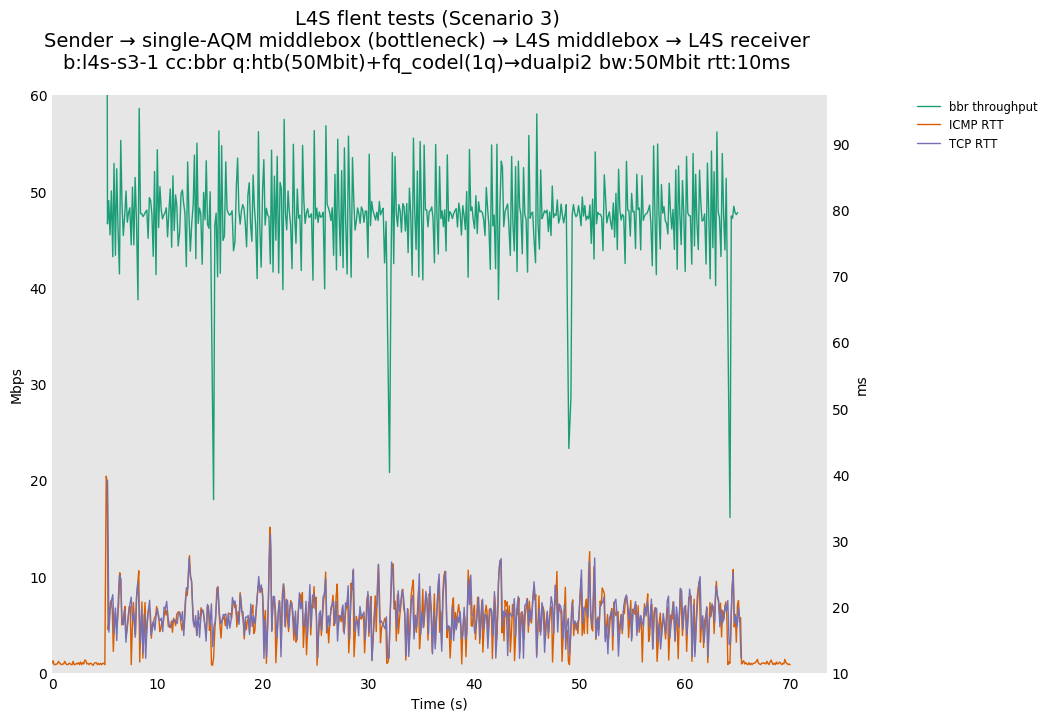
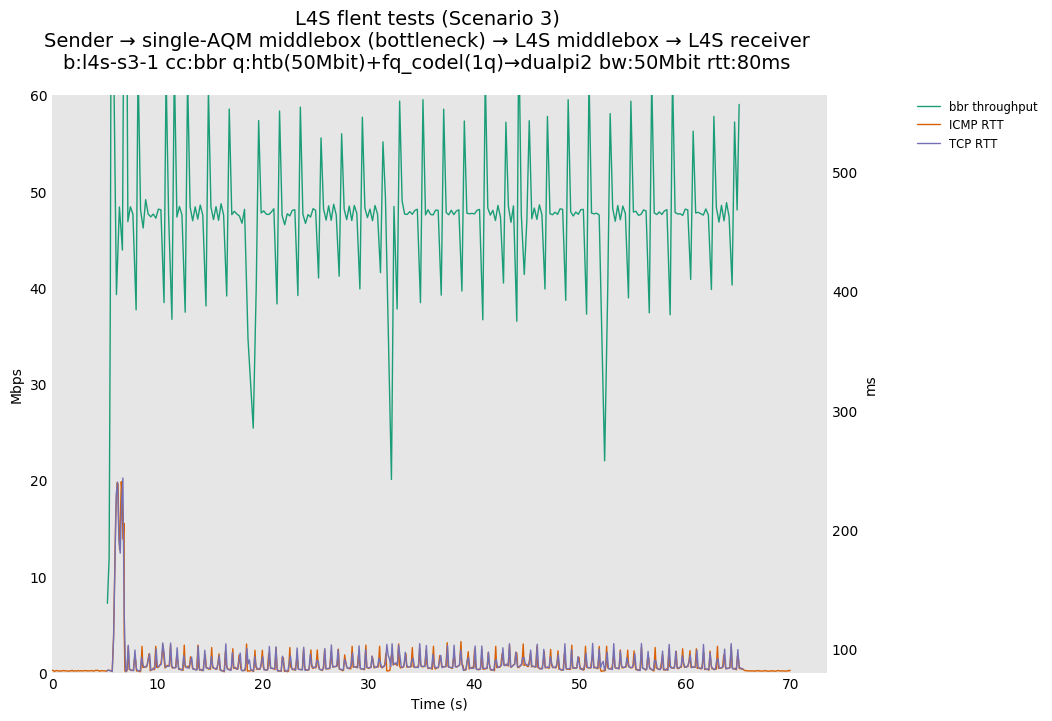
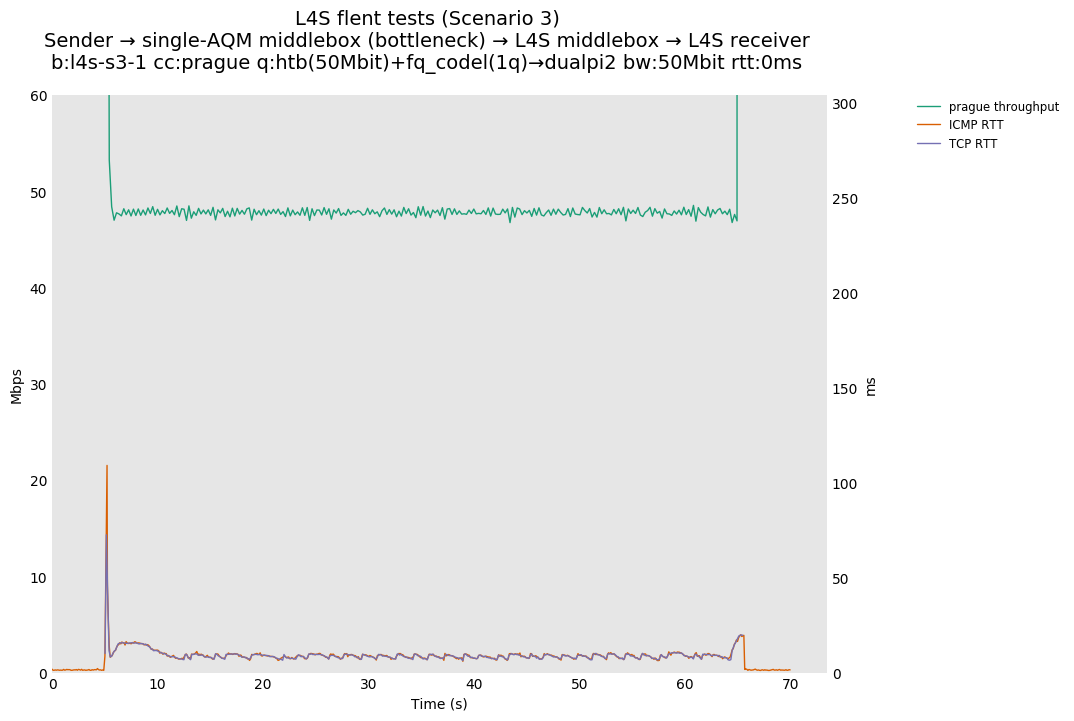
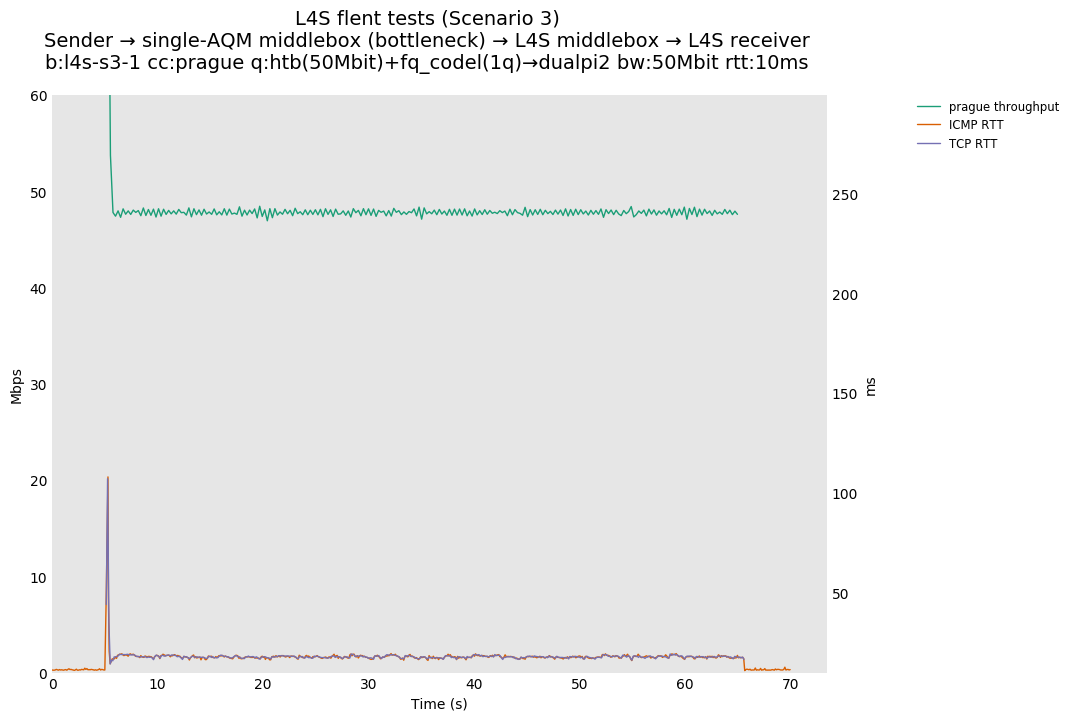
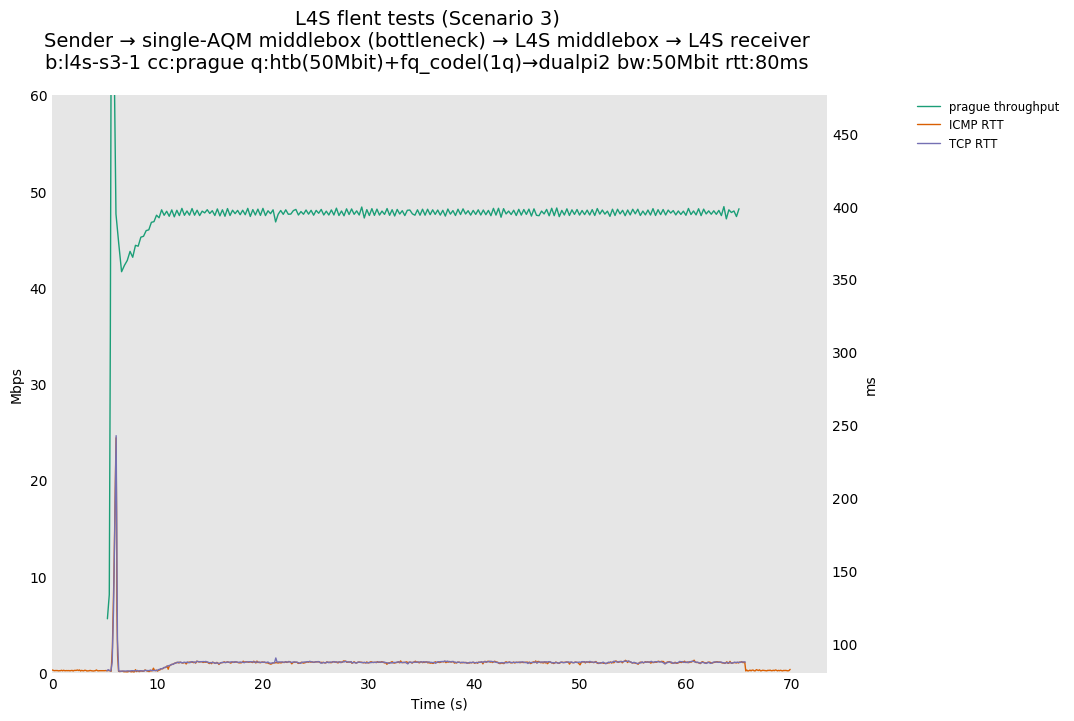
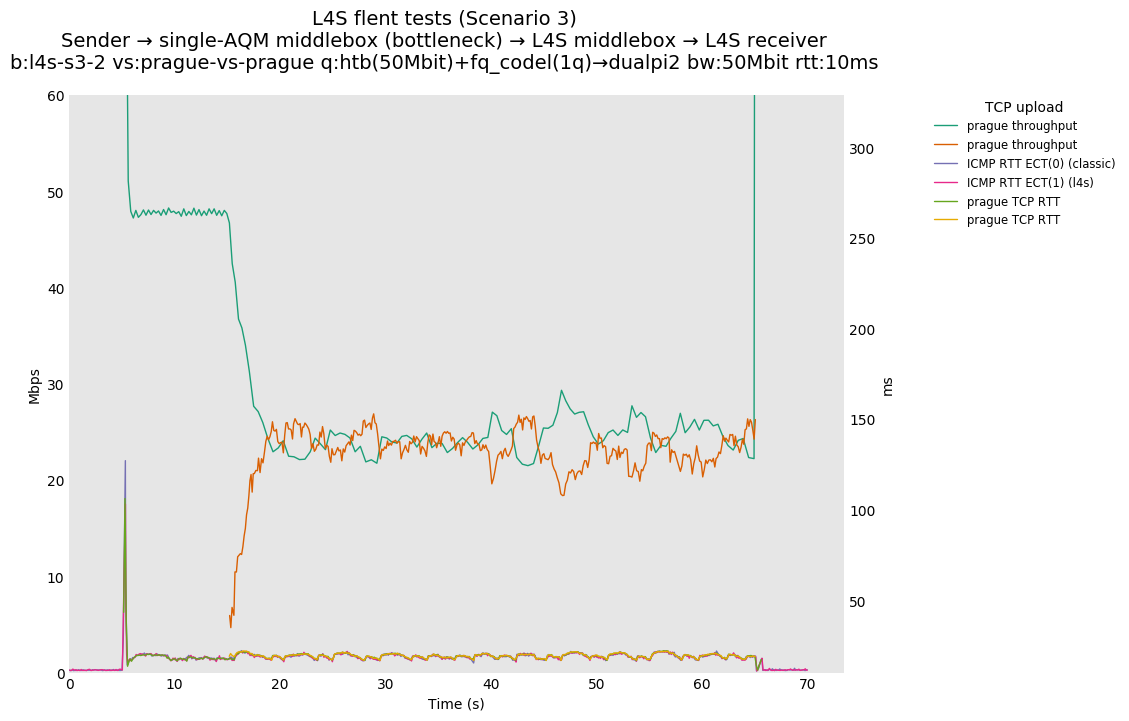
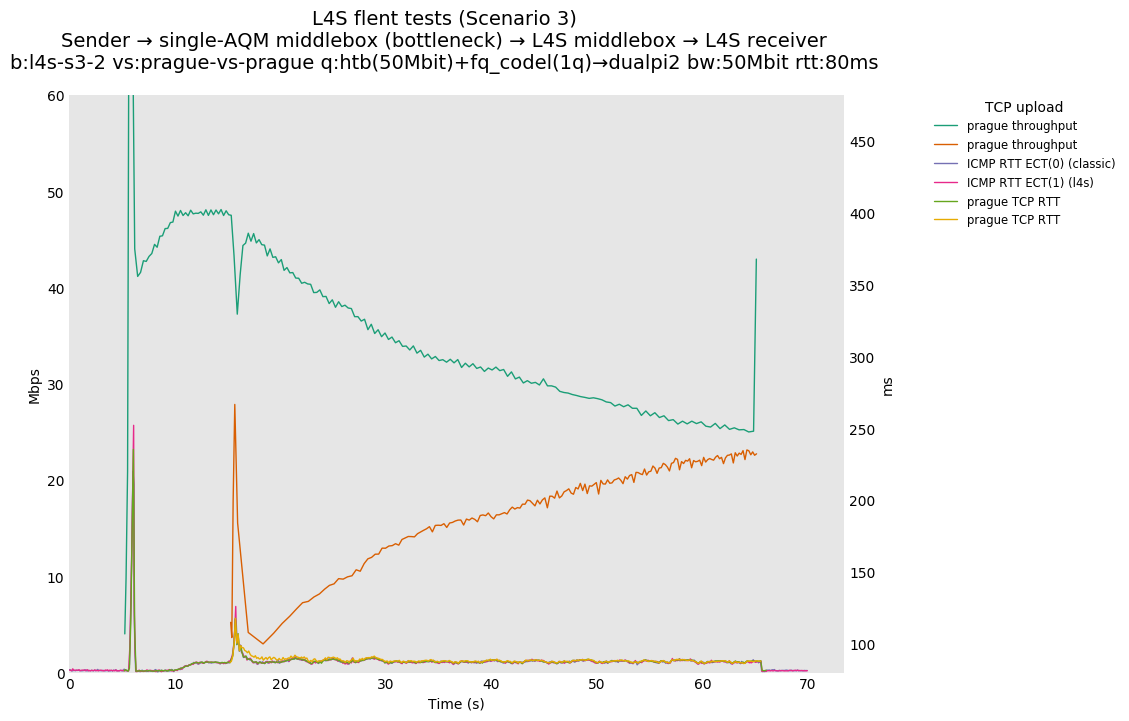
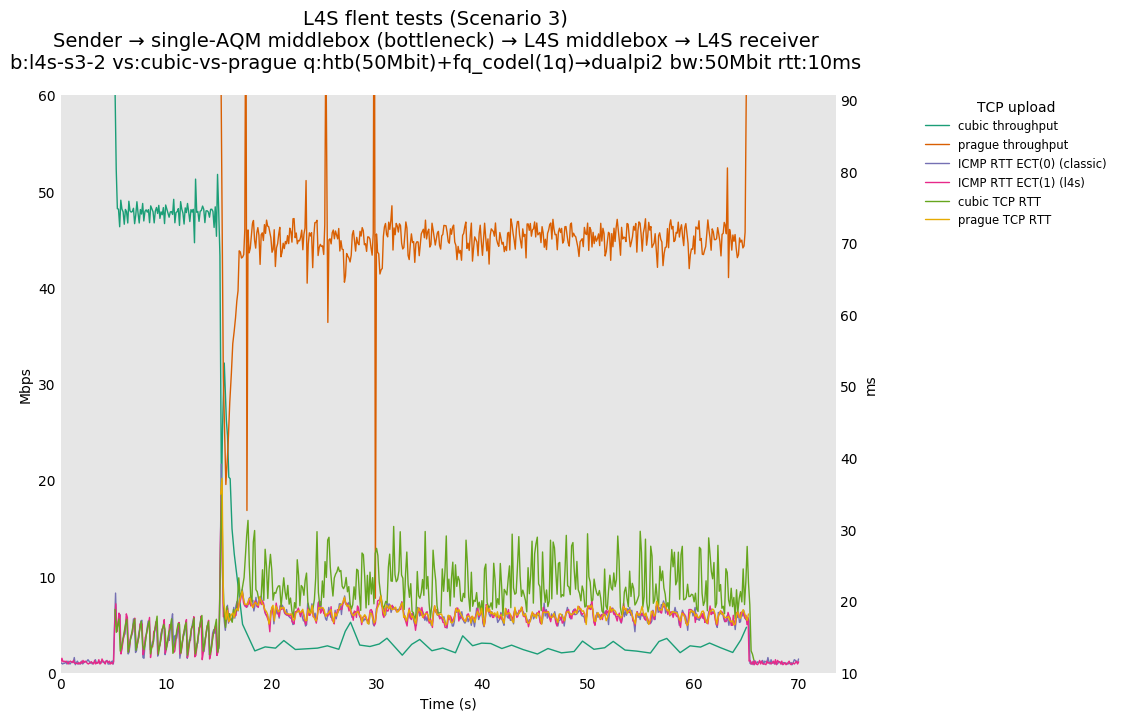
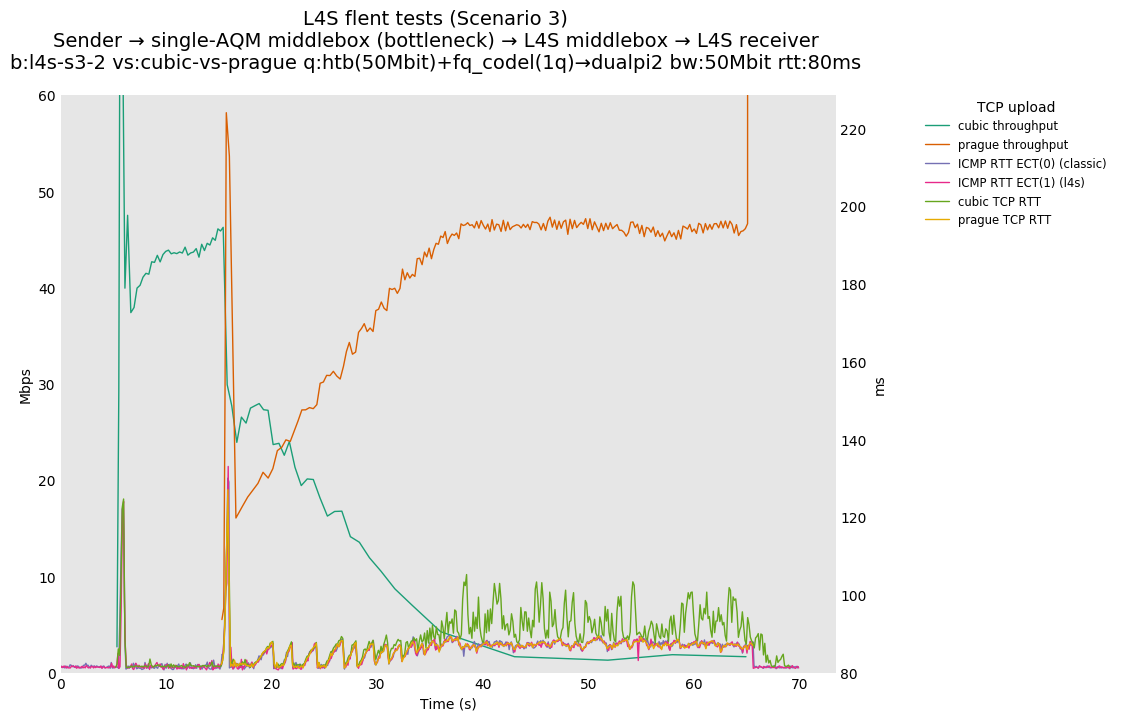
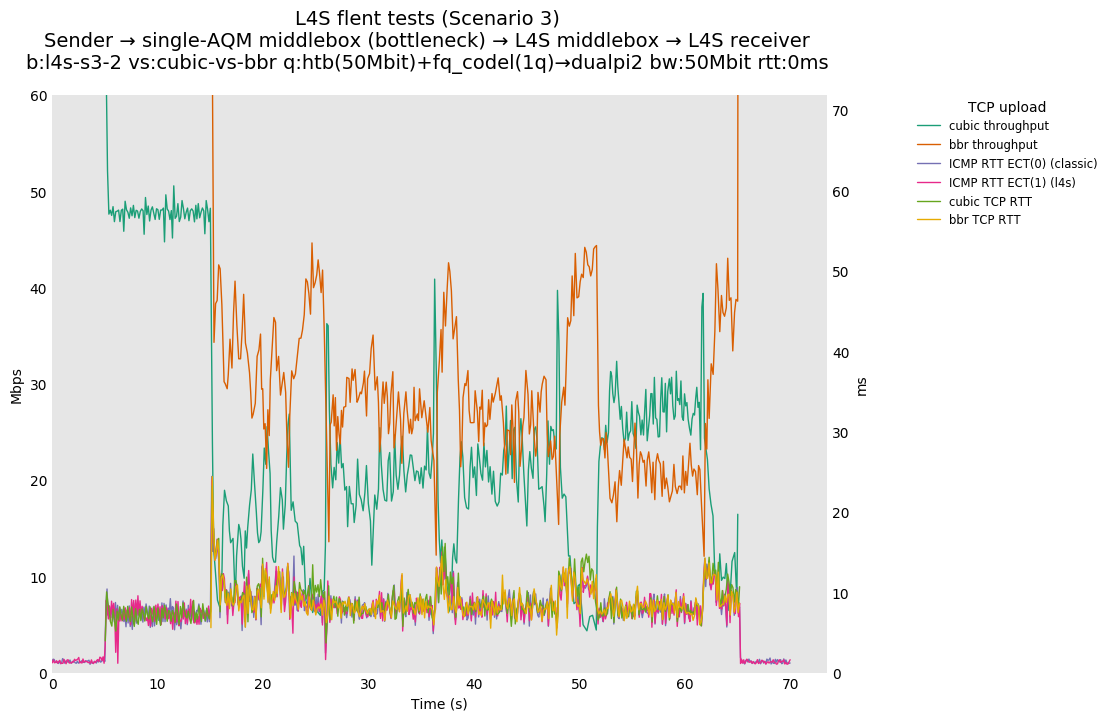
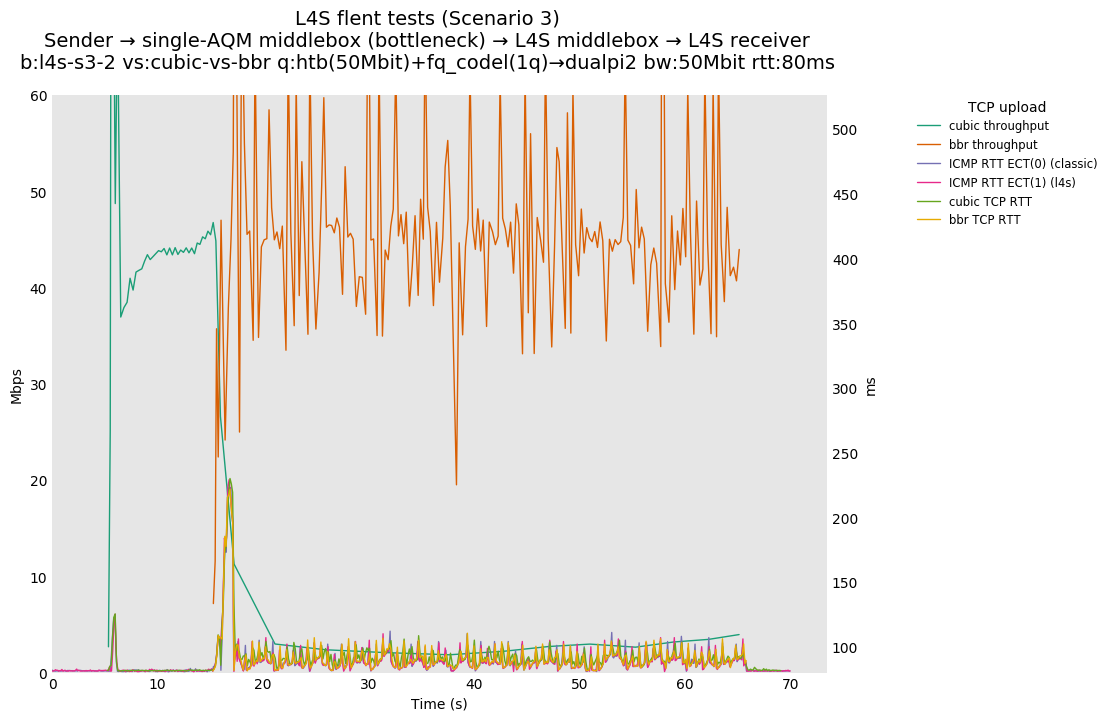
L4S: Sender → single-AQM middlebox (bottleneck) → L4S middlebox → L4S receiver
| 50Mb-0ms | 50Mb-10ms | 50Mb-80ms |
|---|---|---|
| cubic | cubic | cubic |
| bbr | bbr | bbr |
| prague | prague | prague |
| prague-vs-prague | prague-vs-prague | prague-vs-prague |
| cubic-vs-prague | cubic-vs-prague | cubic-vs-prague |
| cubic-vs-bbr | cubic-vs-bbr | cubic-vs-bbr |
As all flows share the same bottleneck/queue, we see that the lower response to the CoDel drops/marks from Prague/bbr causes cubic to be pushed away (or reno if facing cubic as the latter uses ABE).
This explores what happens if an adversary tries to game the system by forcing ECT(1) on all packets.
L4S: Sender → ECT(1) mangler → L4S middlebox (bottleneck) → L4S receiver
As reported earlier, responsie non-L4S flows will be pushed away by the L4S ones (see either P.Heist data or the complete dataset on the top of this document).
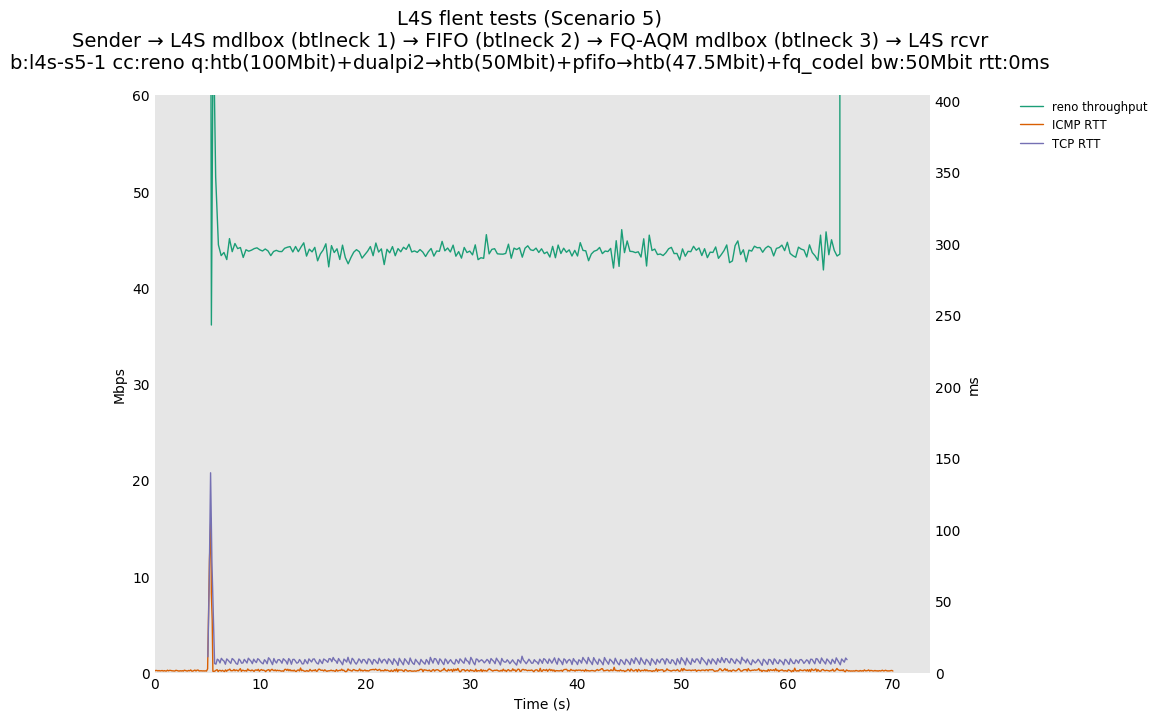
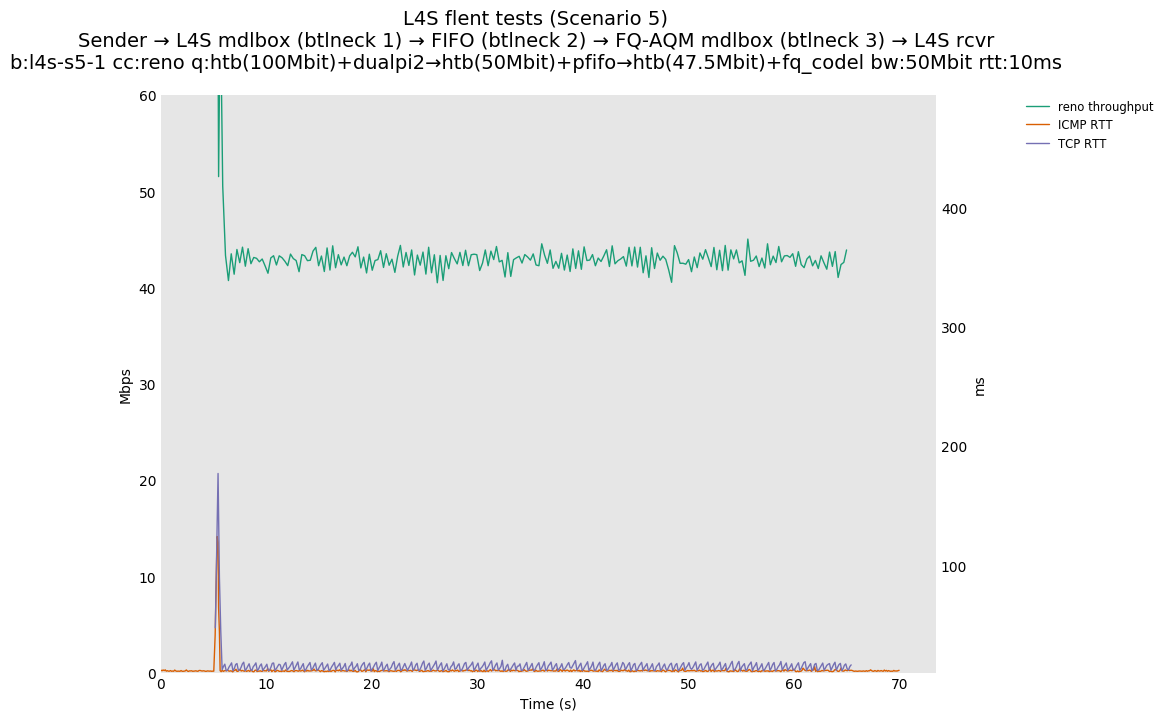
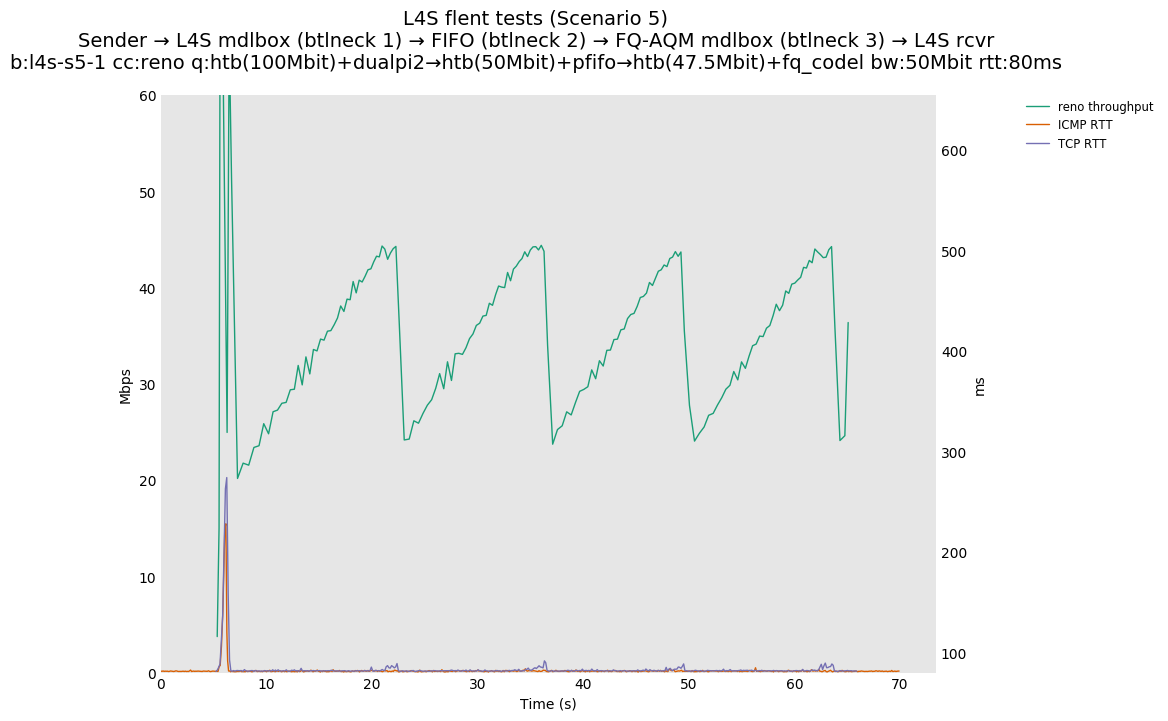
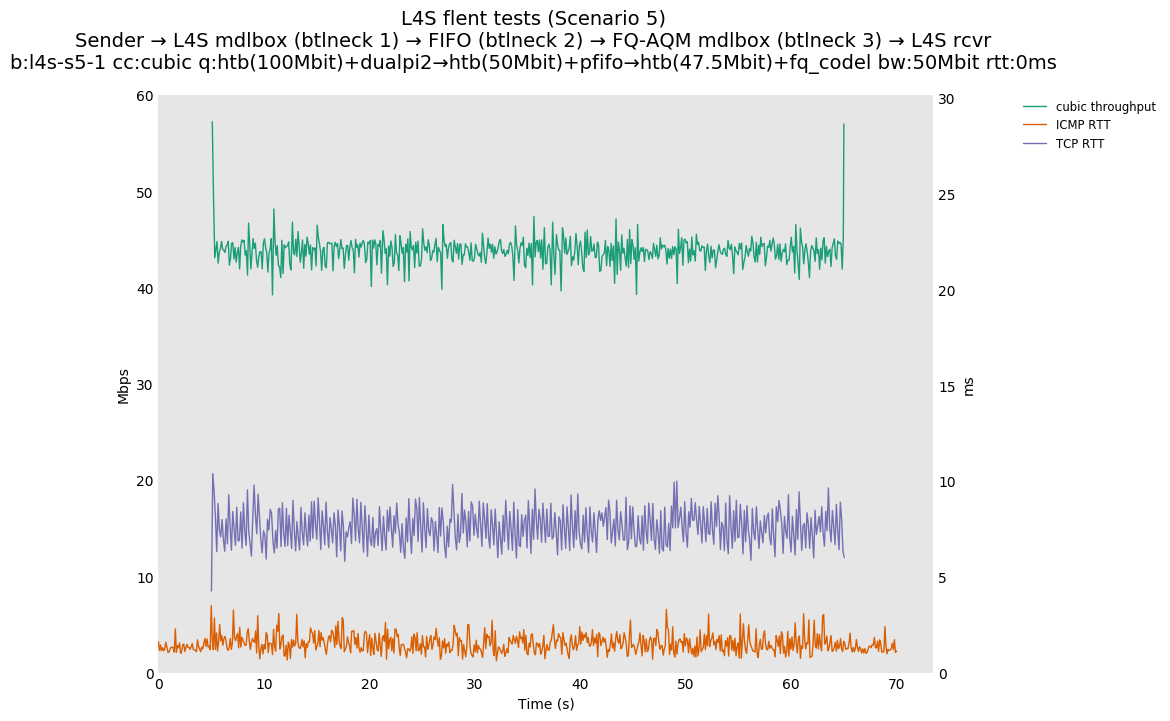
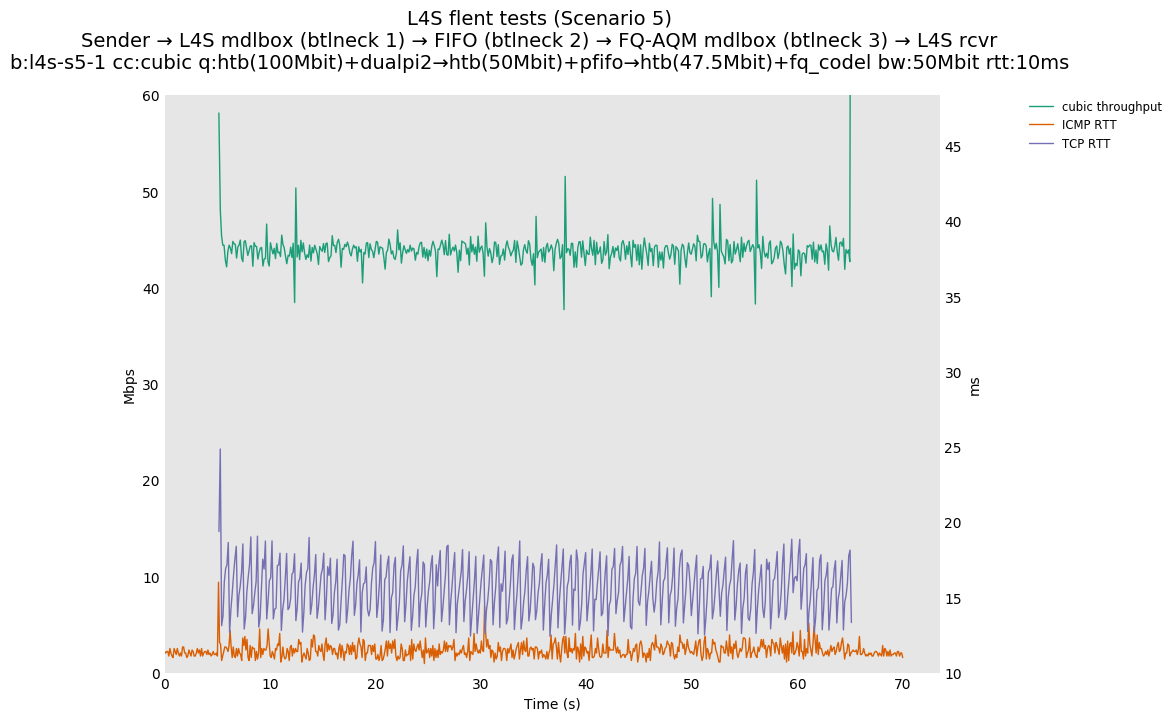
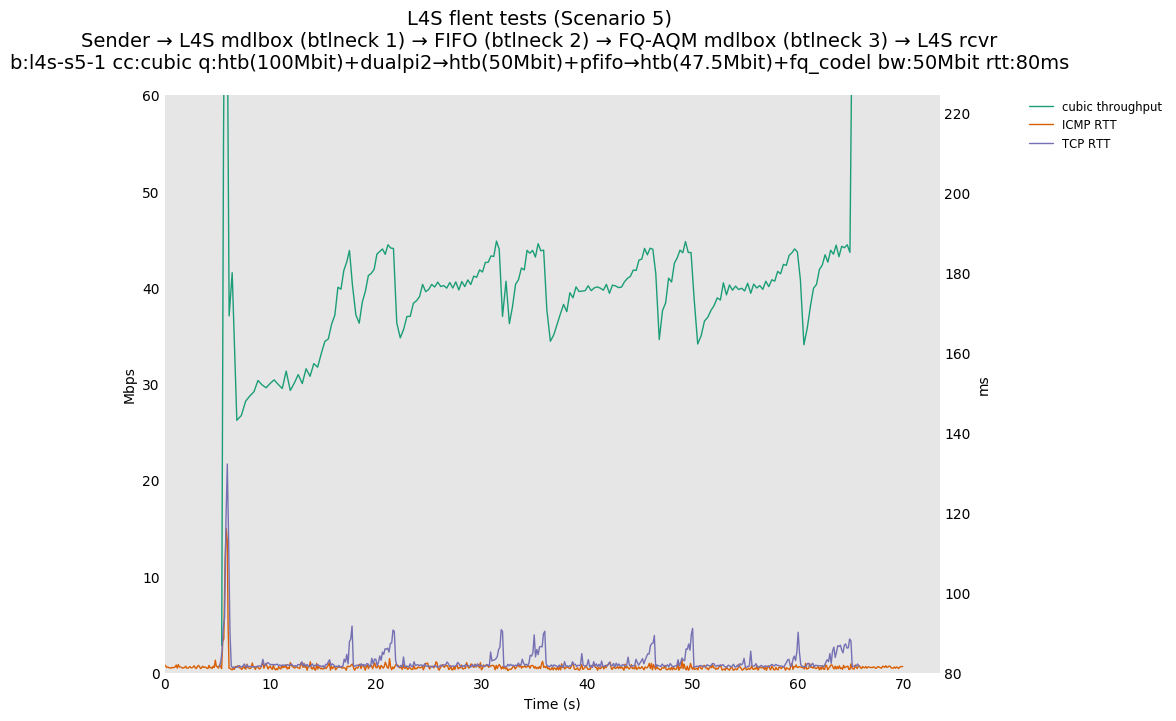
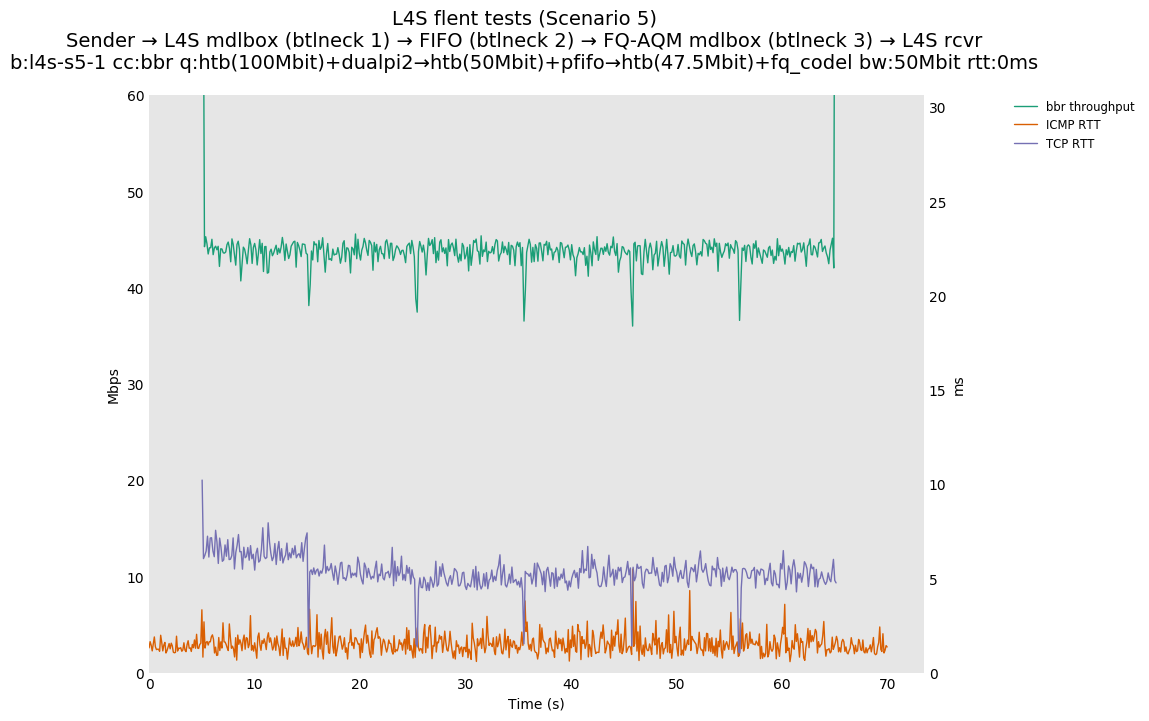
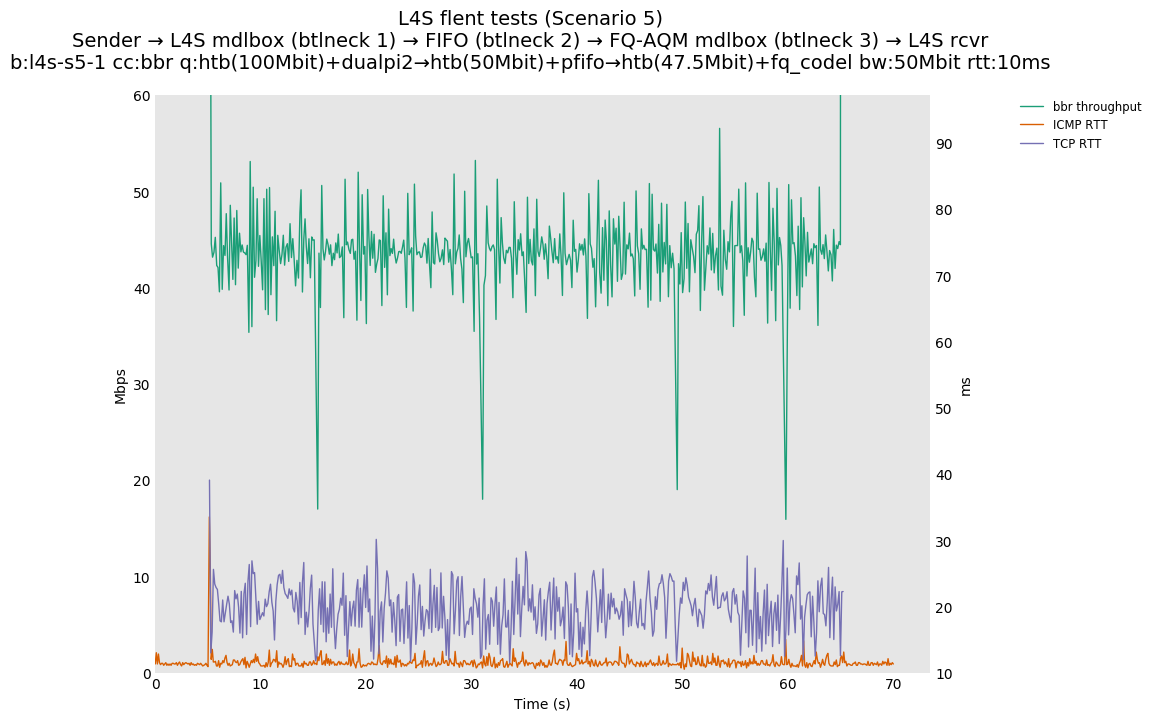
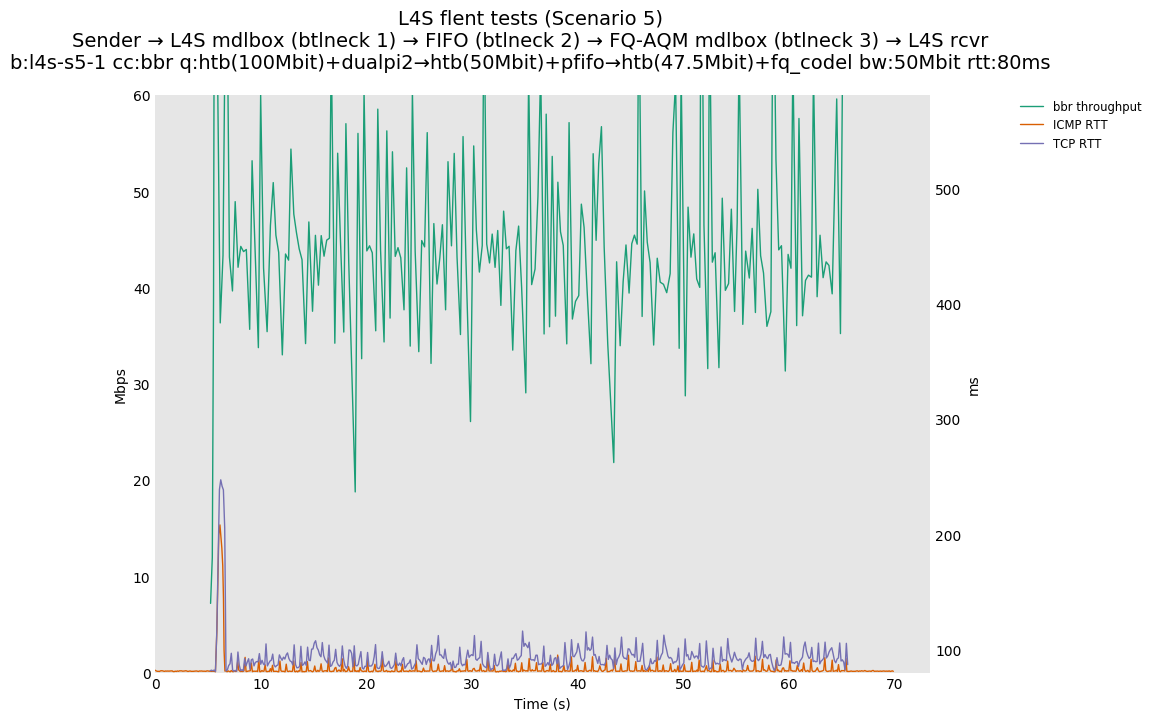
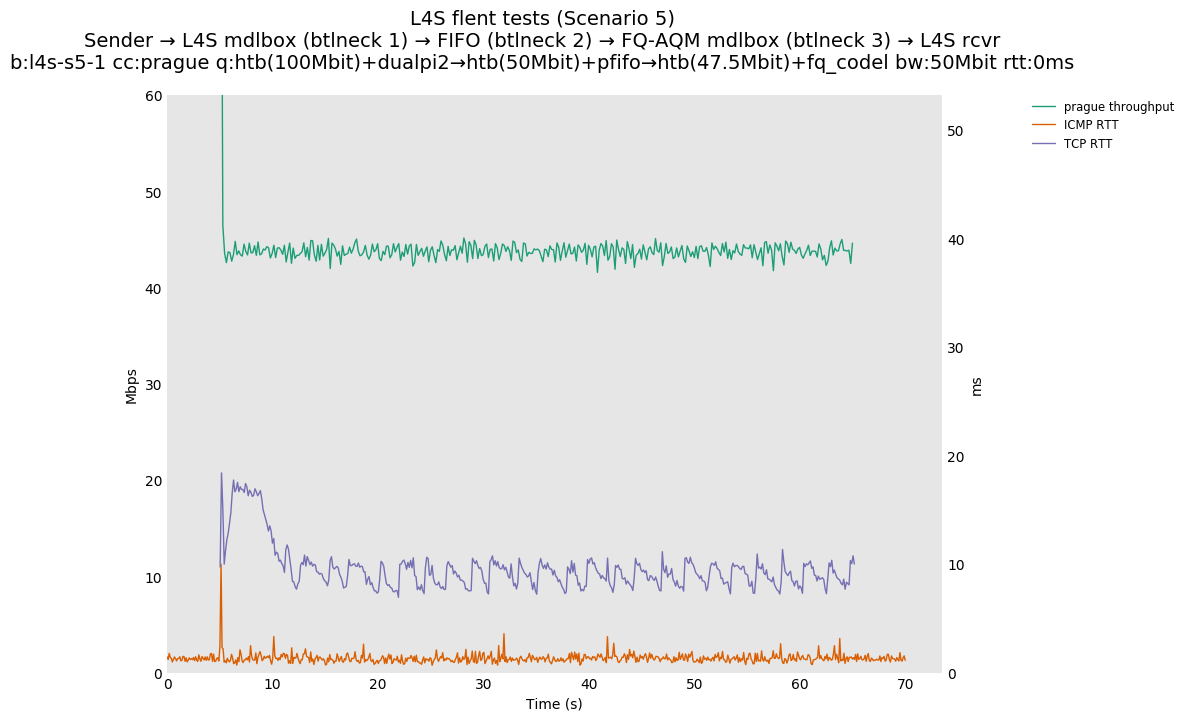
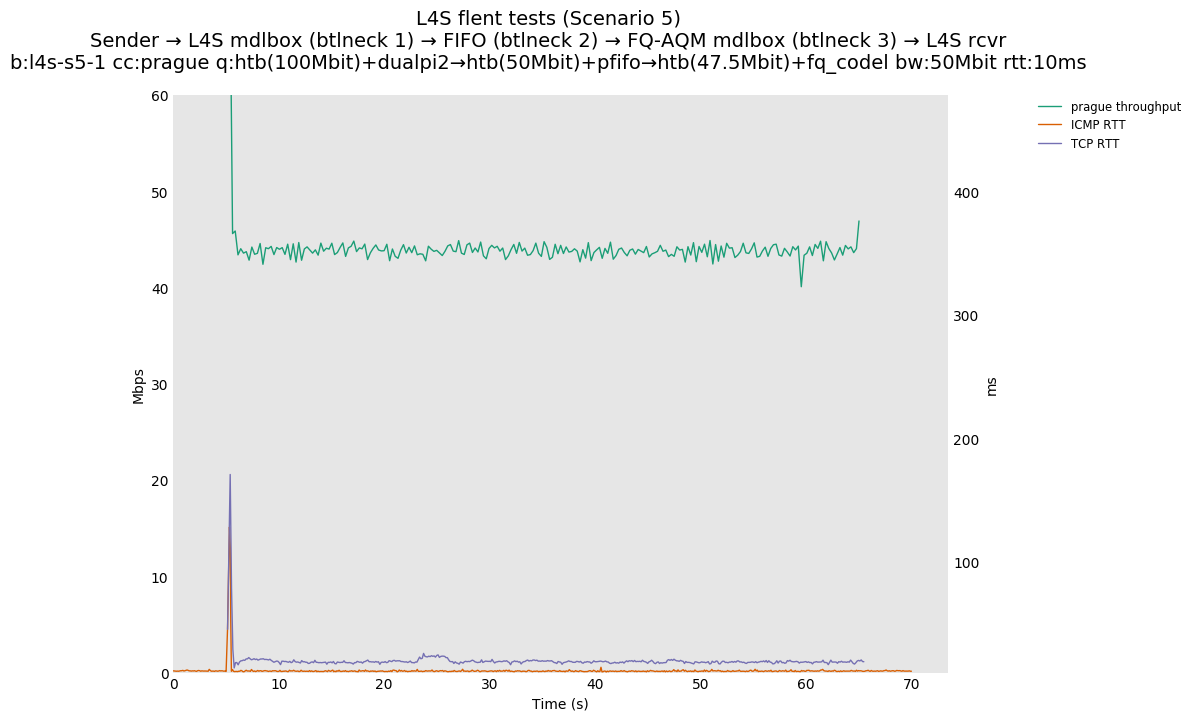
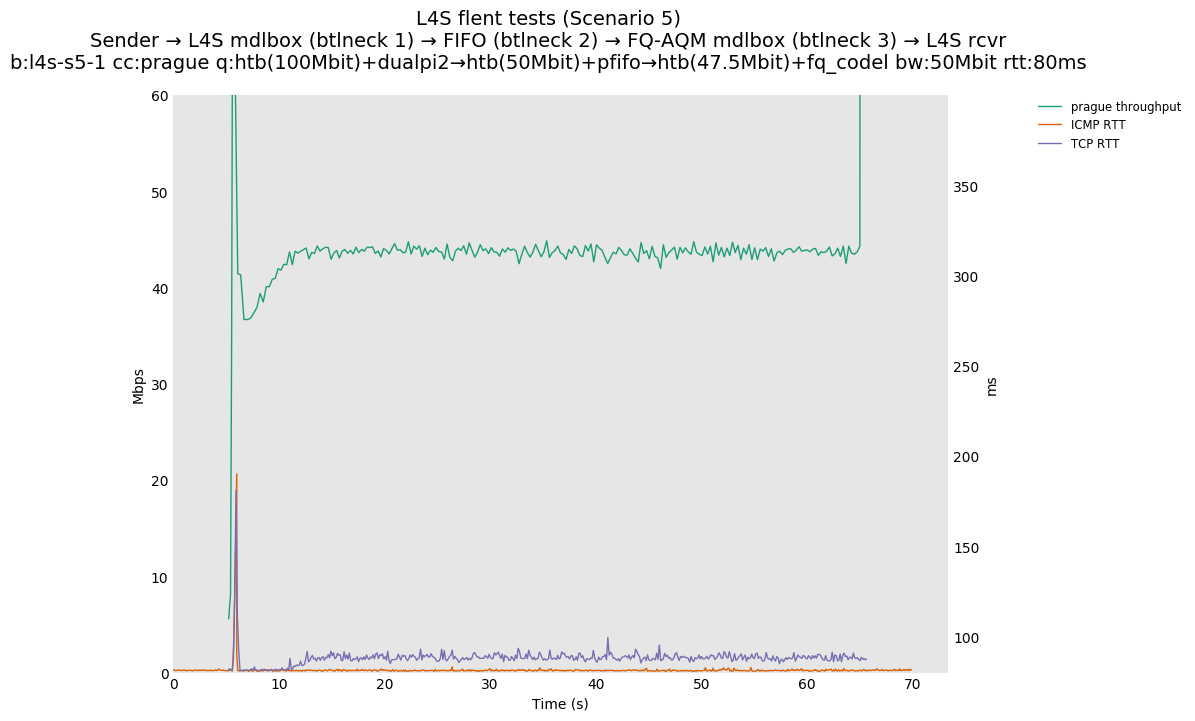
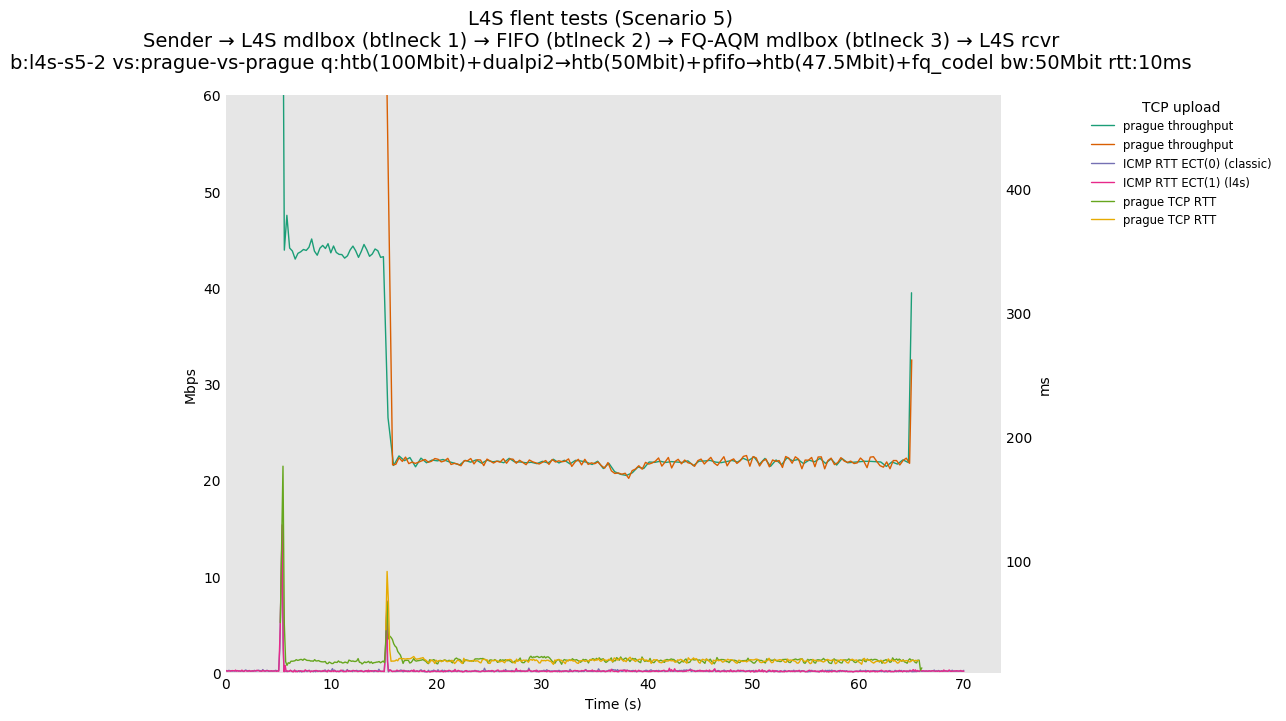
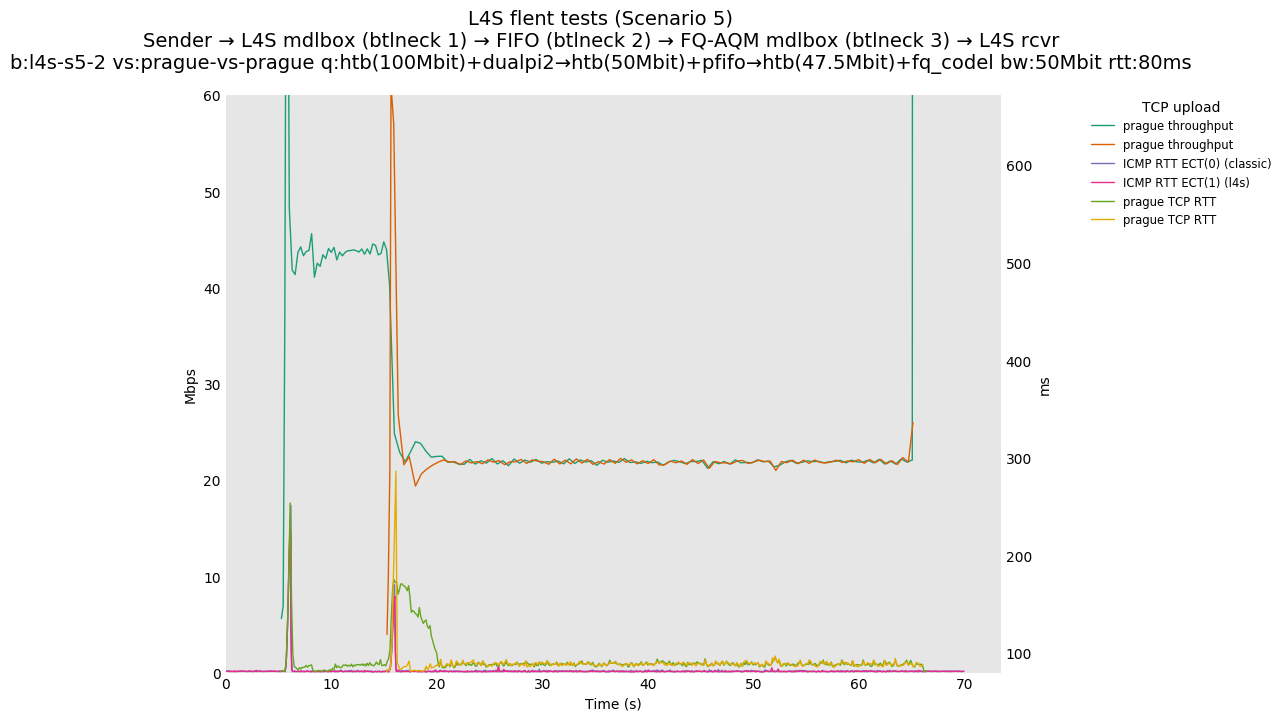
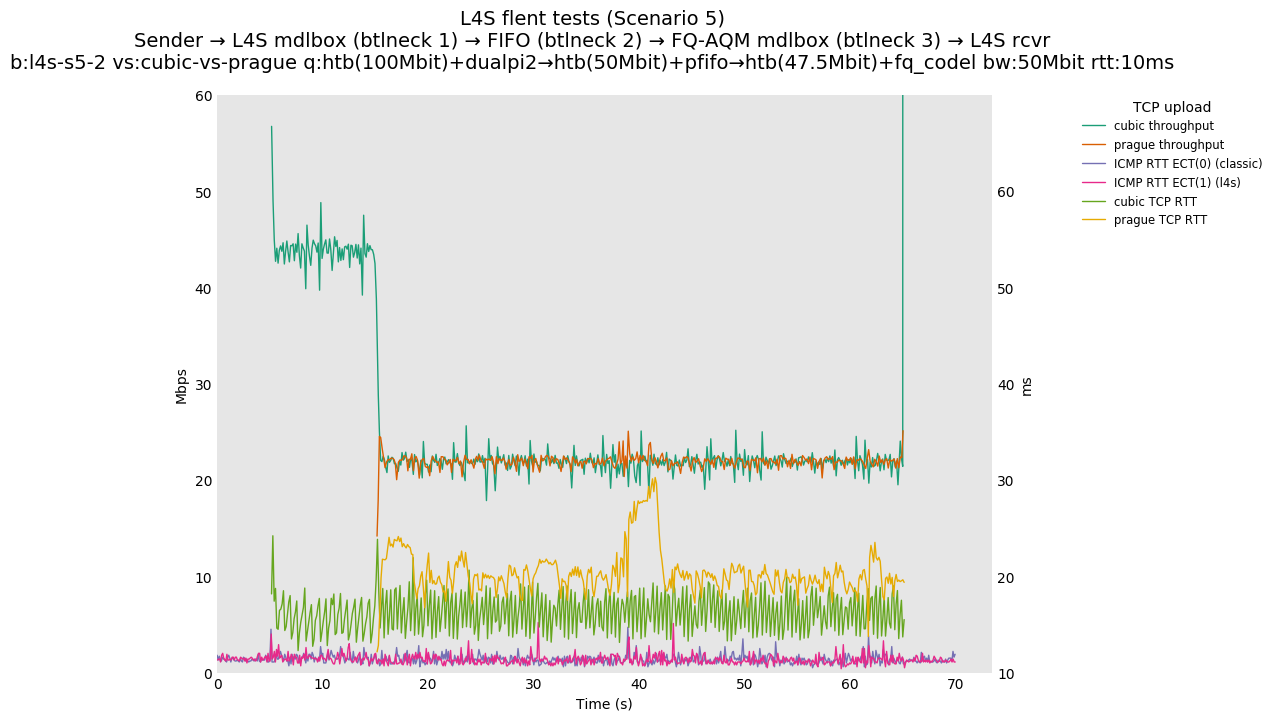
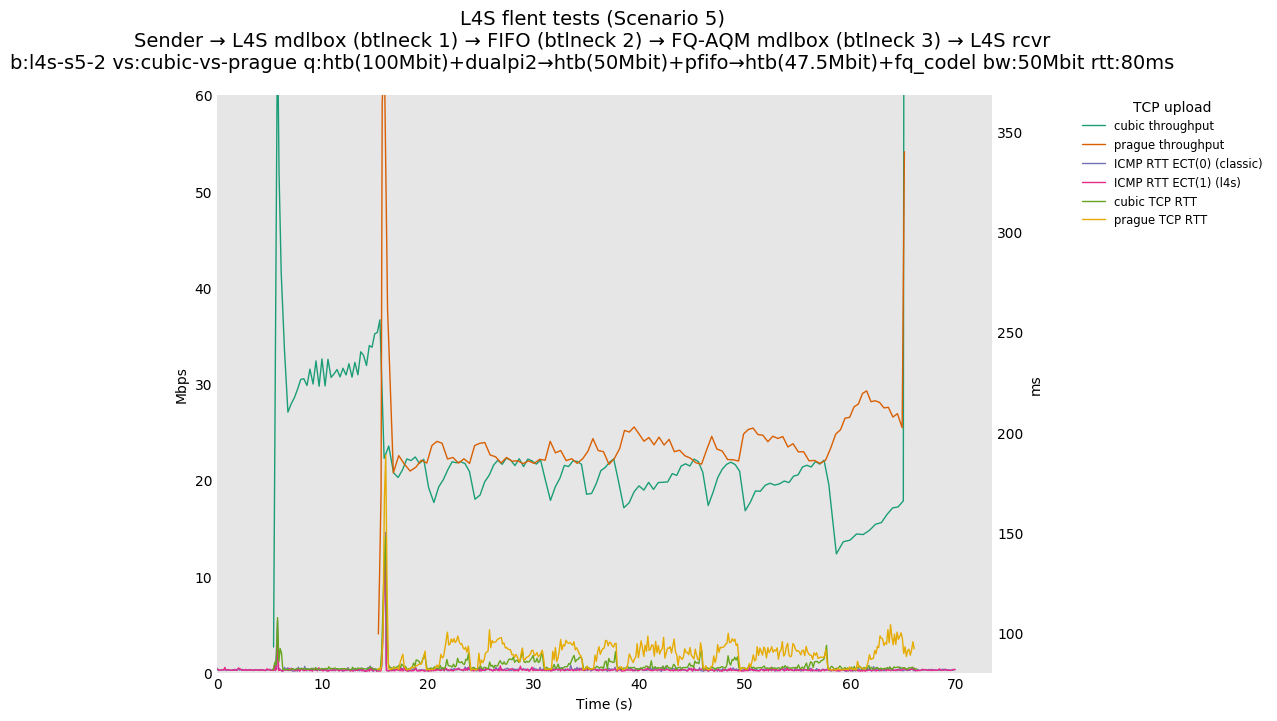
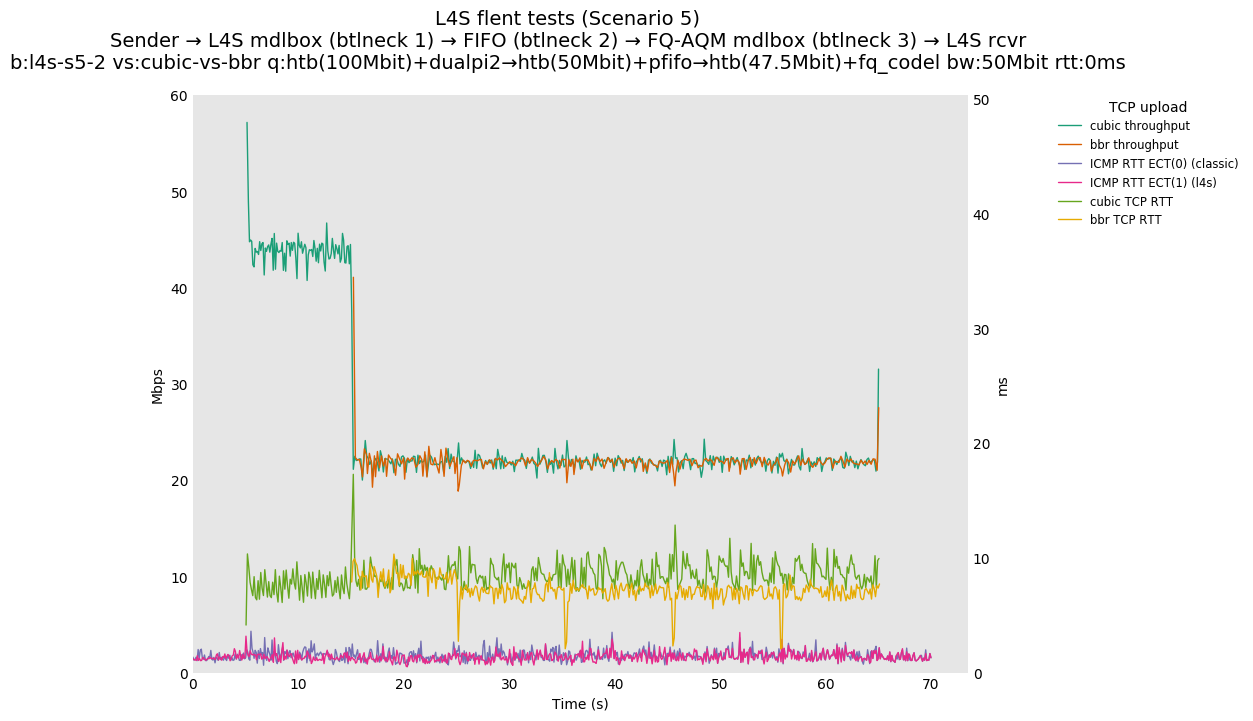
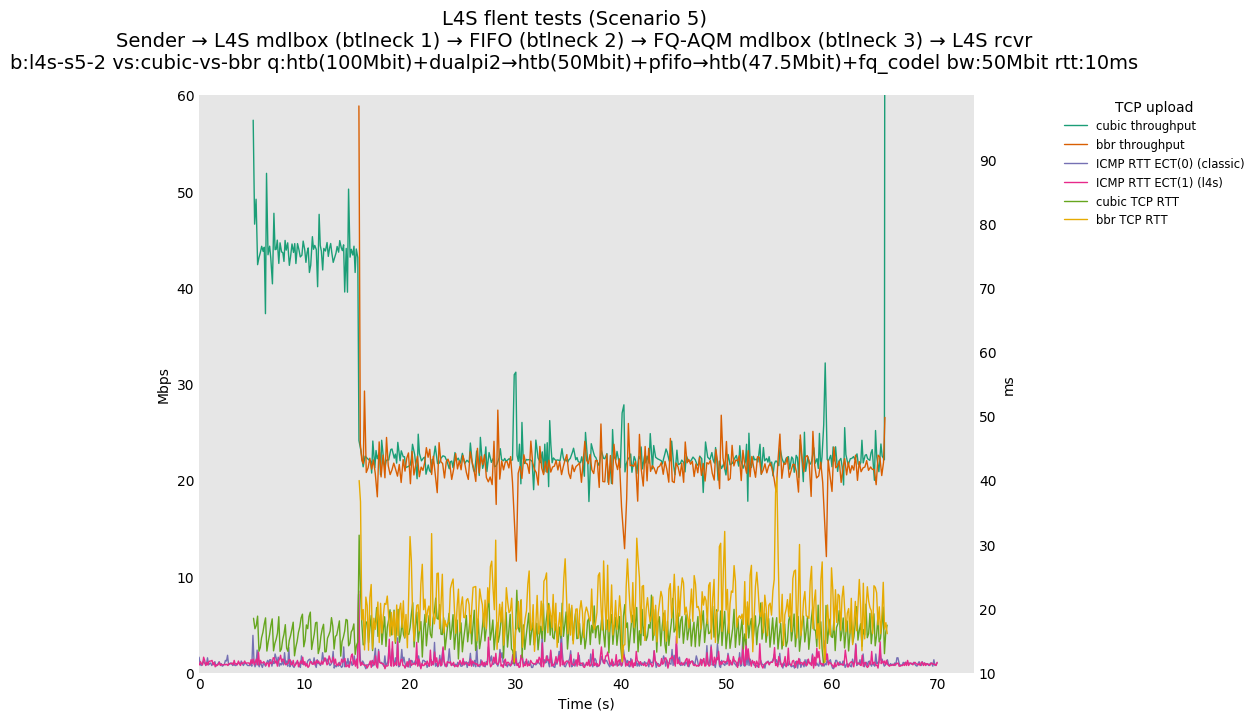
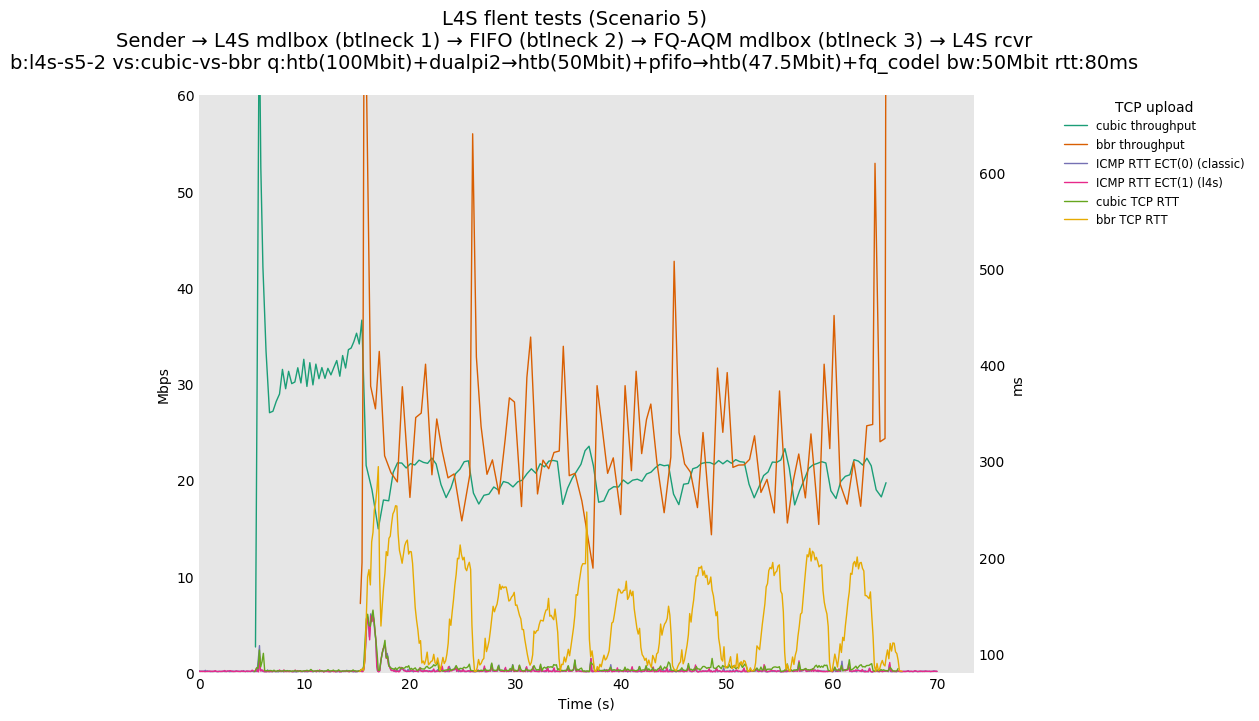
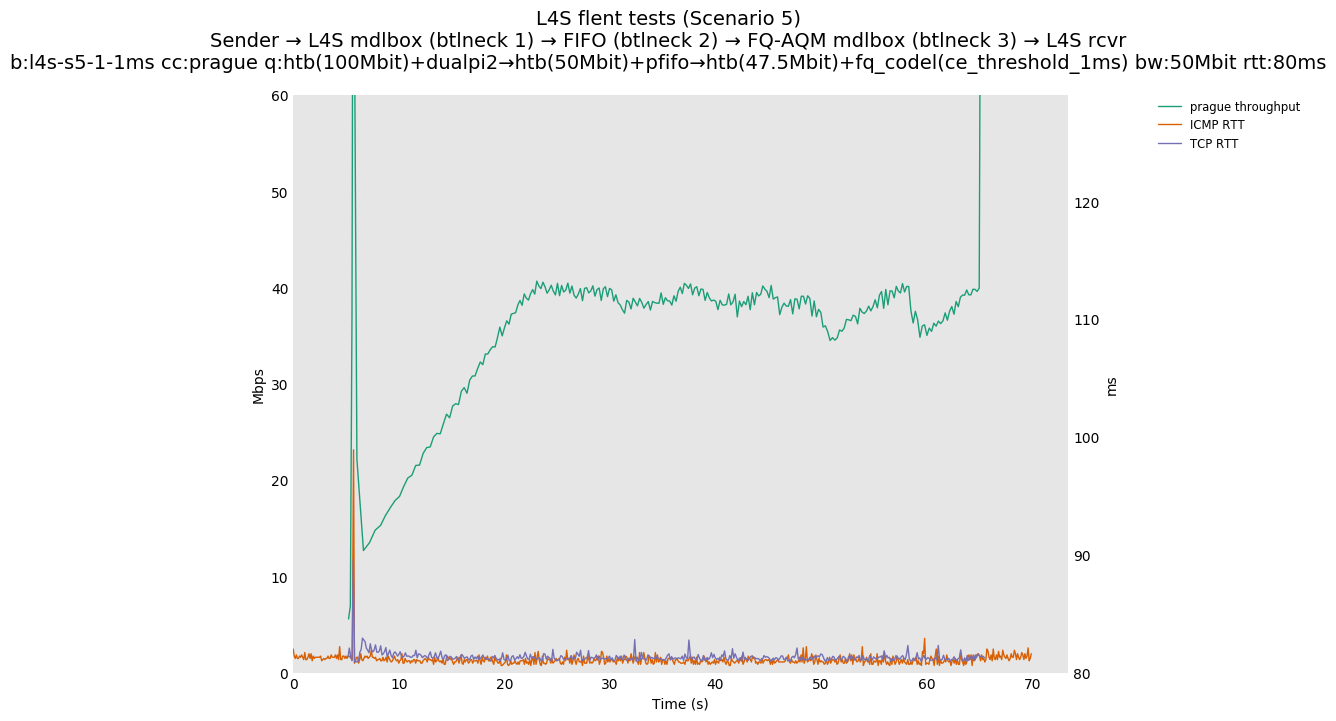
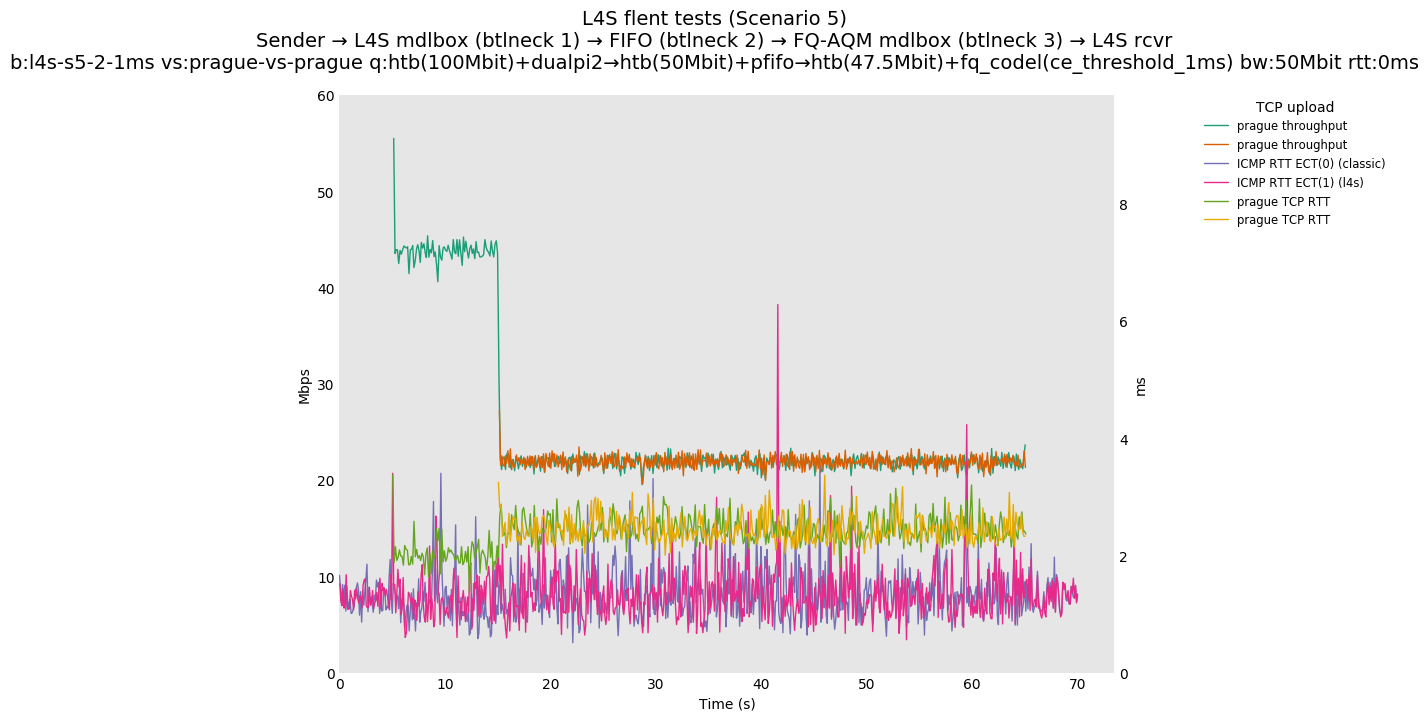
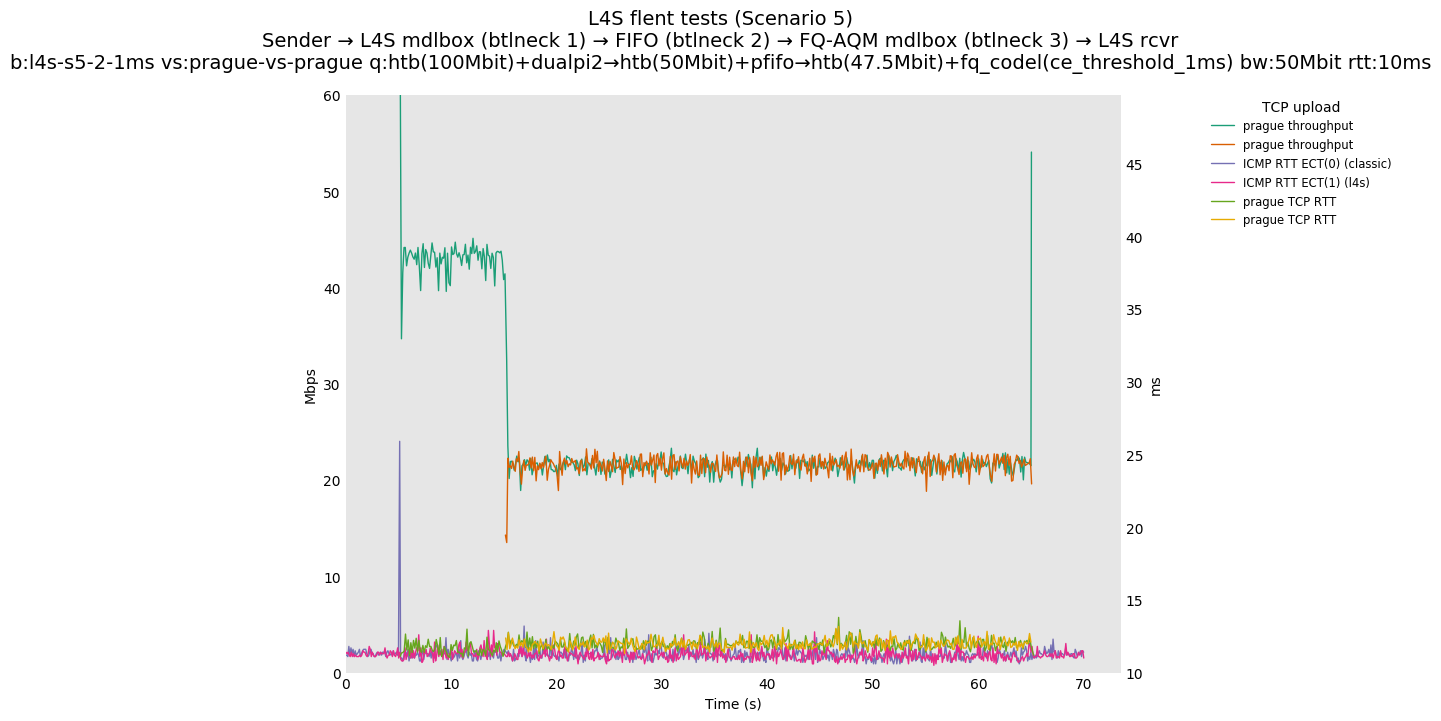
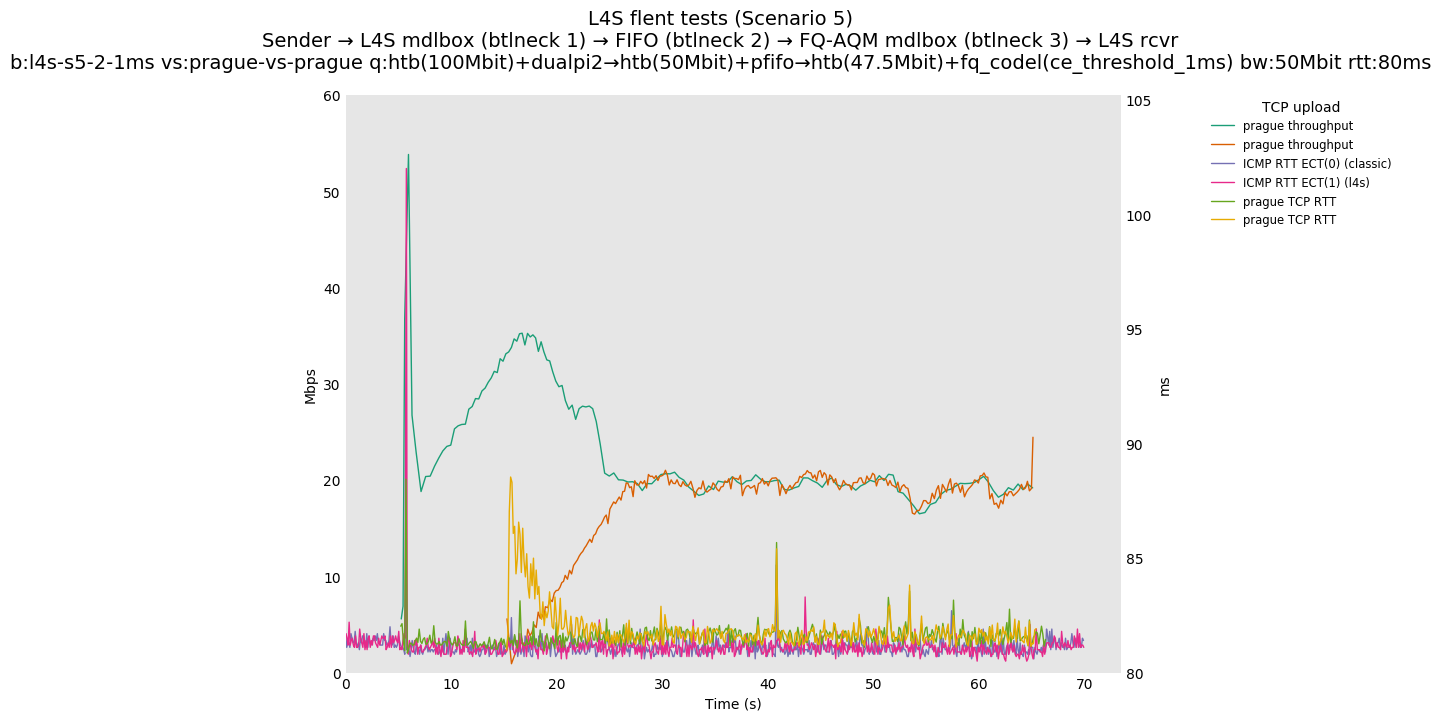
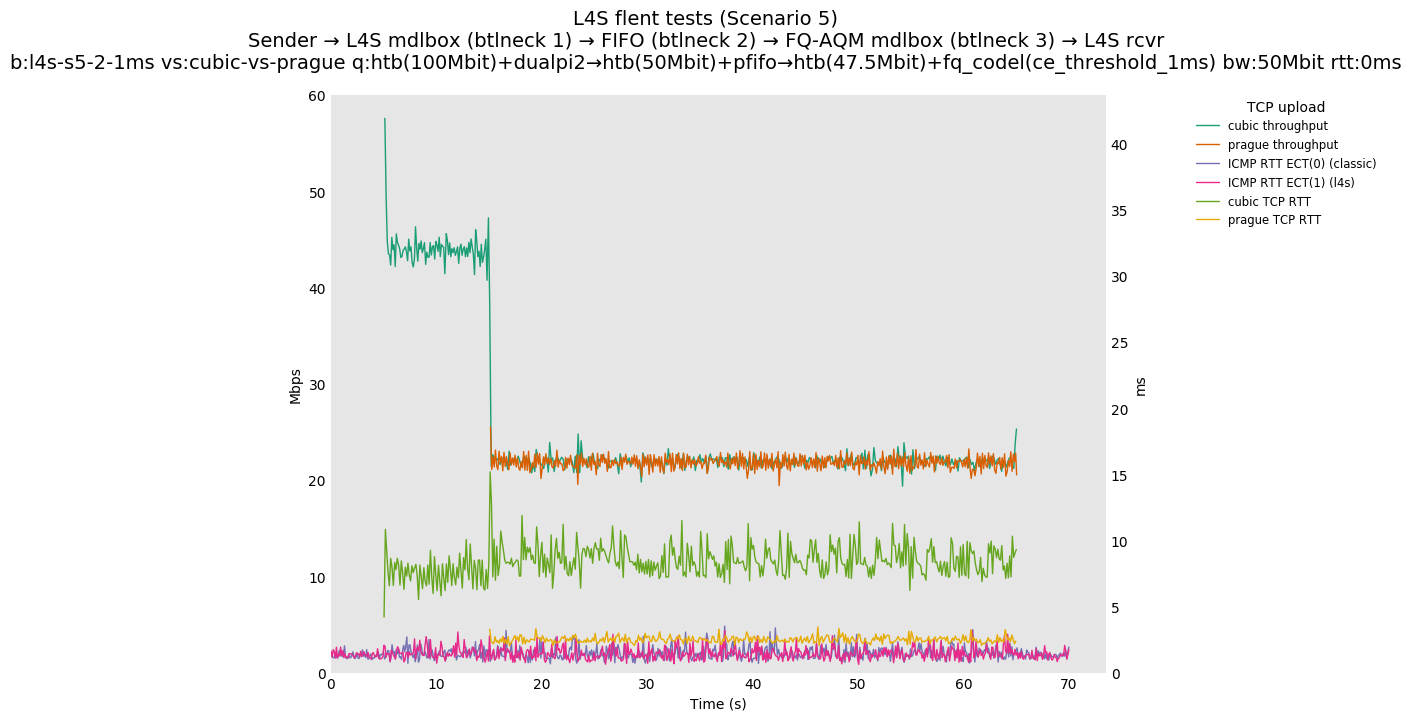
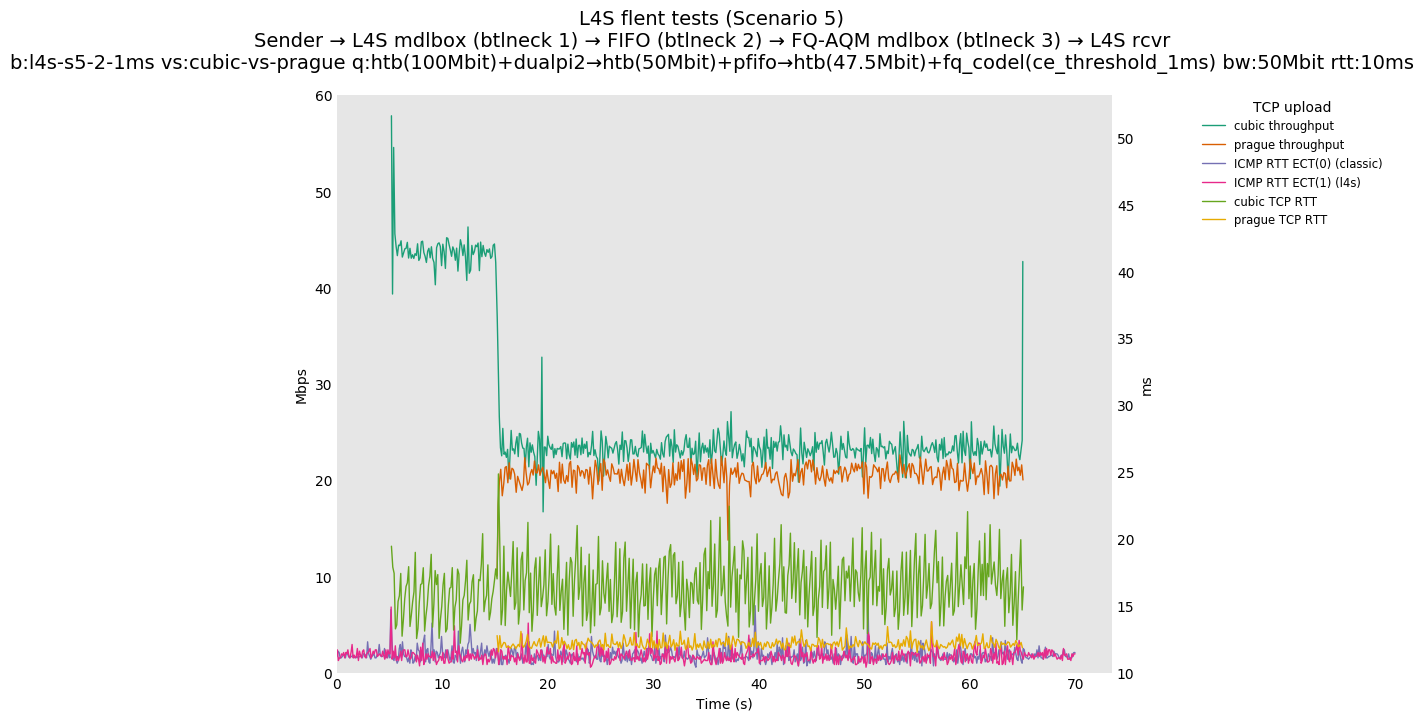
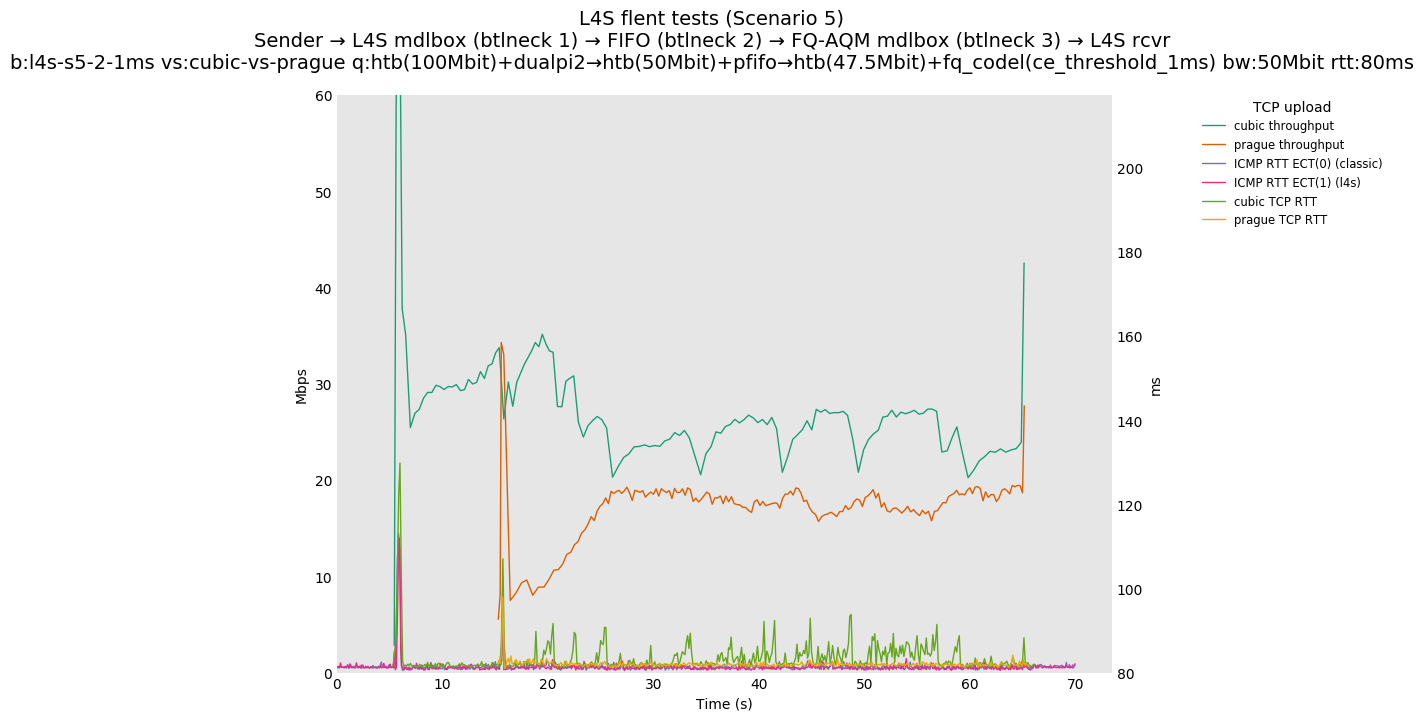
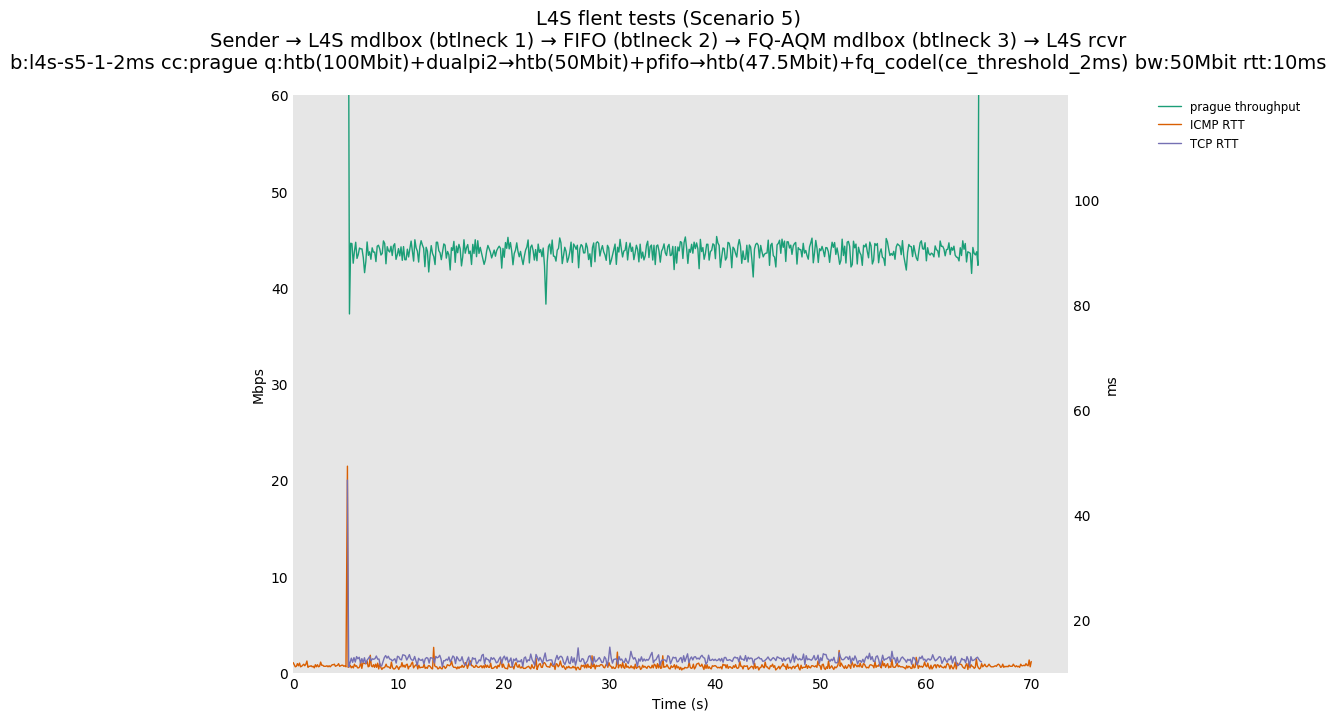
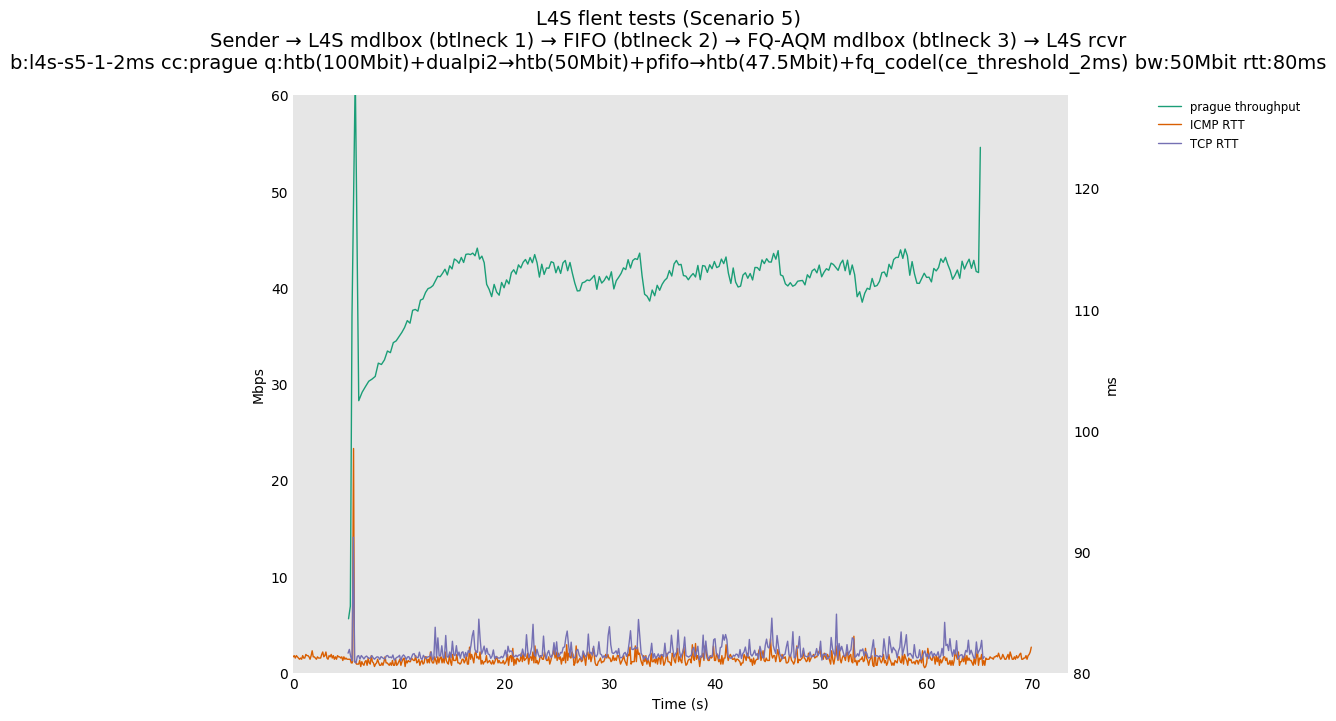
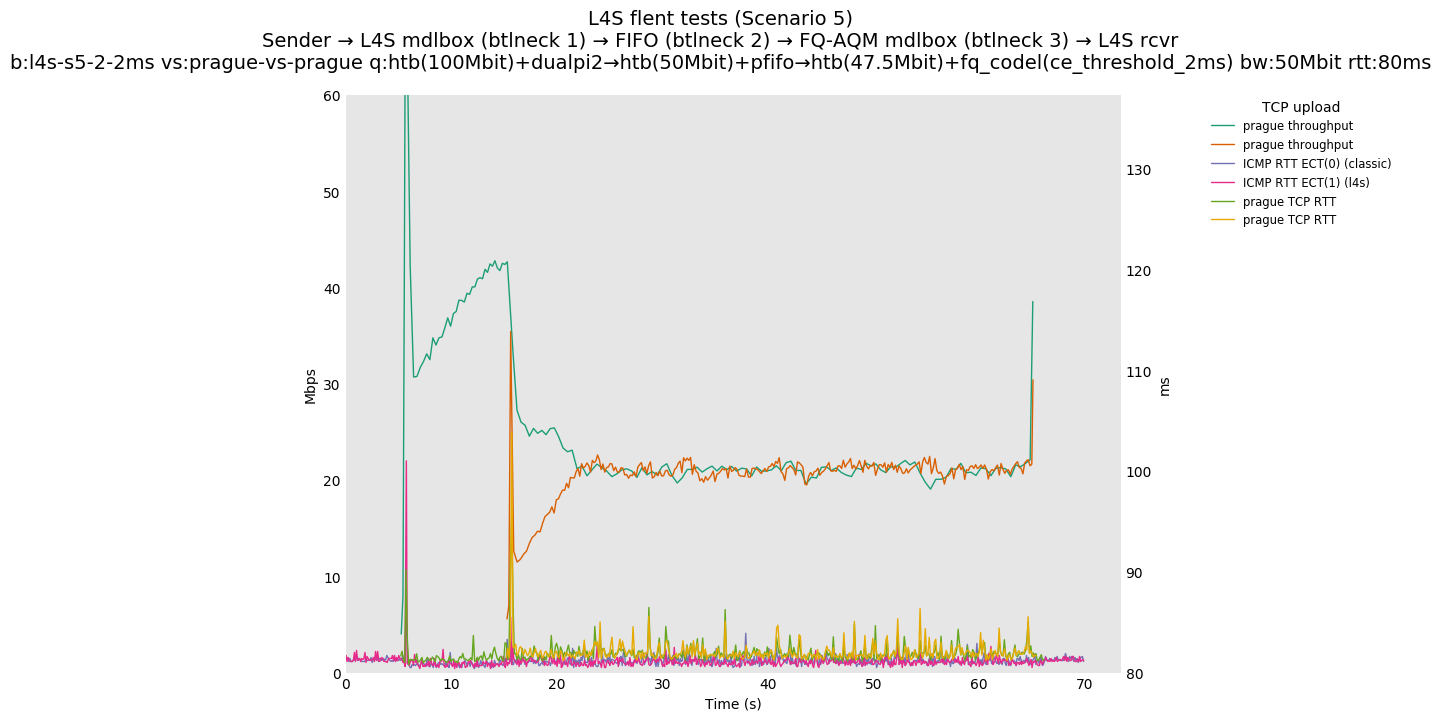
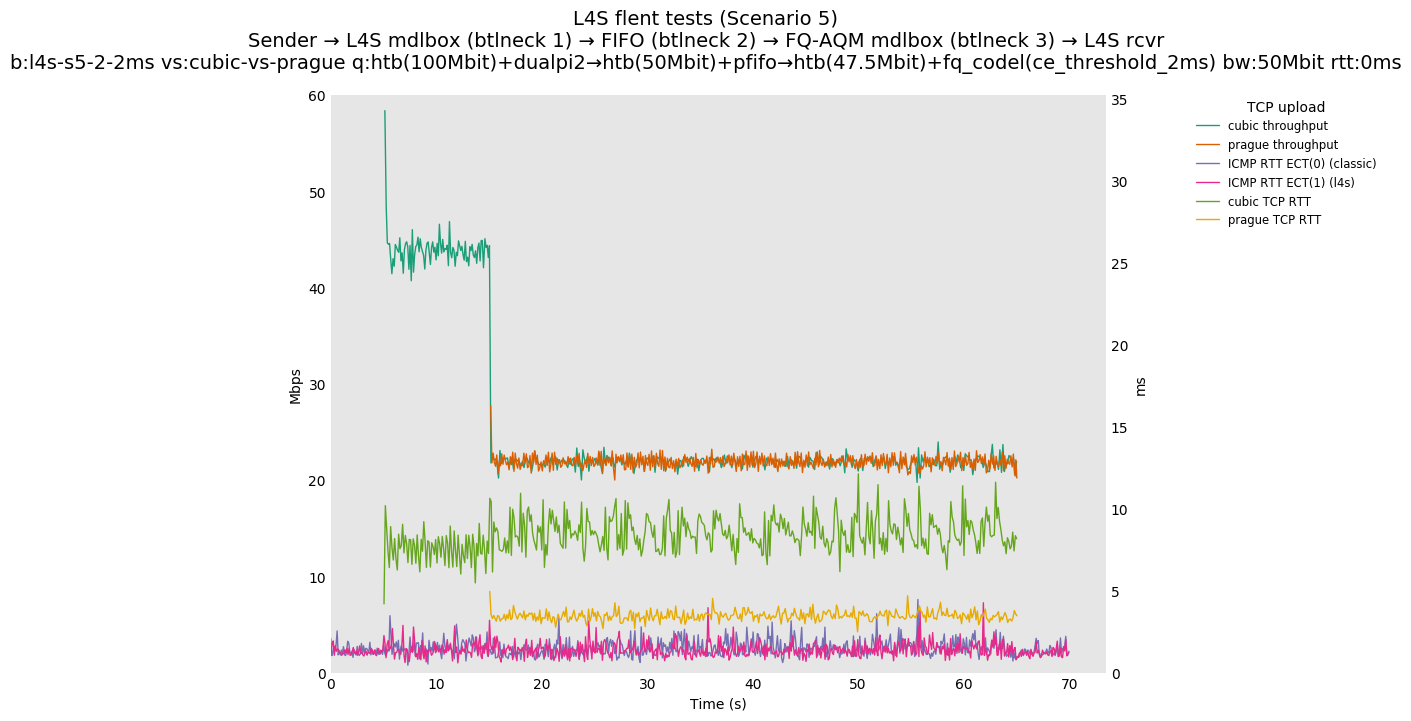
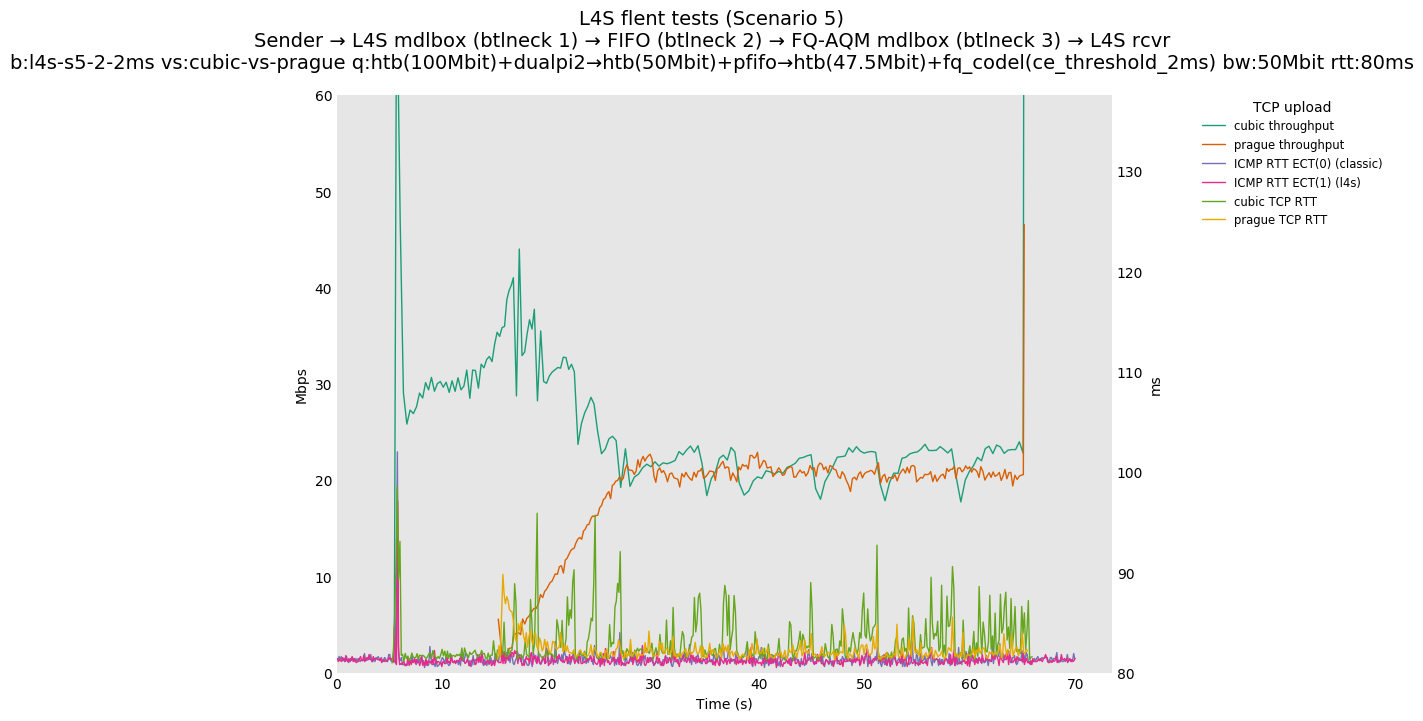
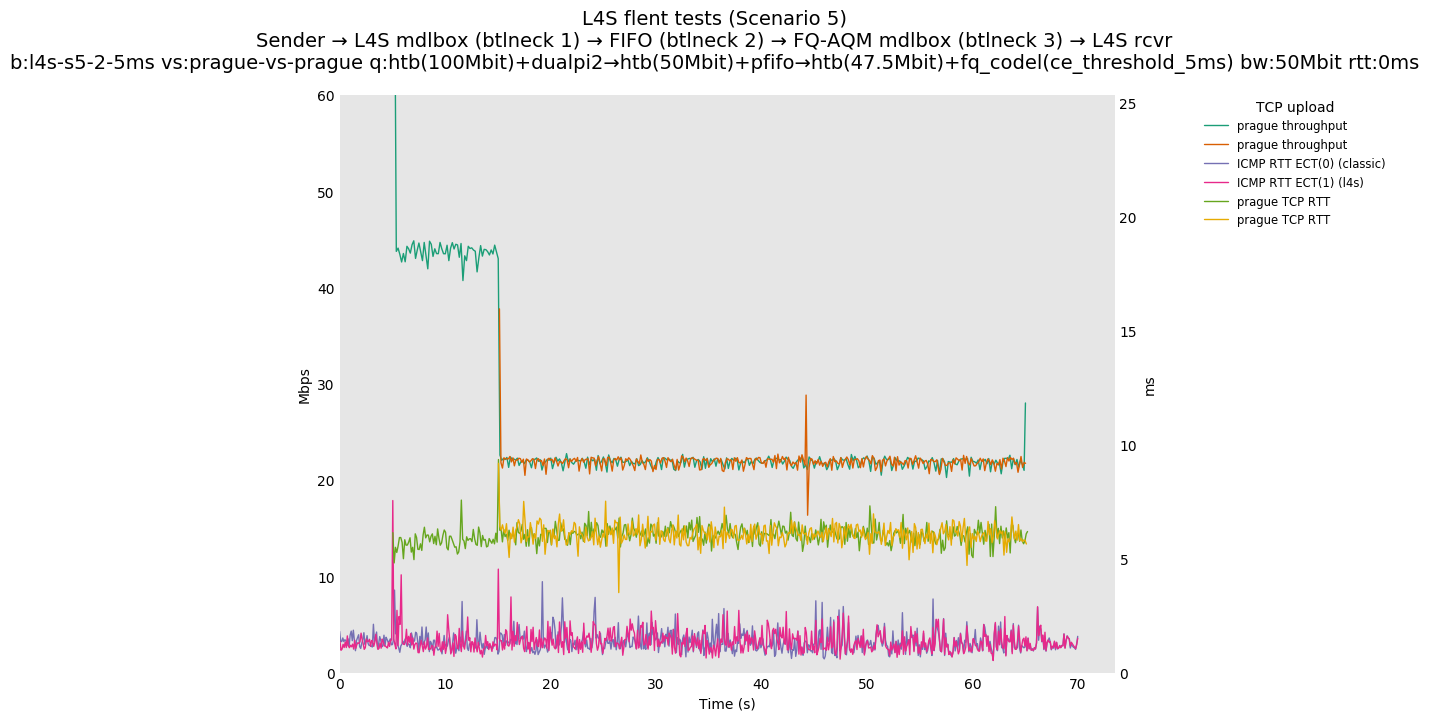
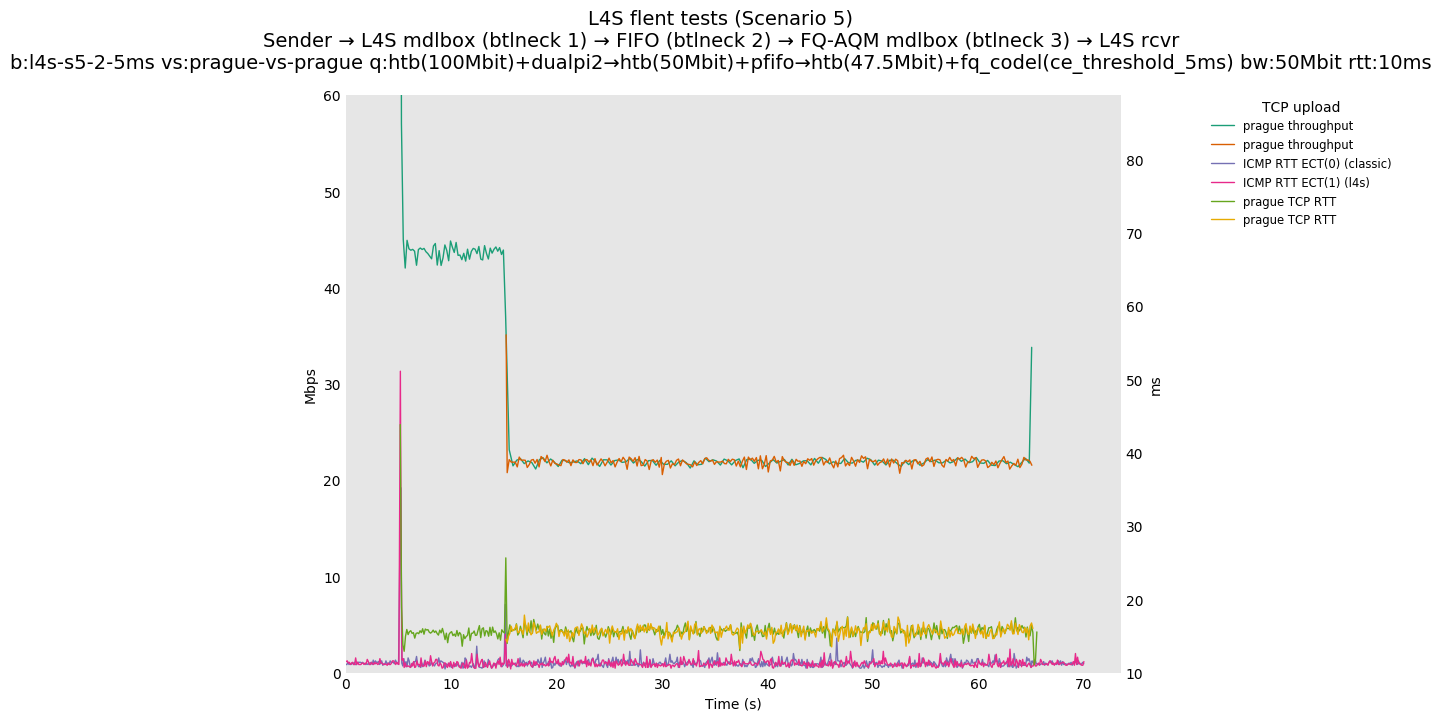
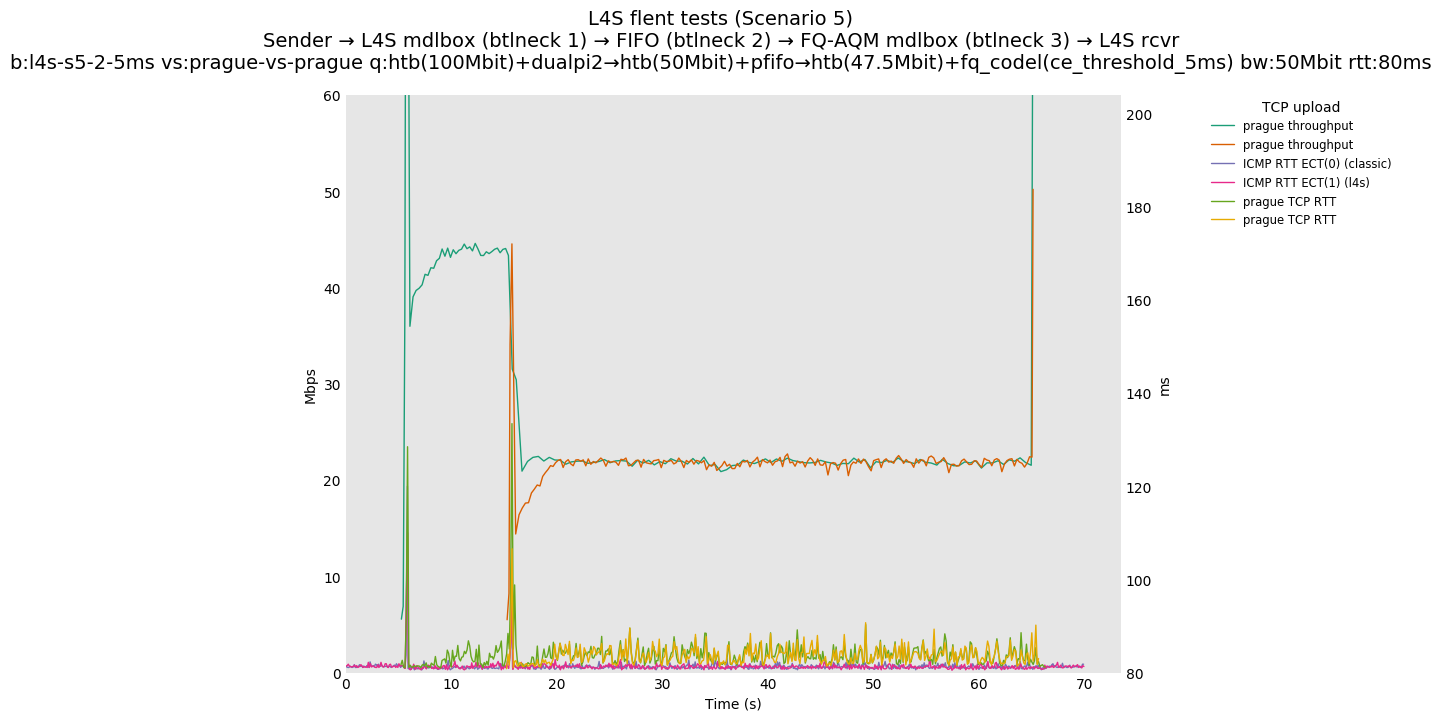
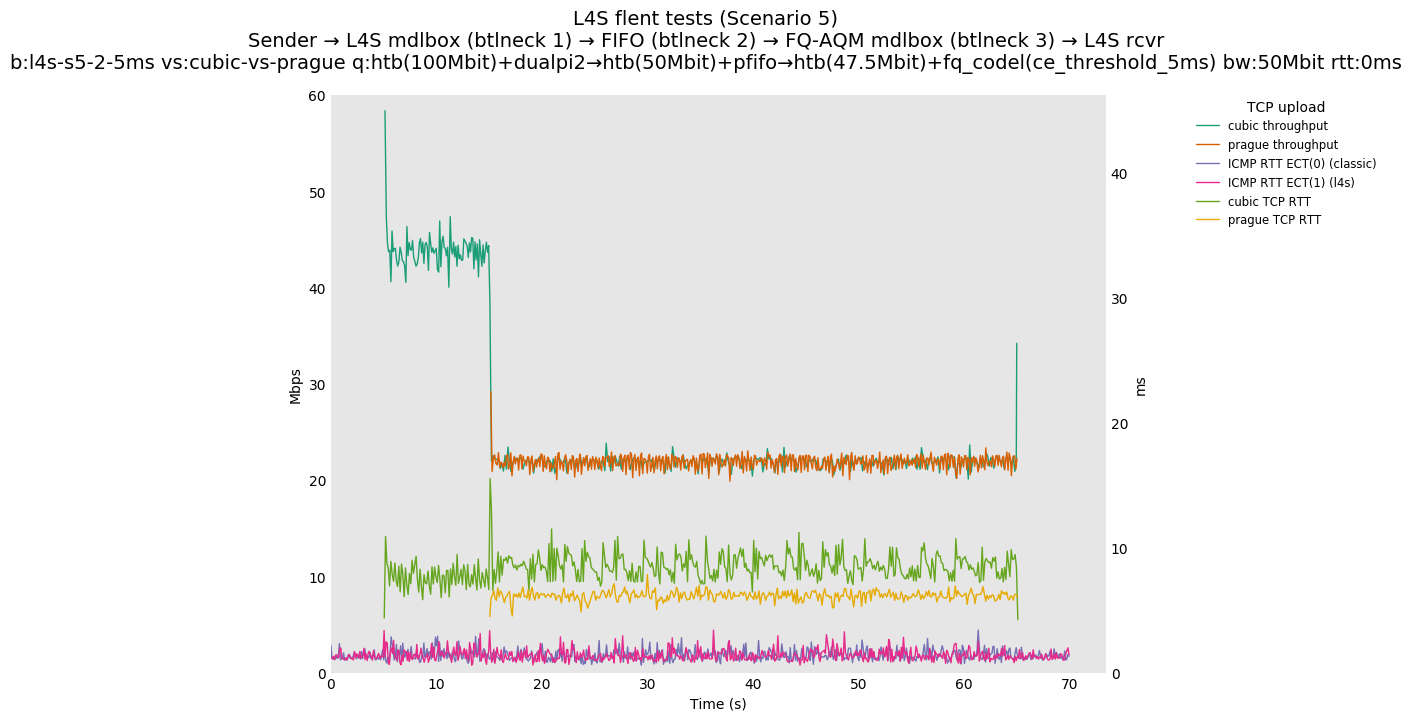
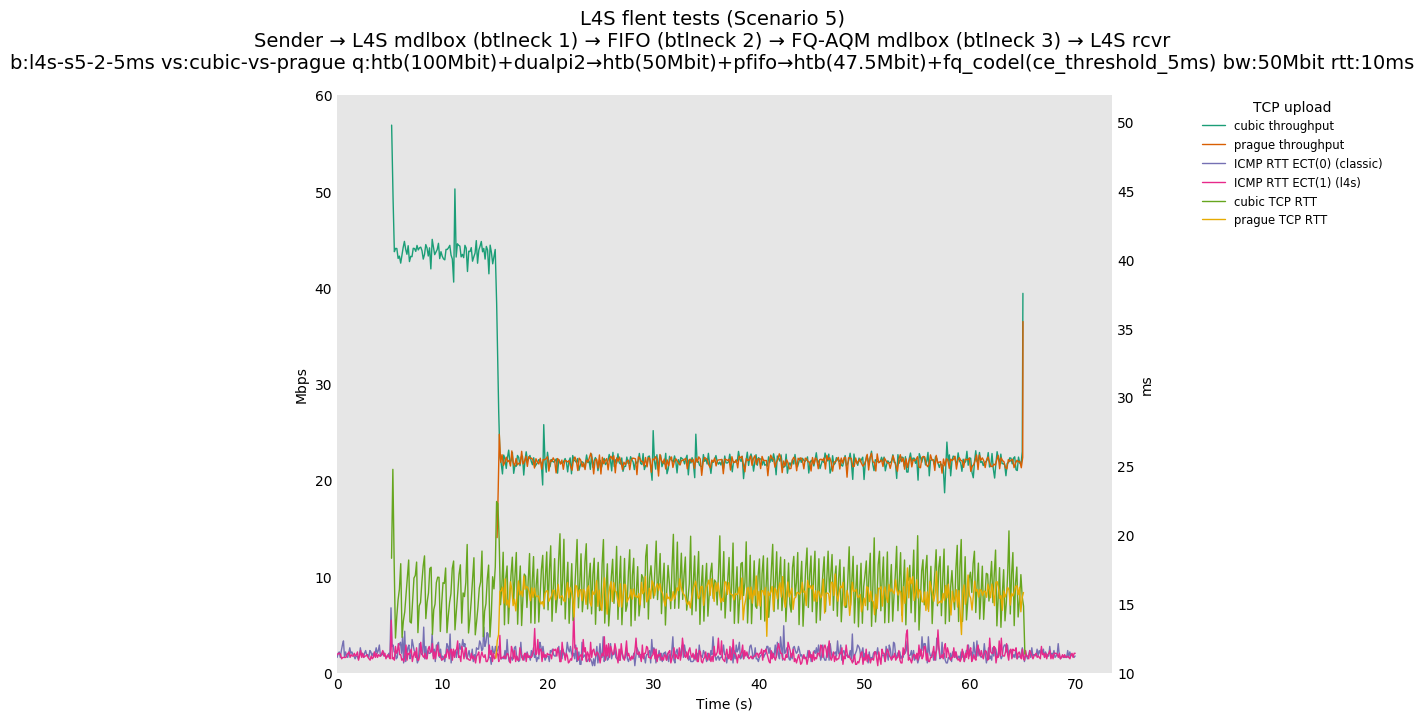
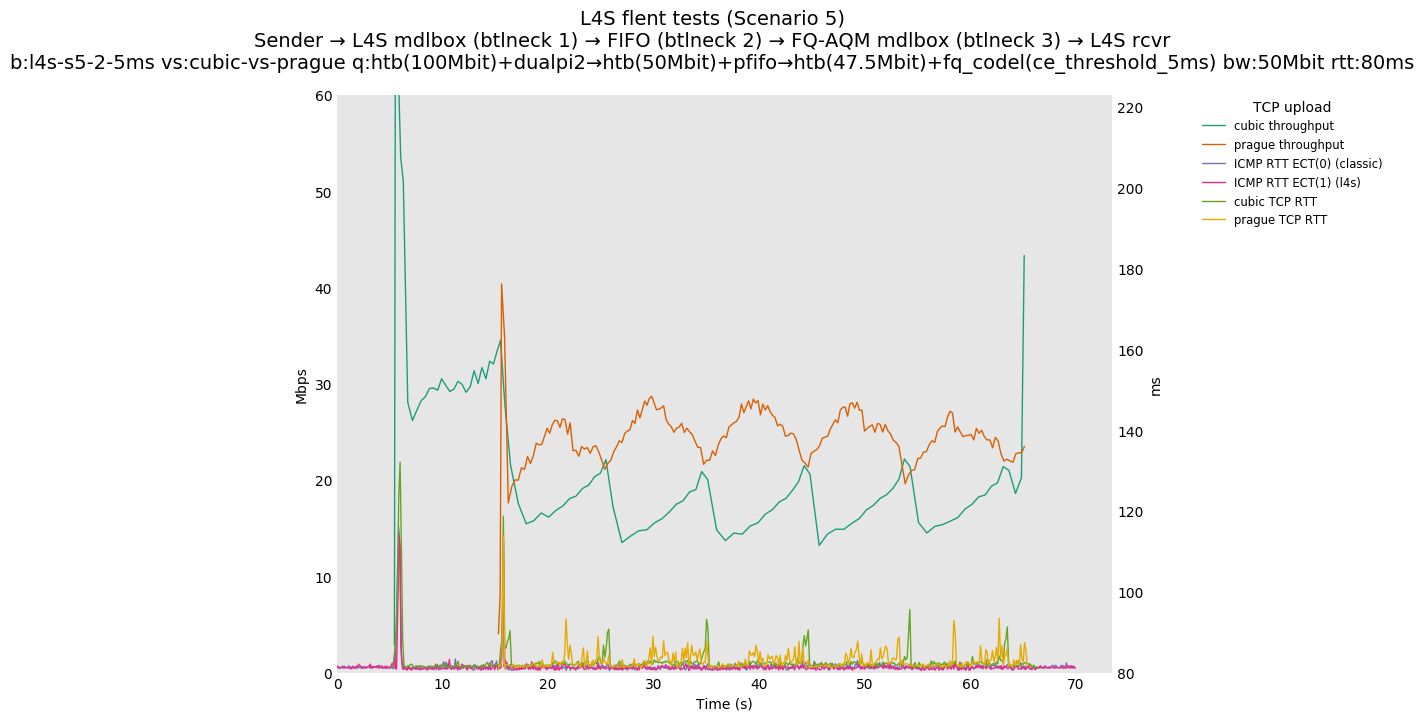
This is Sebastian Moeller's scenario. We had some discussion about the propensity of existing senders to produce line-rate bursts, and the way these bursts could collect in all of the queues at successively decreasing bottlenecks. This is a test which explores the effects of that scenario, and is relevant to best consumer practice on today's Internet.
L4S: Sender → L4S middlebox (bottleneck #1, 100Mbit) → FIFO middlebox (bottleneck #2, 50Mbit) → FQ-AQM middlebox (bottleneck #3, 47.5Mbit) → L4S receiver
| 50Mb-0ms | 50Mb-10ms | 50Mb-80ms |
|---|---|---|
| reno | reno | reno |
| cubic | cubic | cubic |
| bbr | bbr | bbr |
| prague | prague | prague |
| prague-vs-prague | prague-vs-prague | prague-vs-prague |
| cubic-vs-prague | cubic-vs-prague | cubic-vs-prague |
| cubic-vs-bbr | cubic-vs-bbr | cubic-vs-bbr |
In addition to cubic and prague, our tests also include bbrv1 and reno. We see that all congestion controls (with the exception of cubic at low RTT) cause a RTT spike as they exit slow start. In high RTT cases (the worst ones) the duration of said spike ranges from few hundreds of ms (cubic/reno/prague) to 1+sec (bbrv1).
We see no evidence that the previous bottleneck (@100Mb) has any effect. Furthermore, given the similarity of those results with those from scenario 3, we are inclined to believe that the dominant factor in those RTT spikes is the combination of CoDel's delayed response with the slow-start exit strategy of the various CCA.
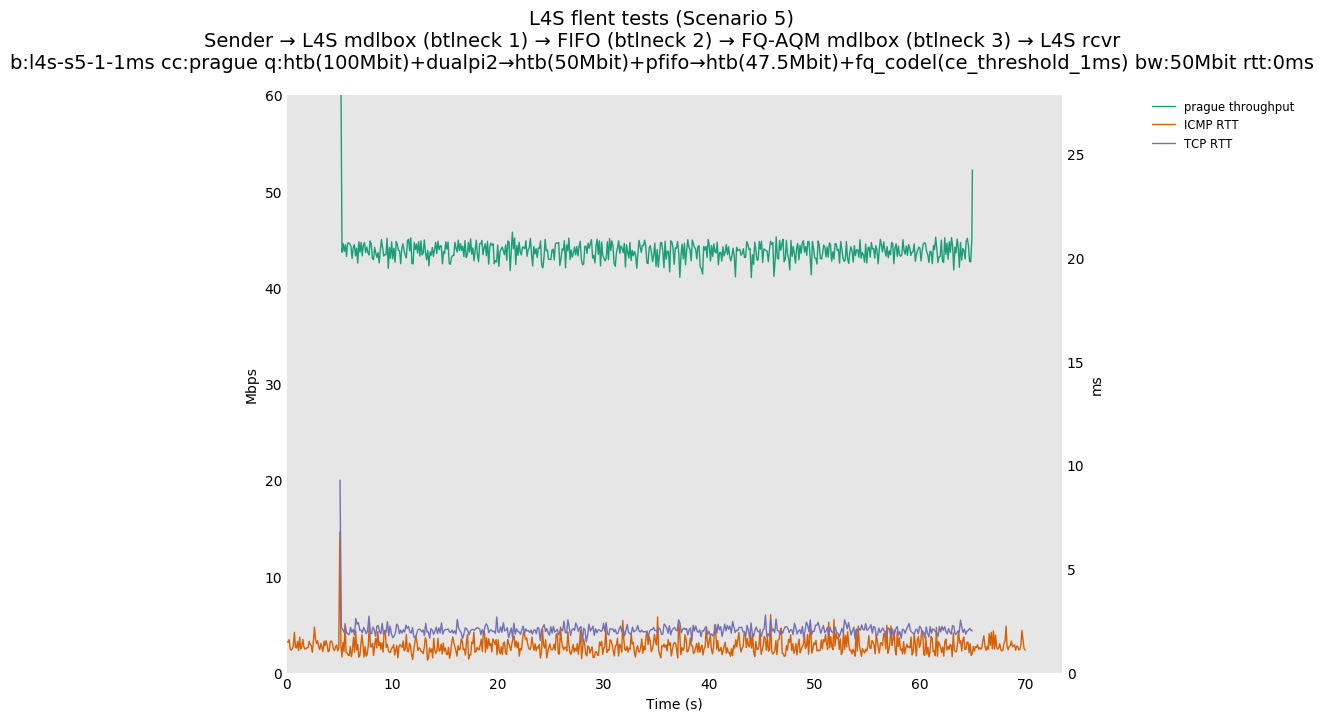
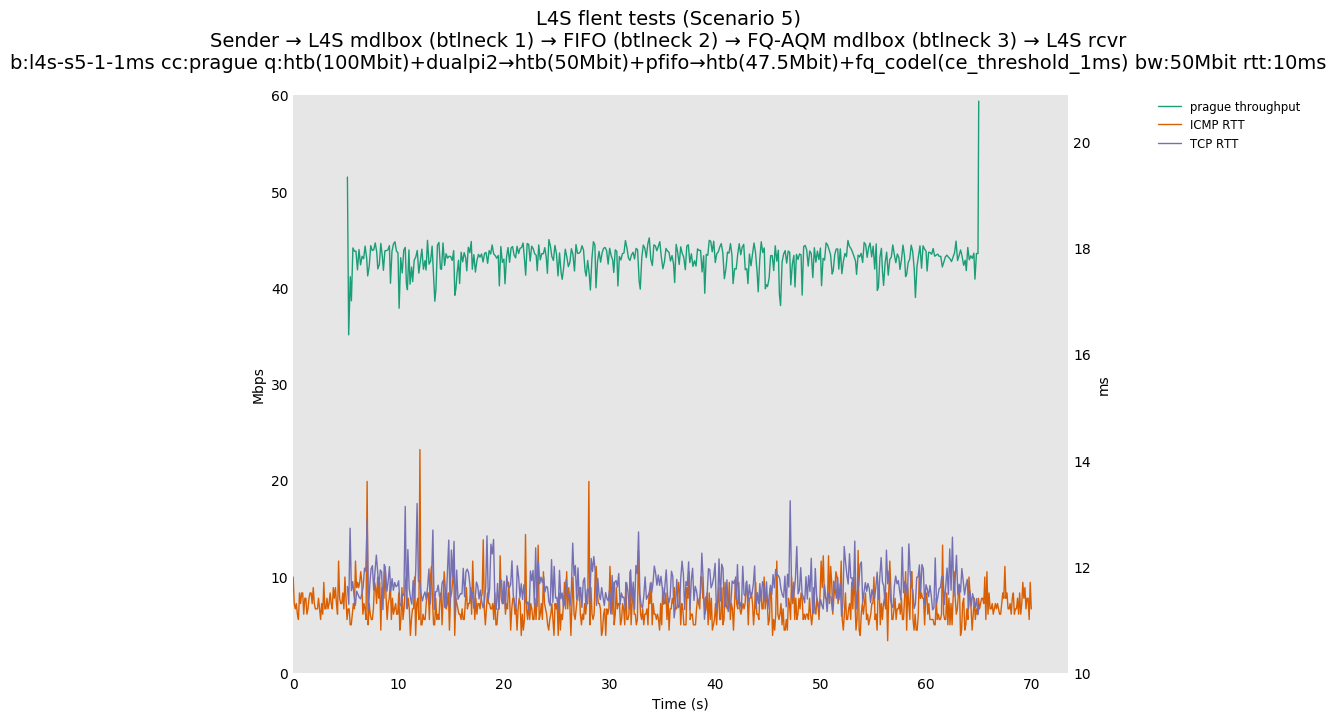
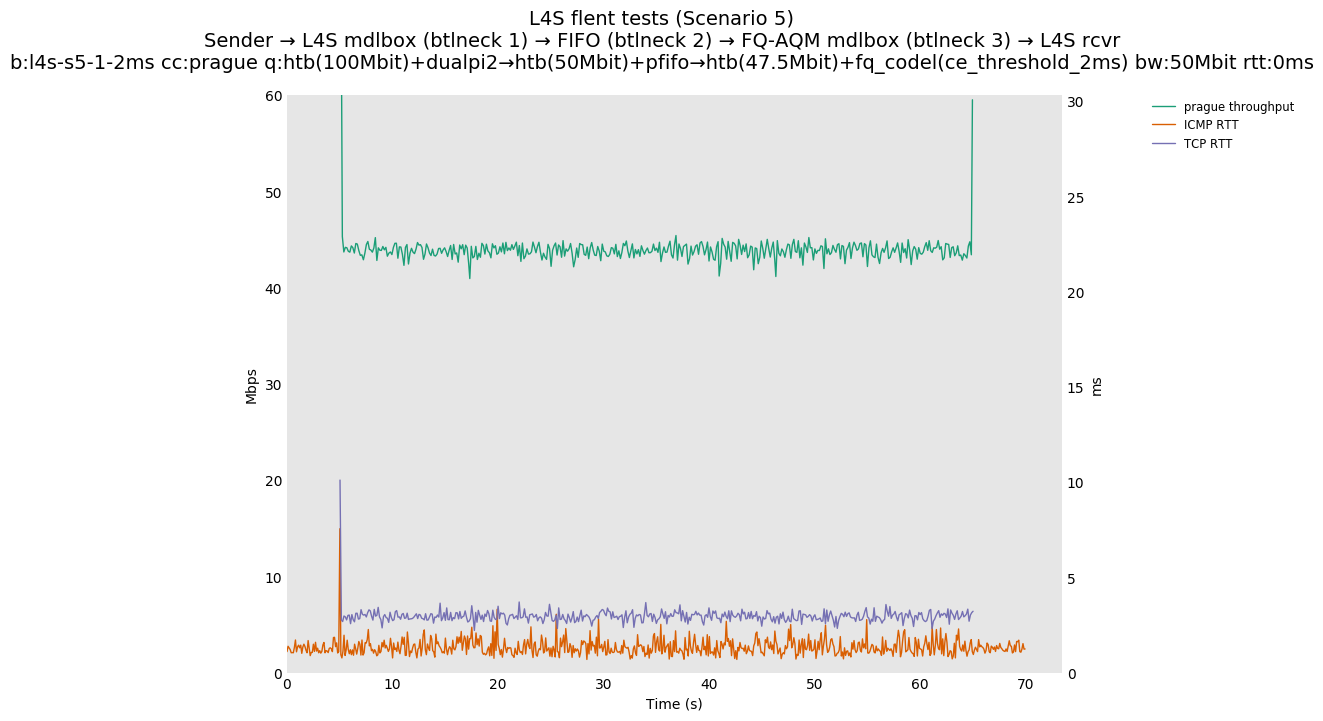
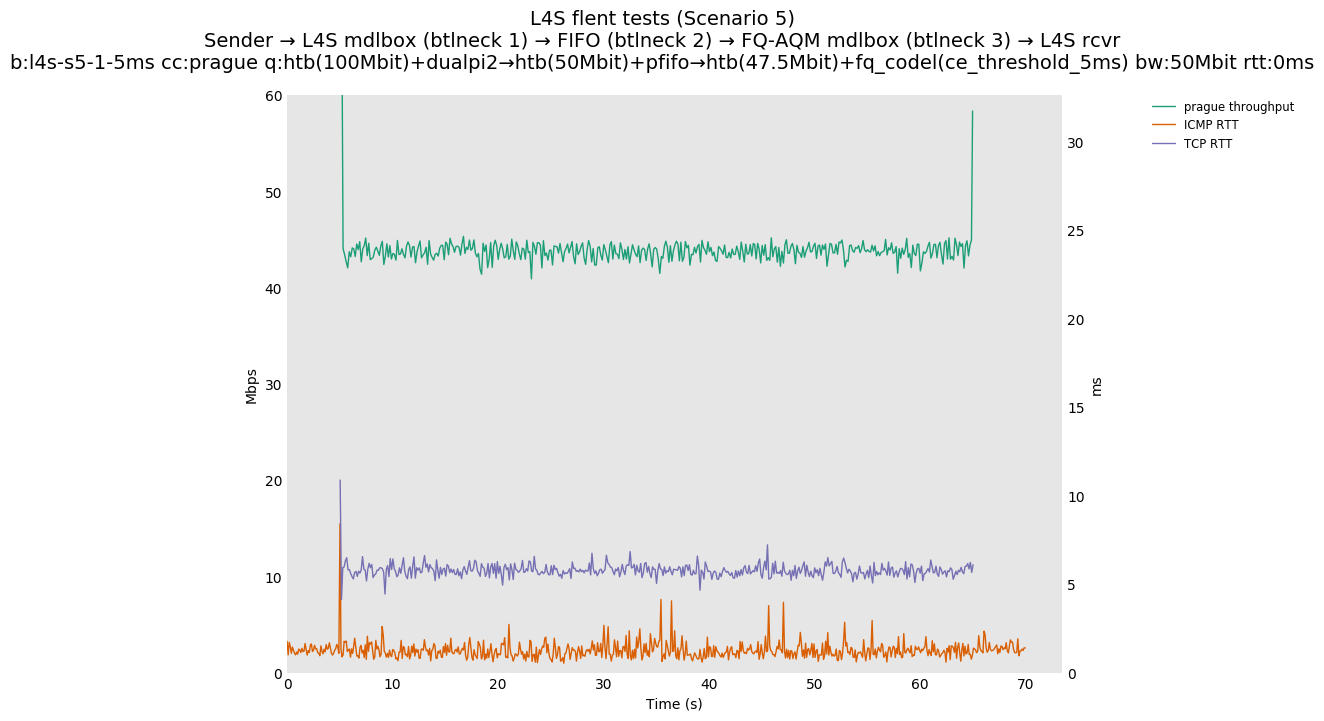
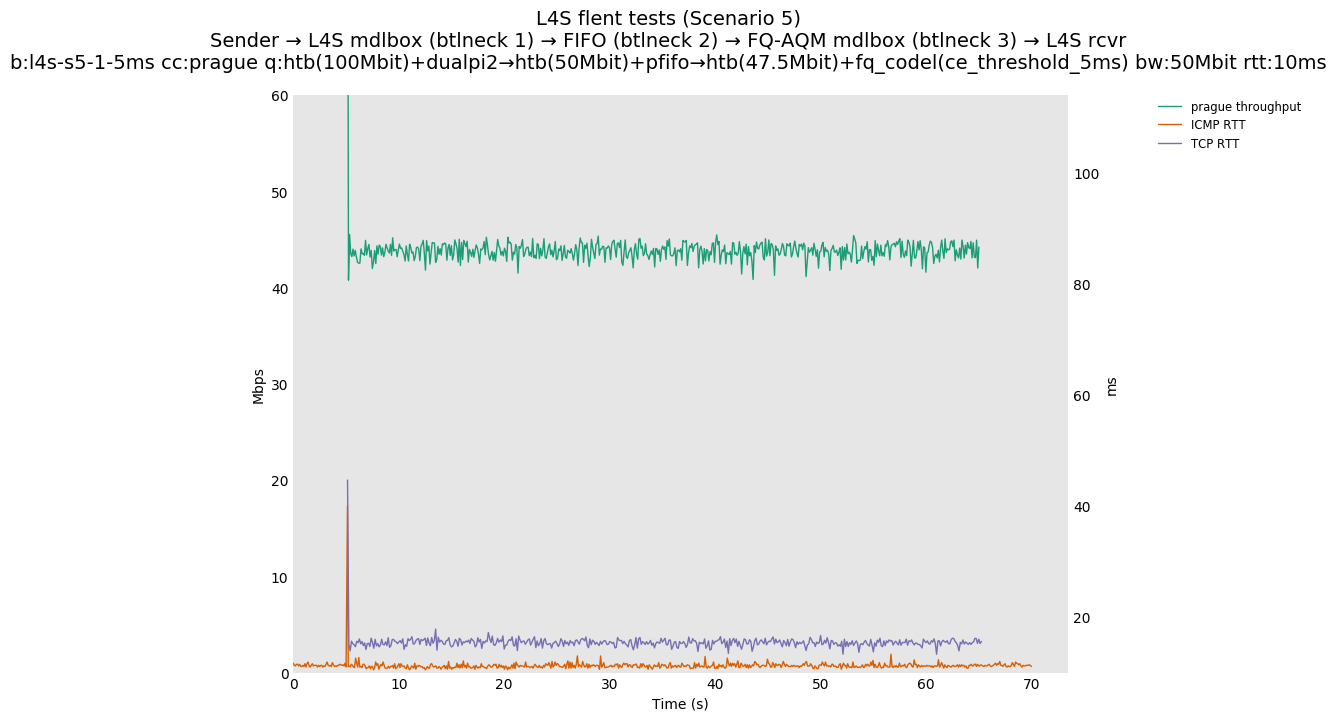
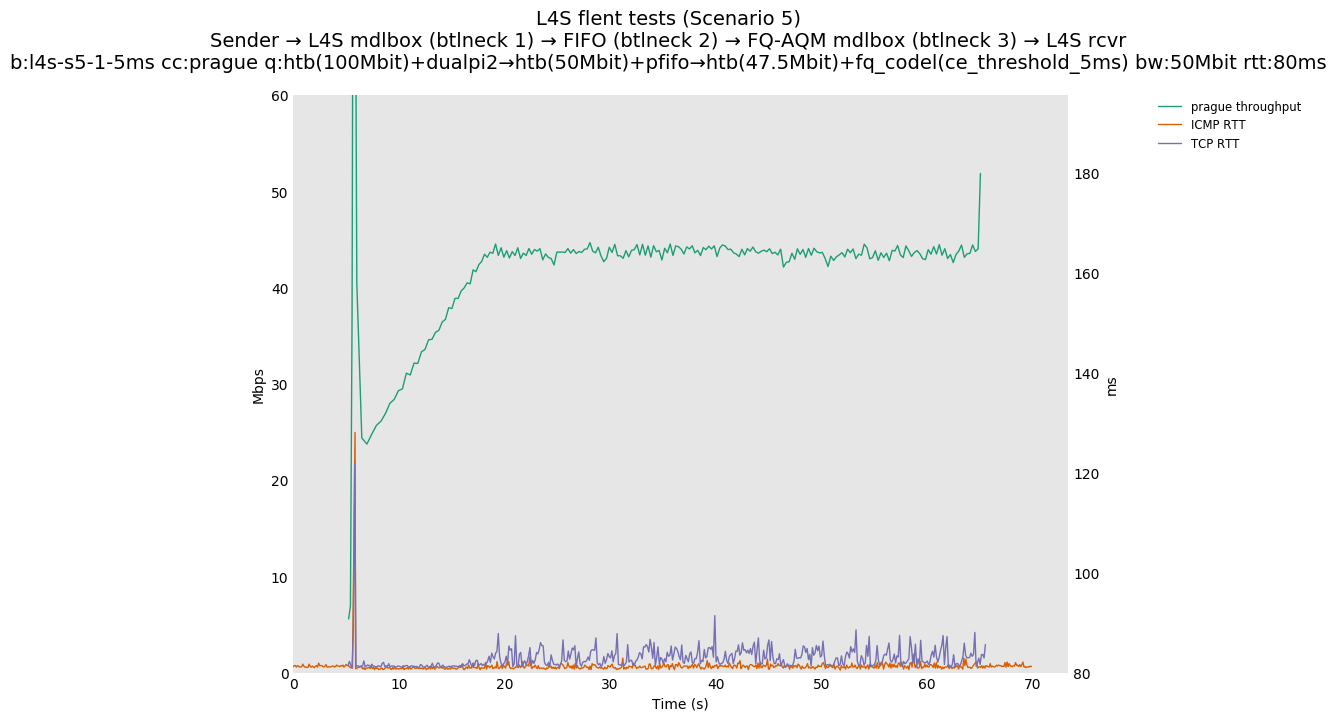
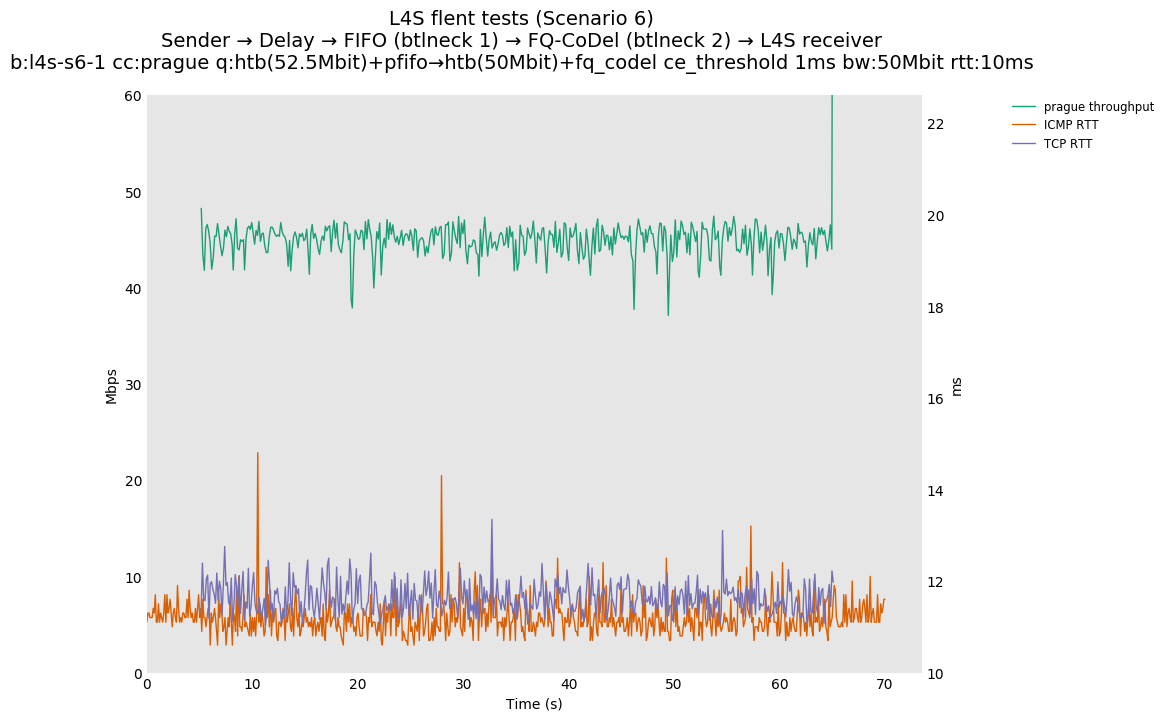
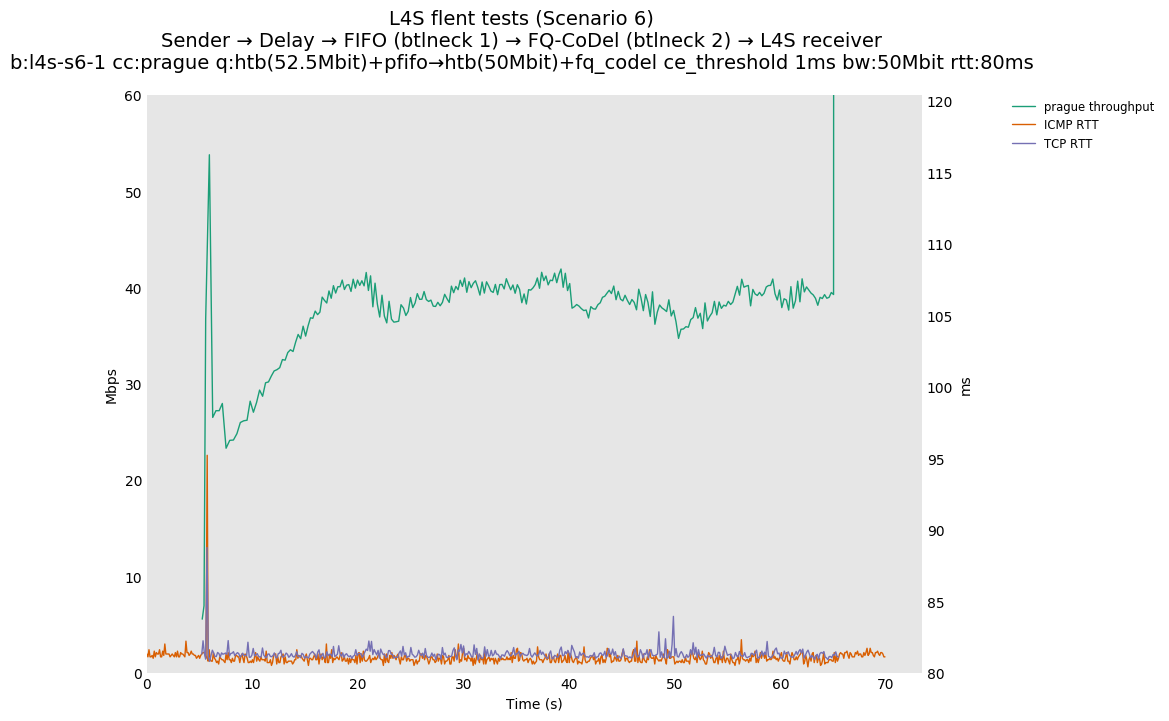
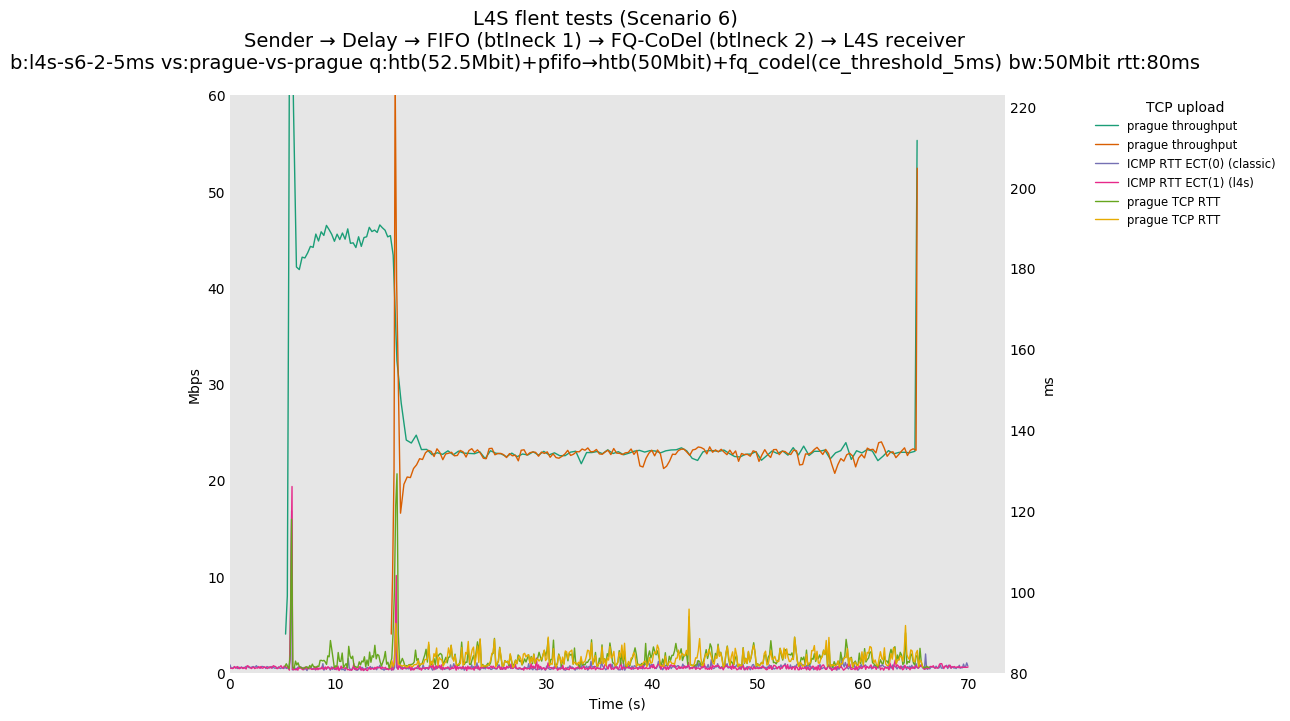
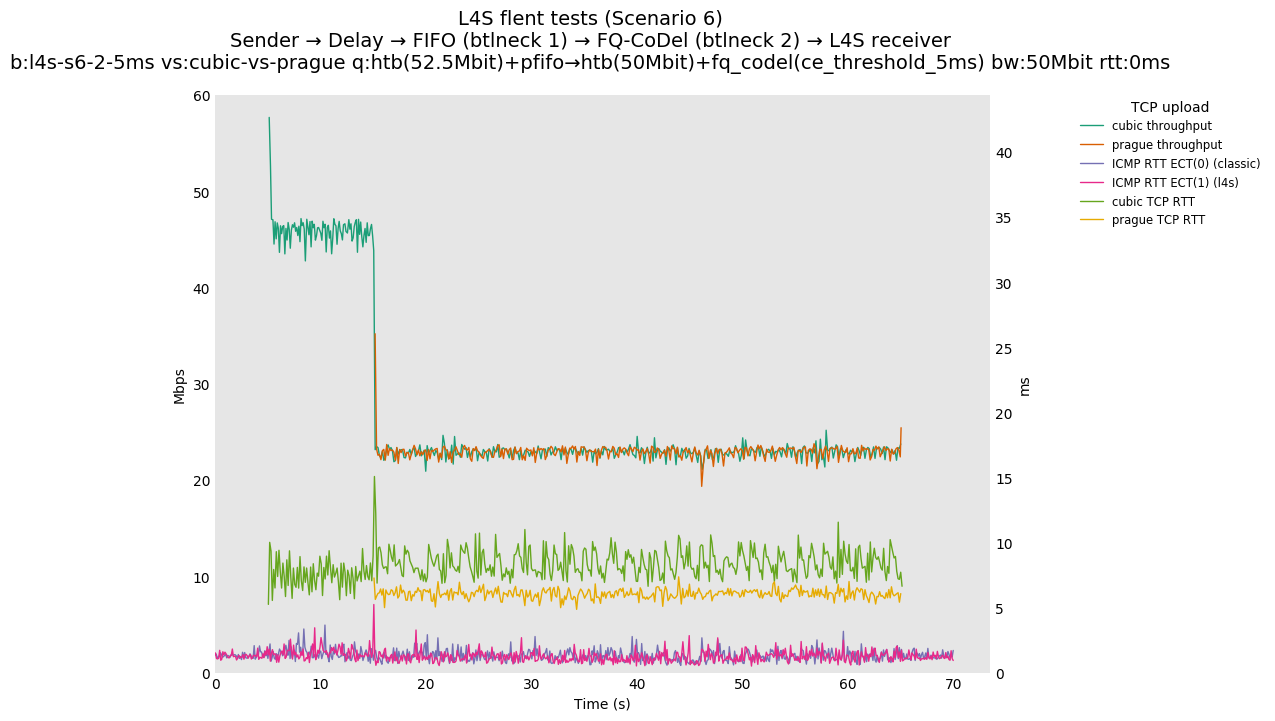
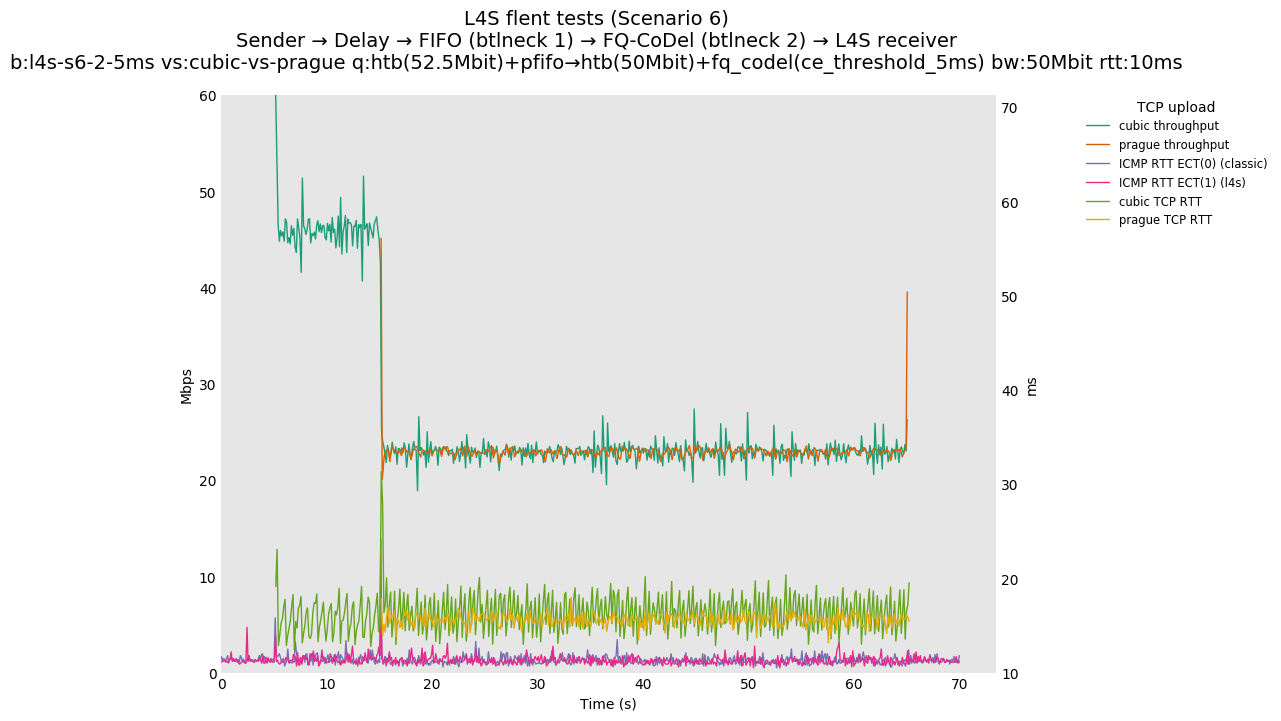
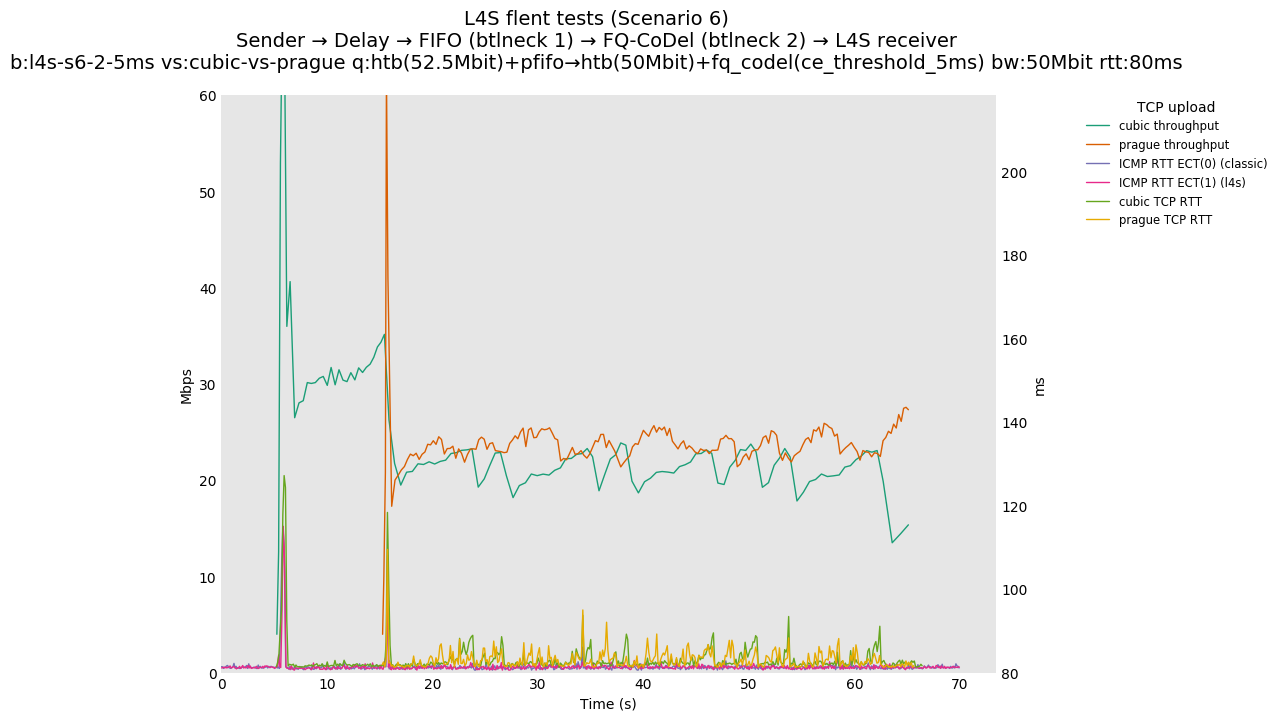
Finally, we re-run the tests using the cethreshold parameter of fqcodel, in order to have an additional immediate AQM akin to the one found in dualpi2--See the results below. We see that this considerably decrease the magnitude of the RTT spike (both for the TCP flow and the parallel ICMP flow). Given that said parameter has been around for years, this hints towards a reasonably easy upgrade for the exiting user of this setup.
| 50Mb-0ms | 50Mb-10ms | 50Mb-80ms |
|---|---|---|
| prague | prague | prague |
| prague-vs-prague | prague-vs-prague | prague-vs-prague |
| cubic-vs-prague | cubic-vs-prague | cubic-vs-prague |
| 50Mb-0ms | 50Mb-10ms | 50Mb-80ms |
|---|---|---|
| prague | prague | prague |
| prague-vs-prague | prague-vs-prague | prague-vs-prague |
| cubic-vs-prague | cubic-vs-prague | cubic-vs-prague |
| 50Mb-0ms | 50Mb-10ms | 50Mb-80ms |
|---|---|---|
| prague | prague | prague |
| prague-vs-prague | prague-vs-prague | prague-vs-prague |
| cubic-vs-prague | cubic-vs-prague | cubic-vs-prague |
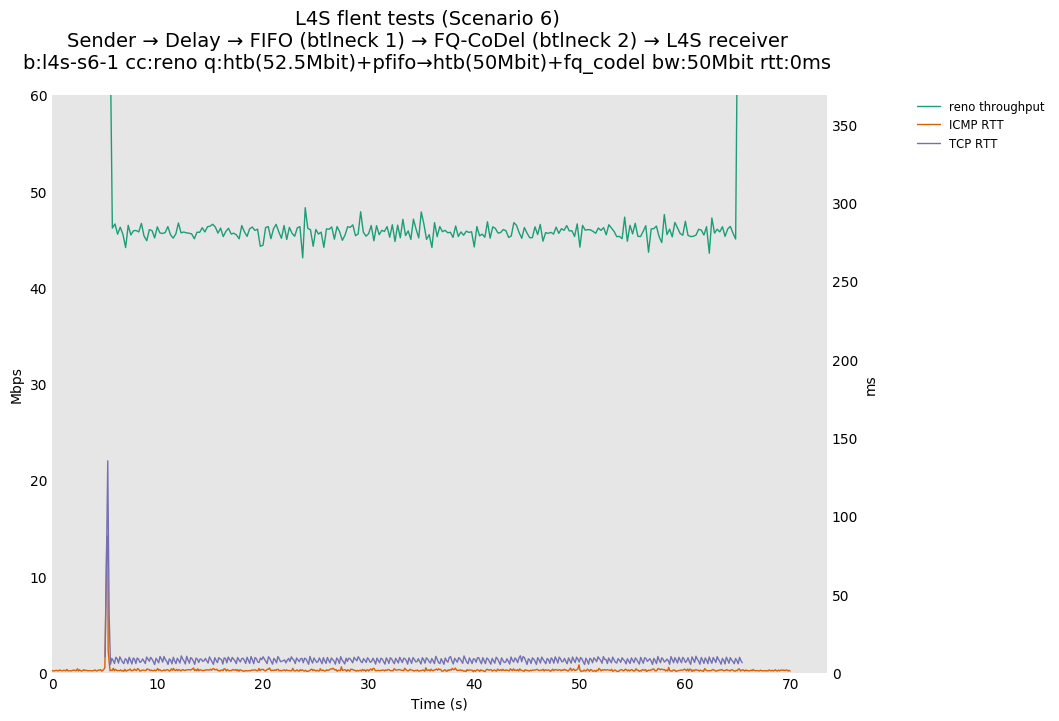
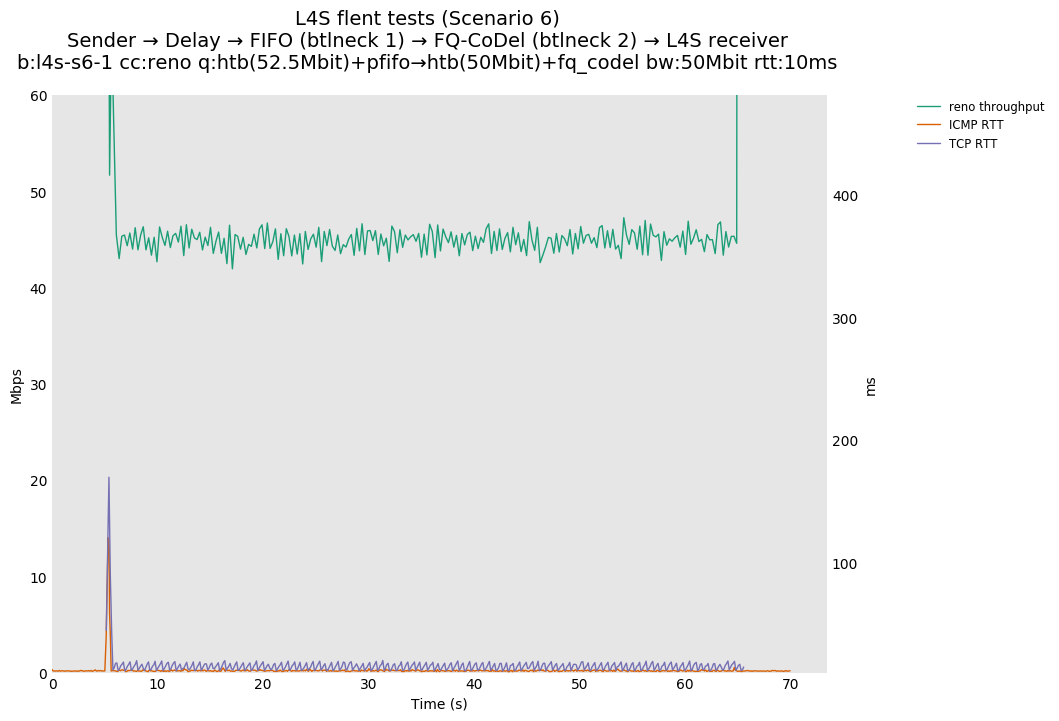
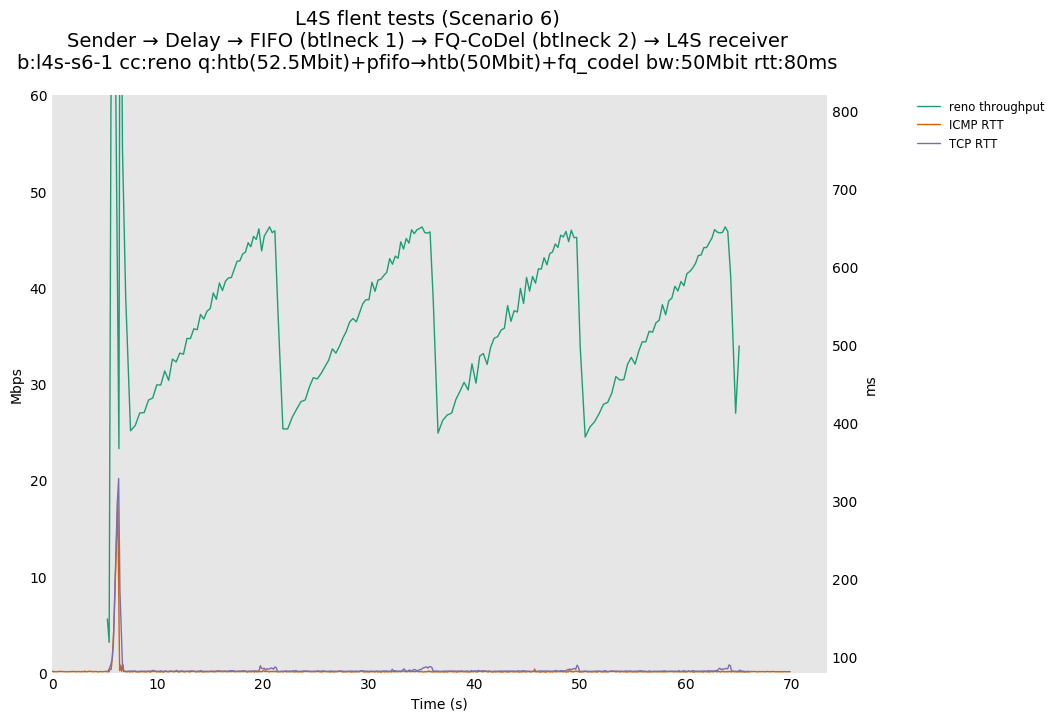
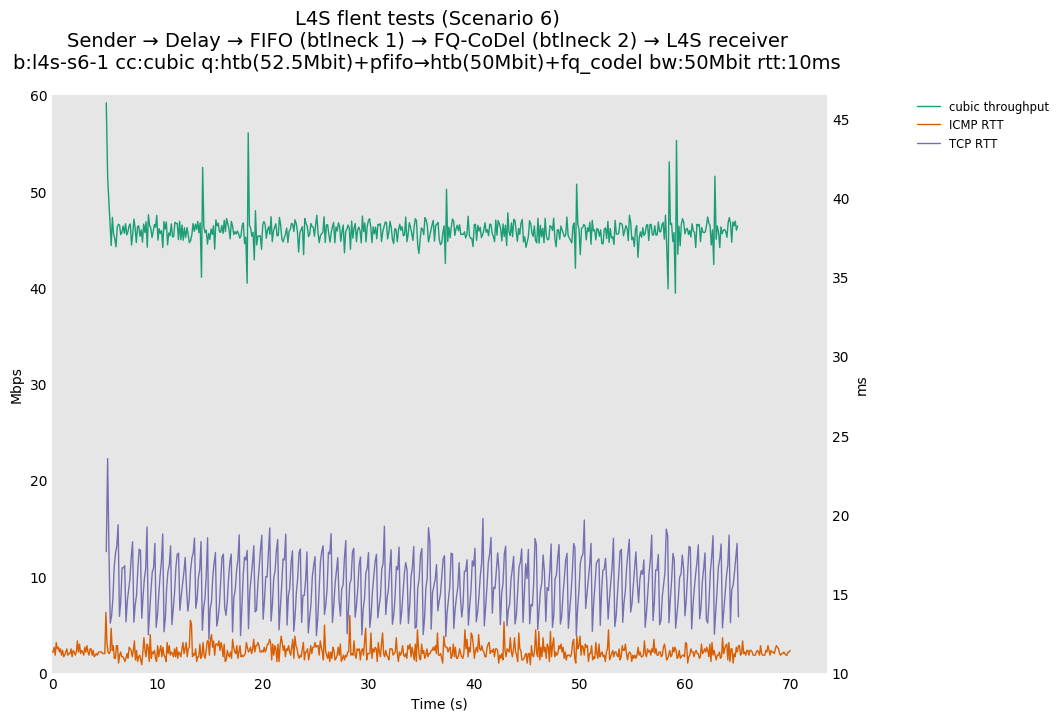
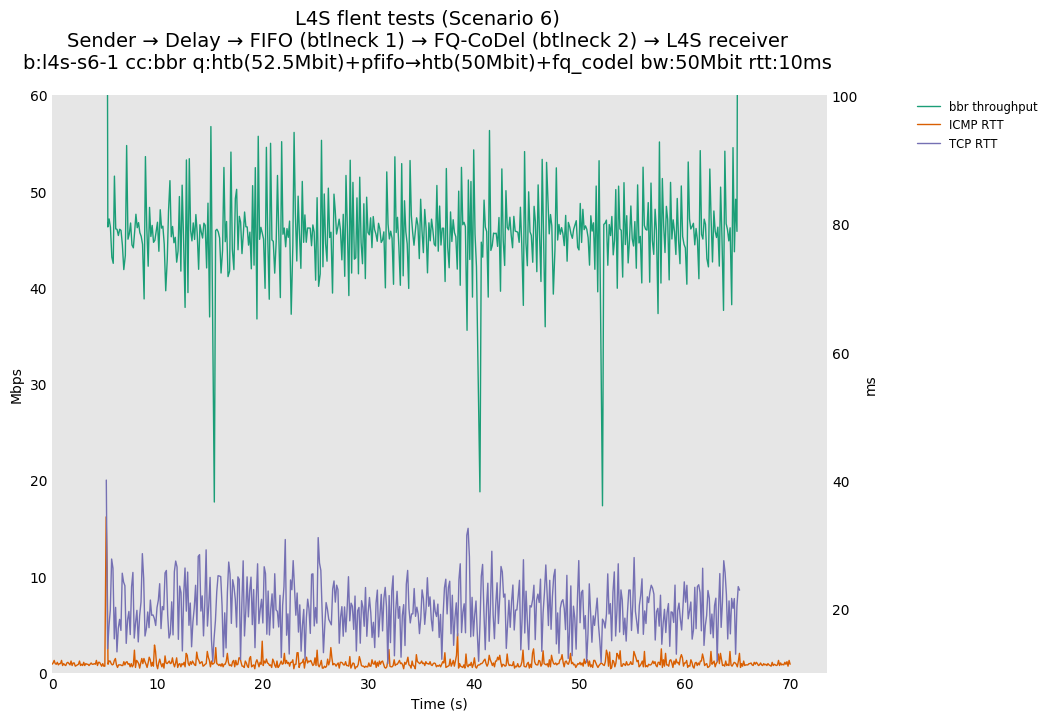
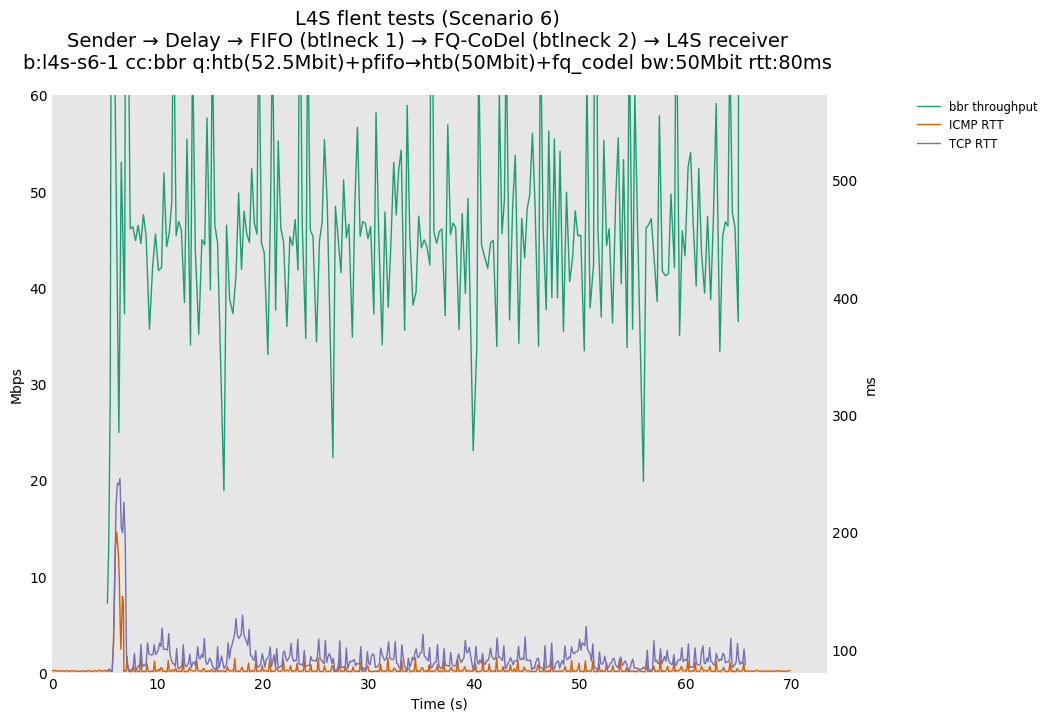
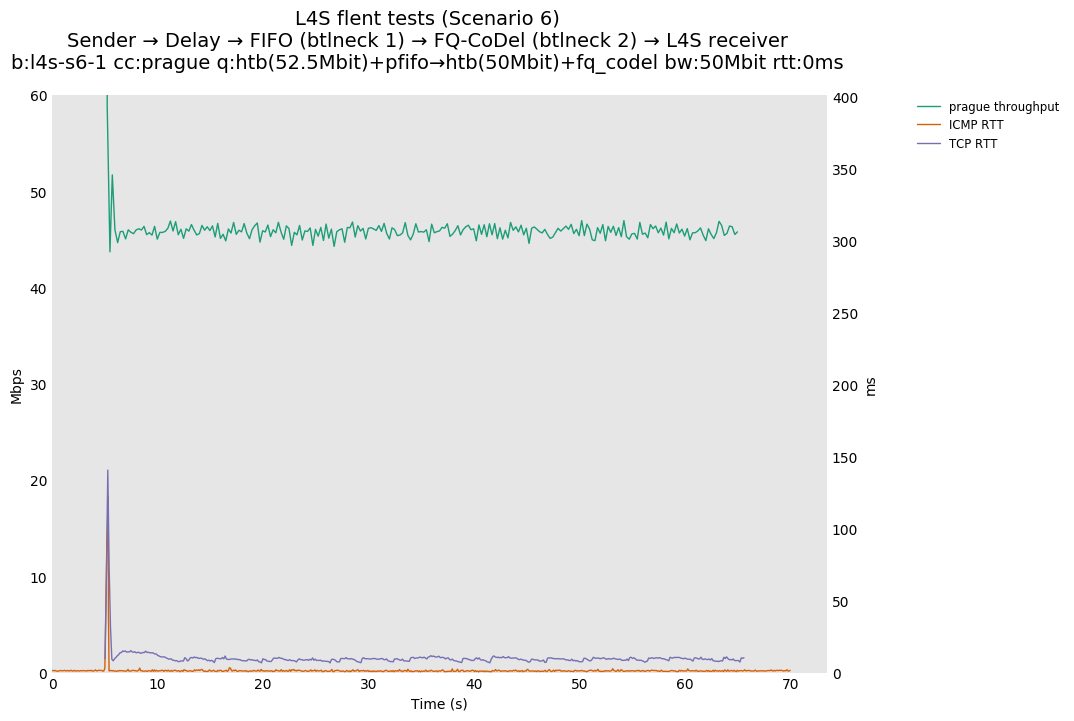
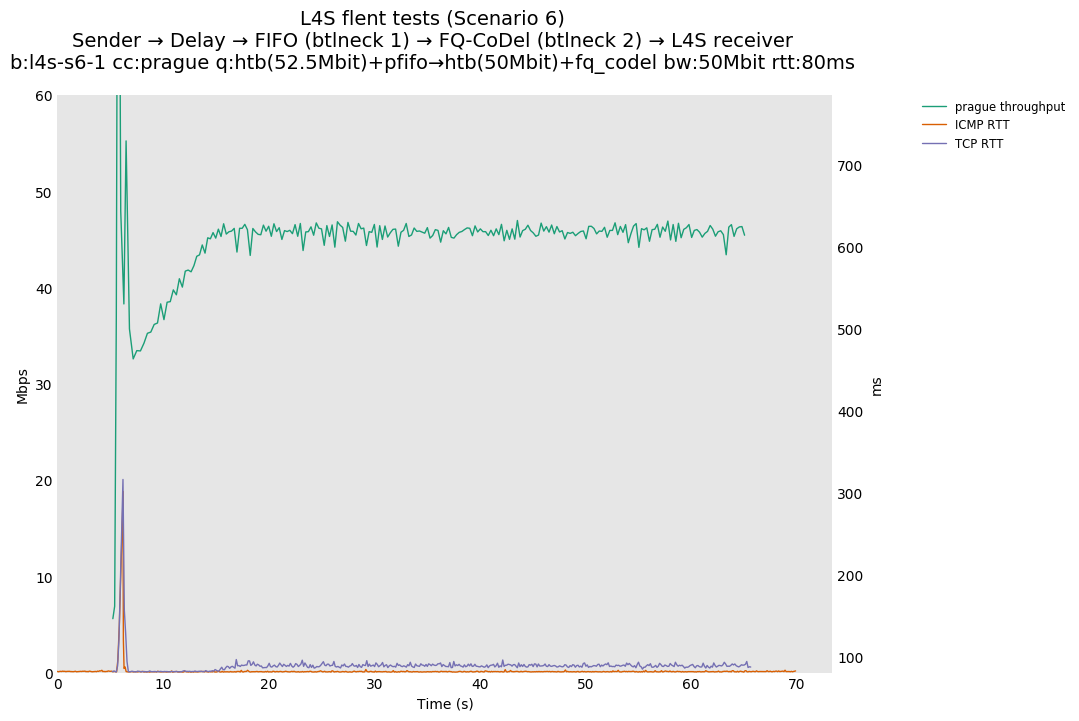
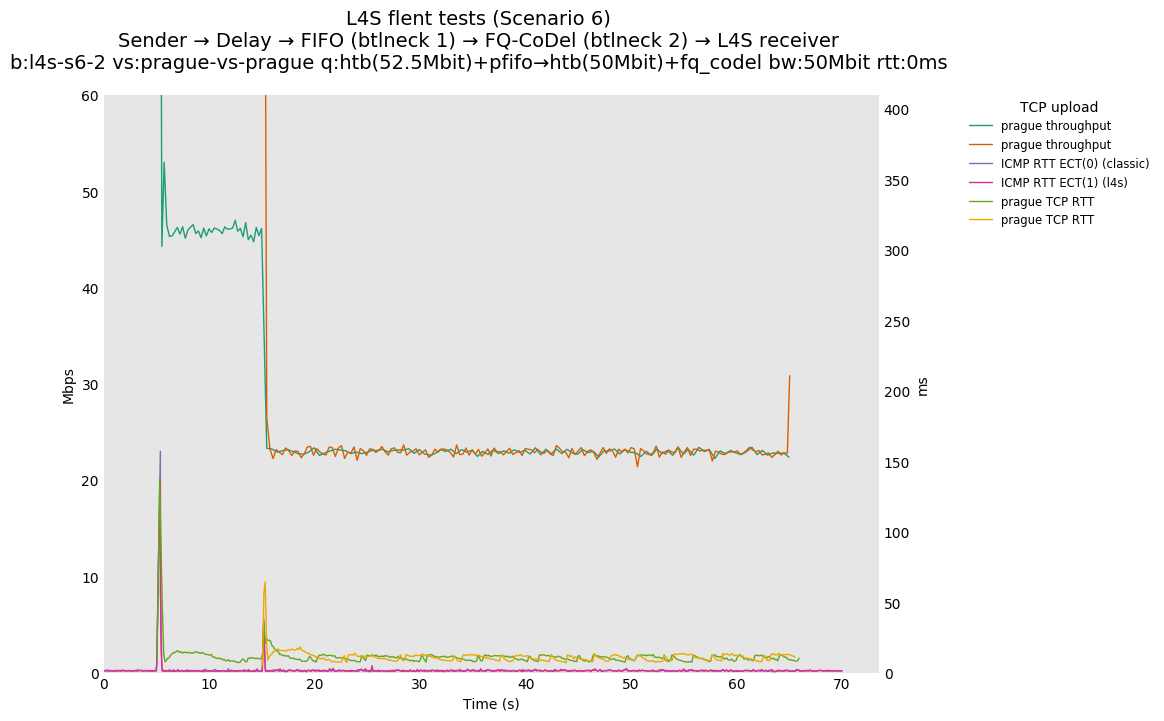
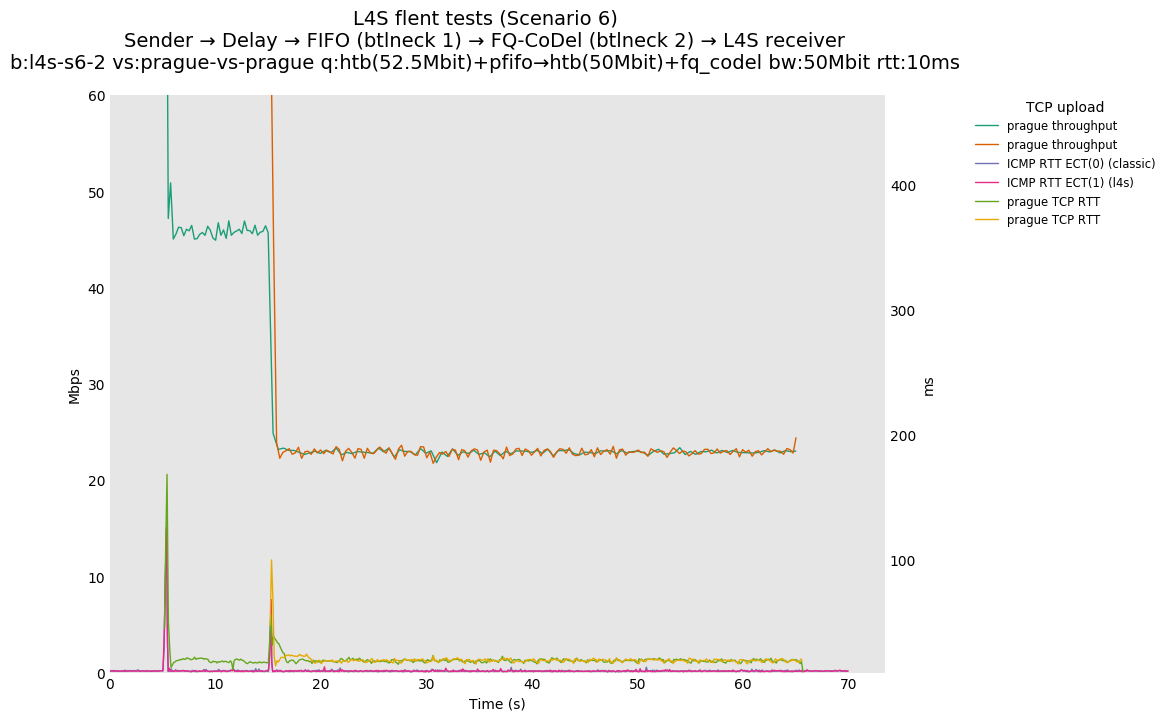
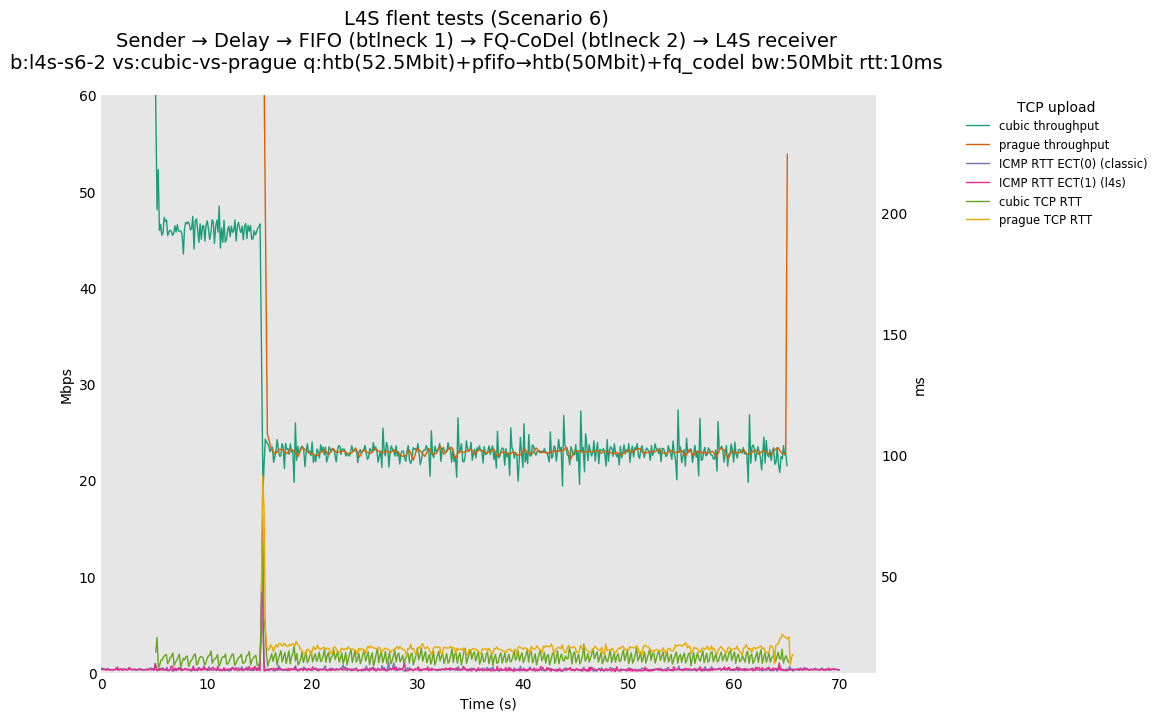
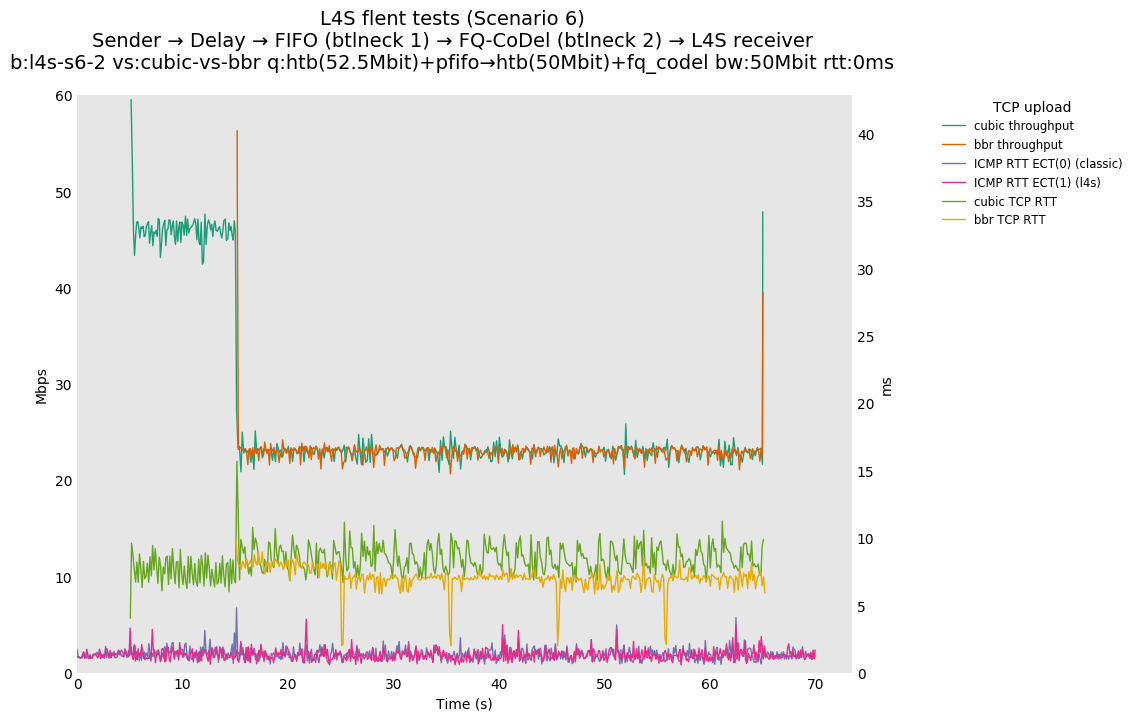
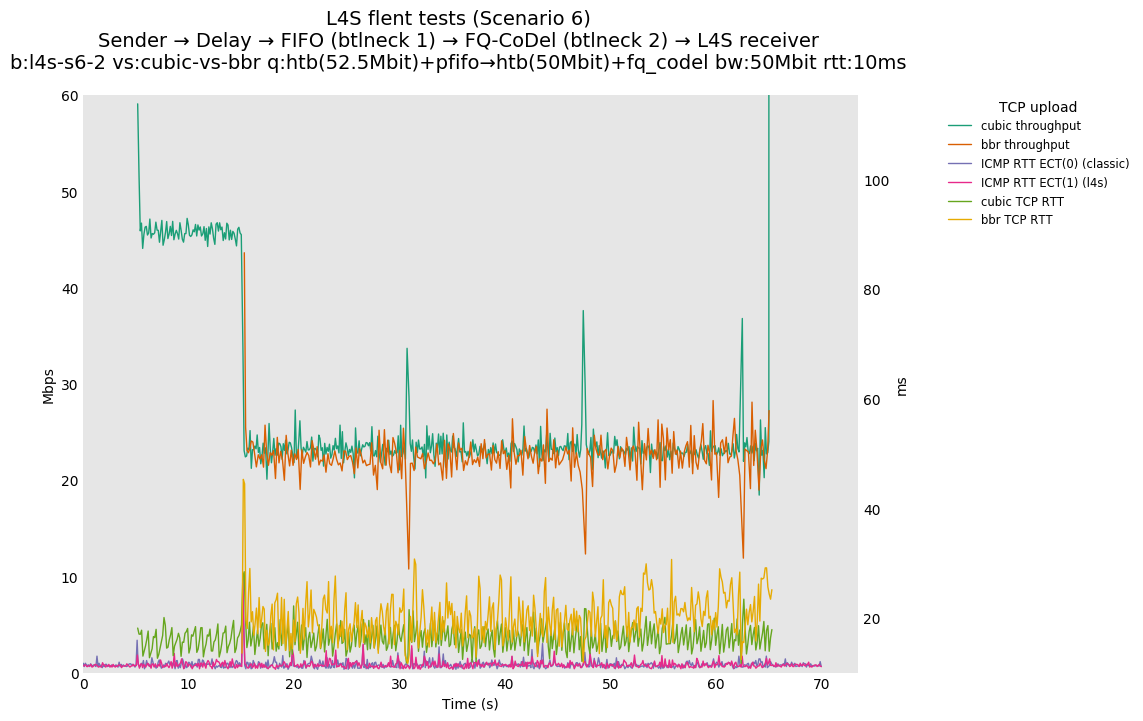
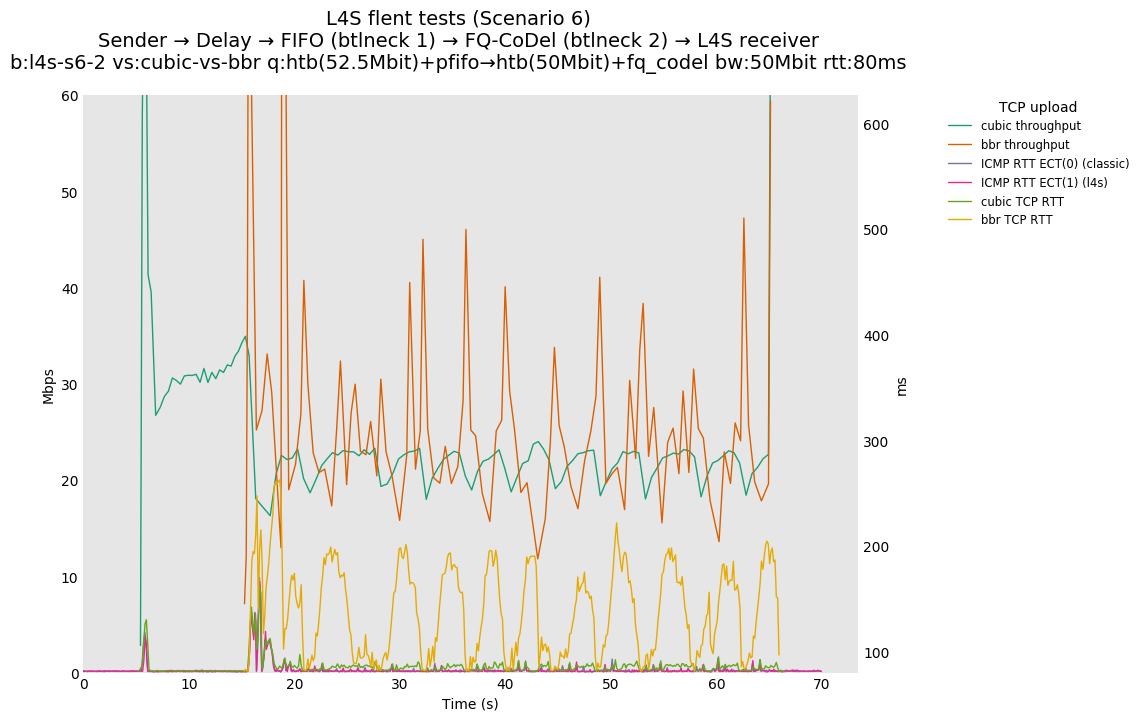
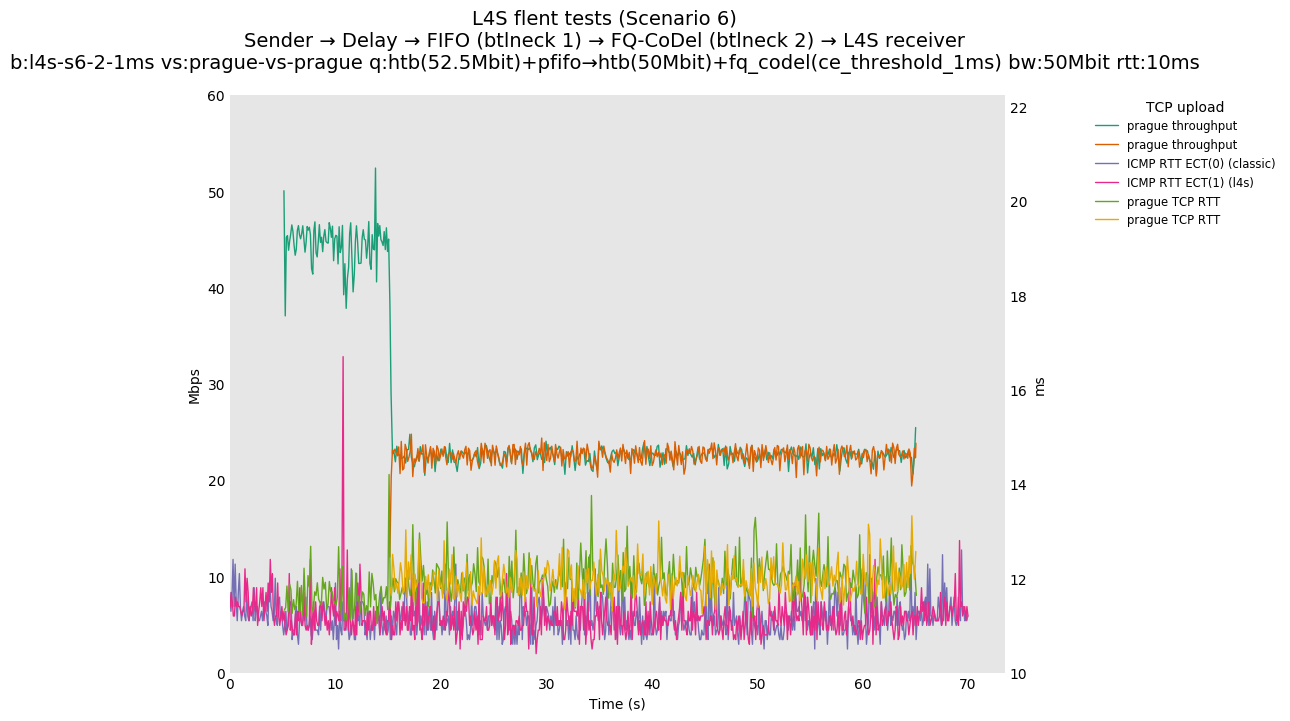
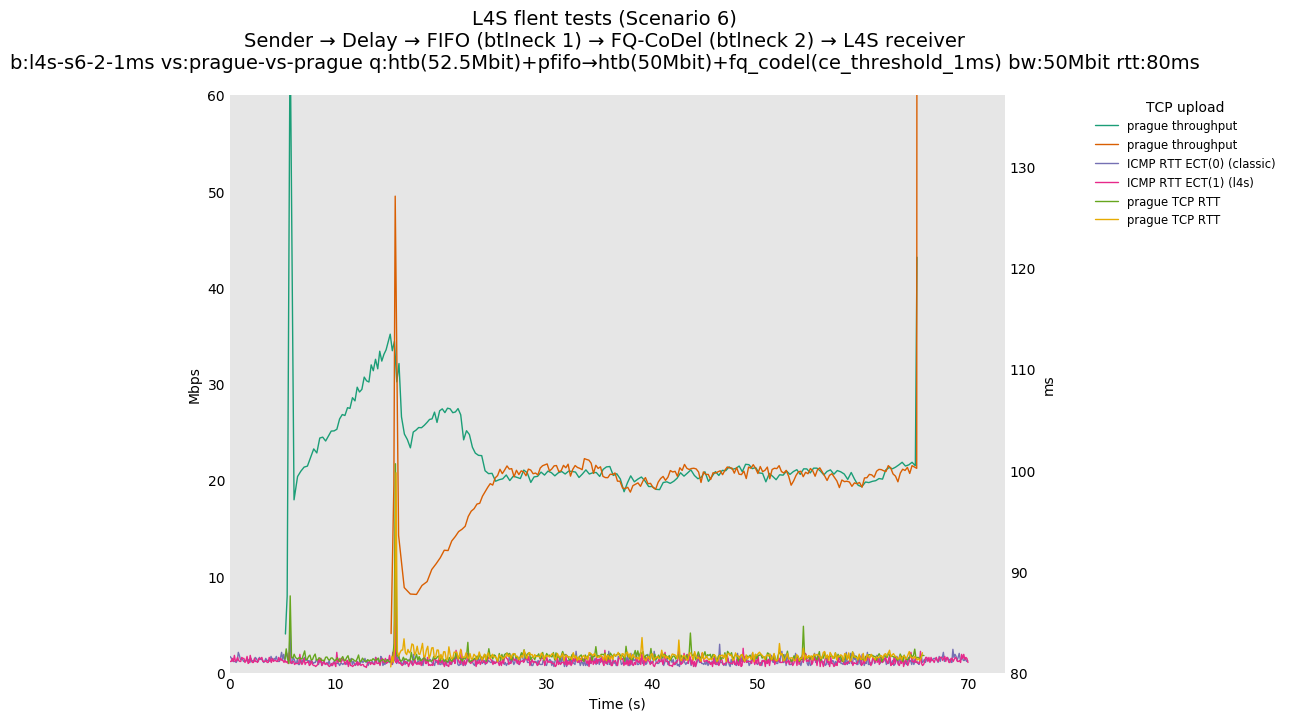
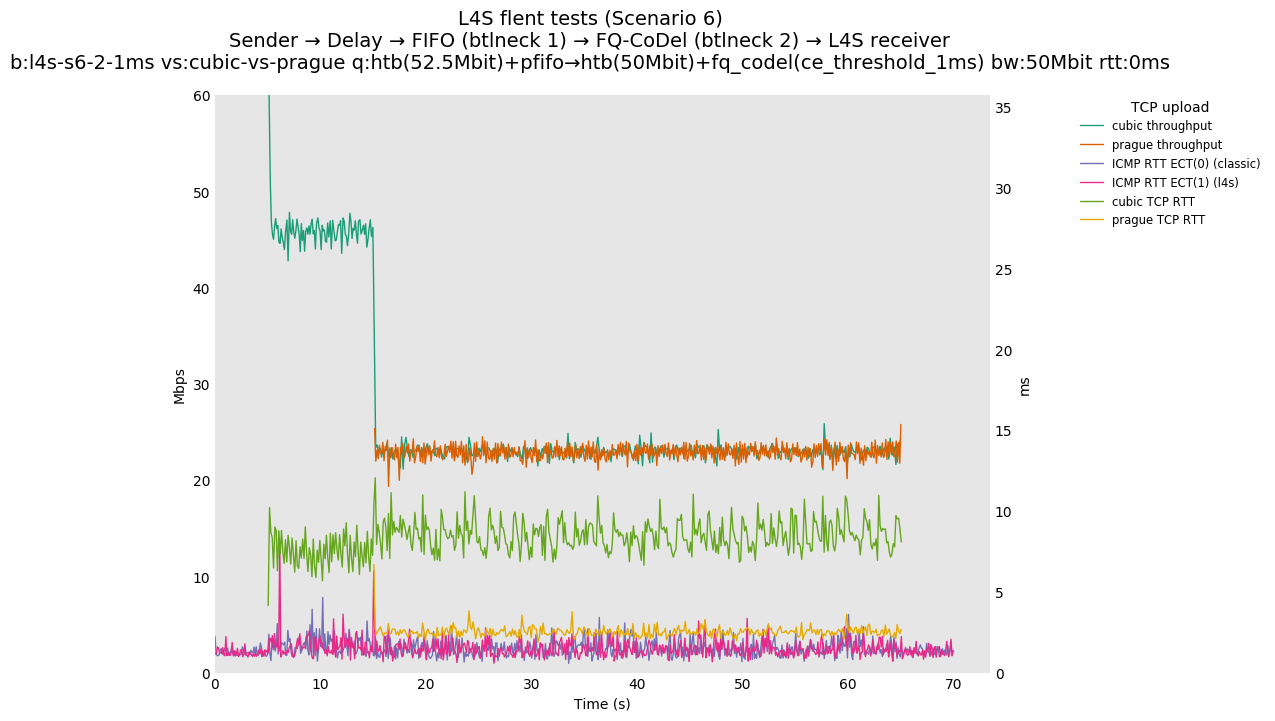
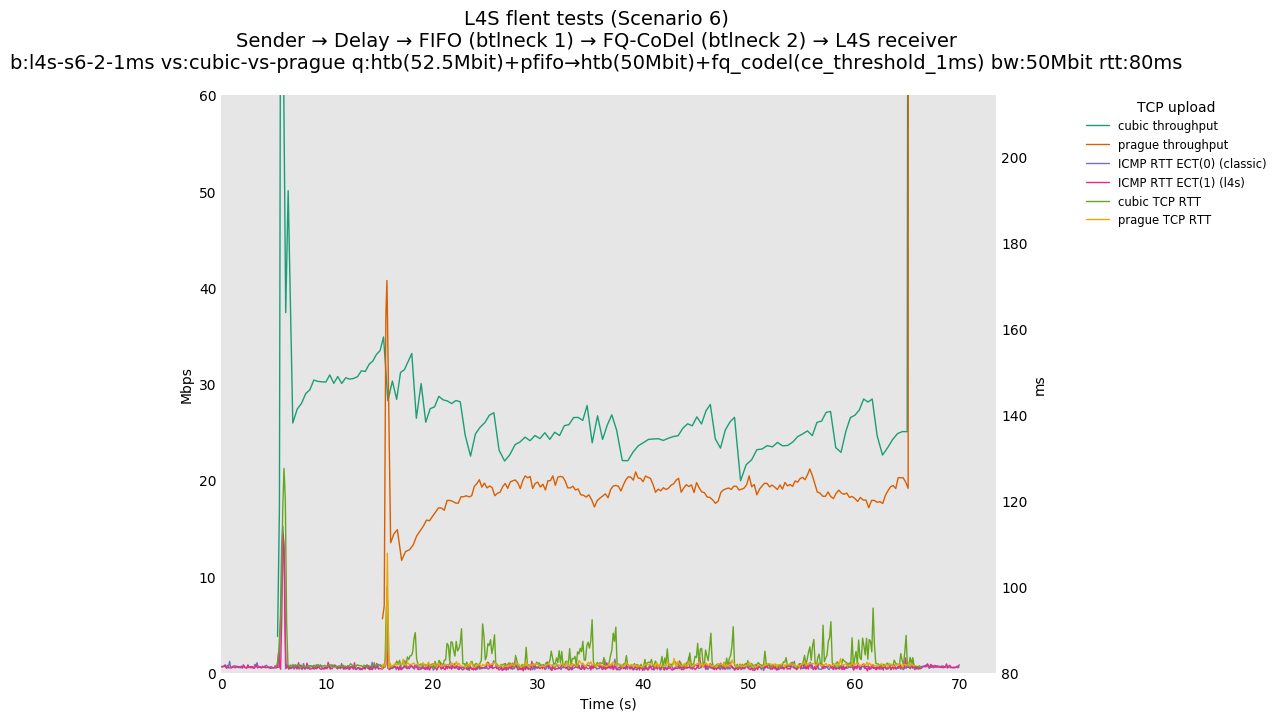
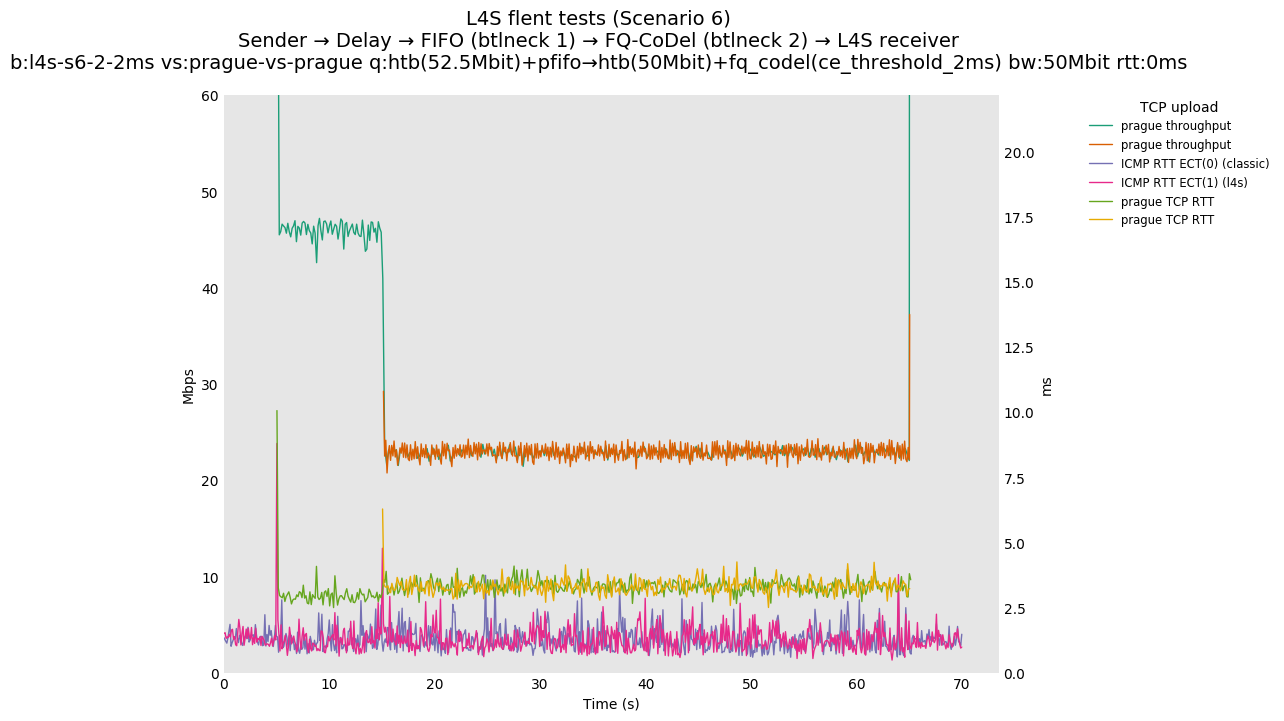
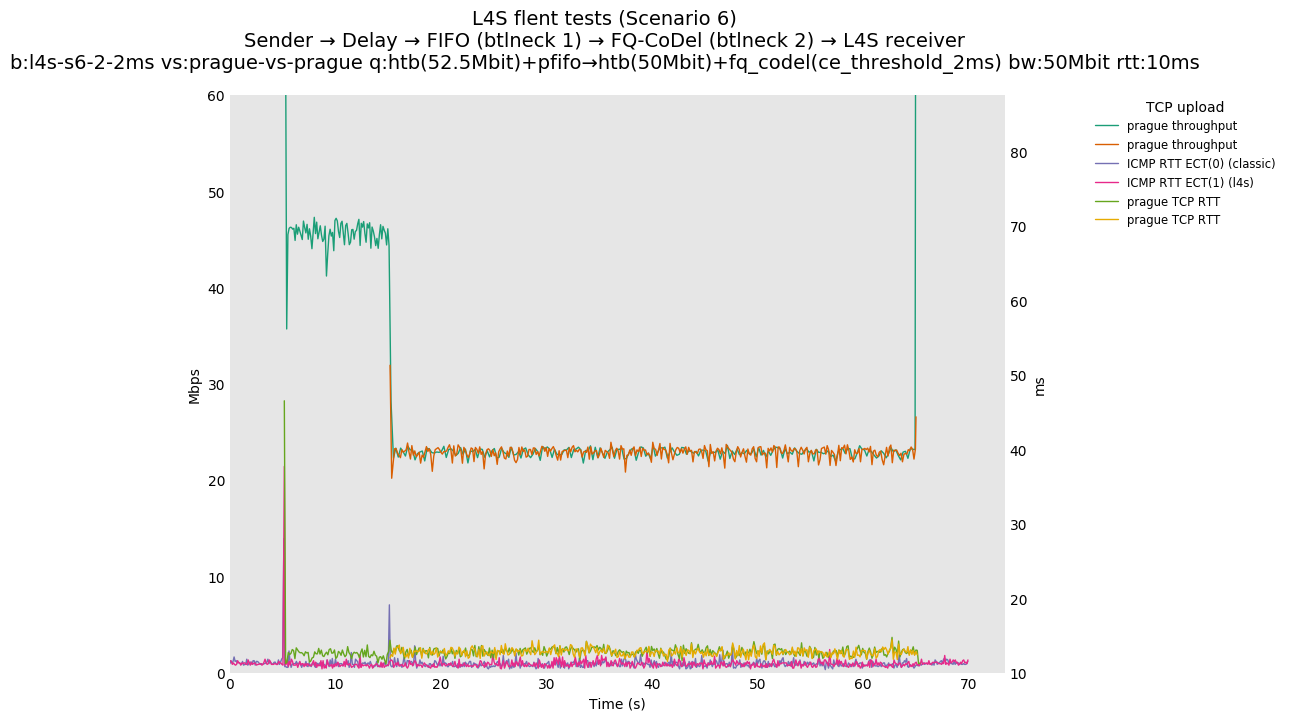
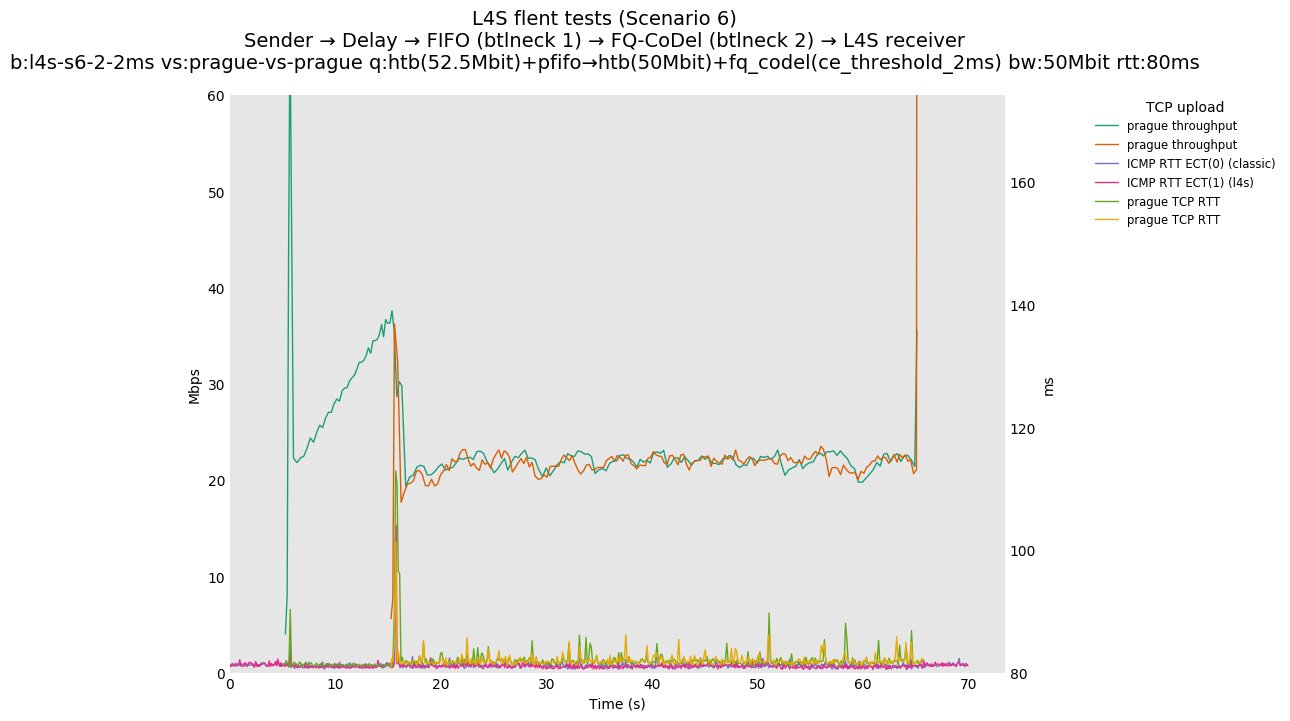
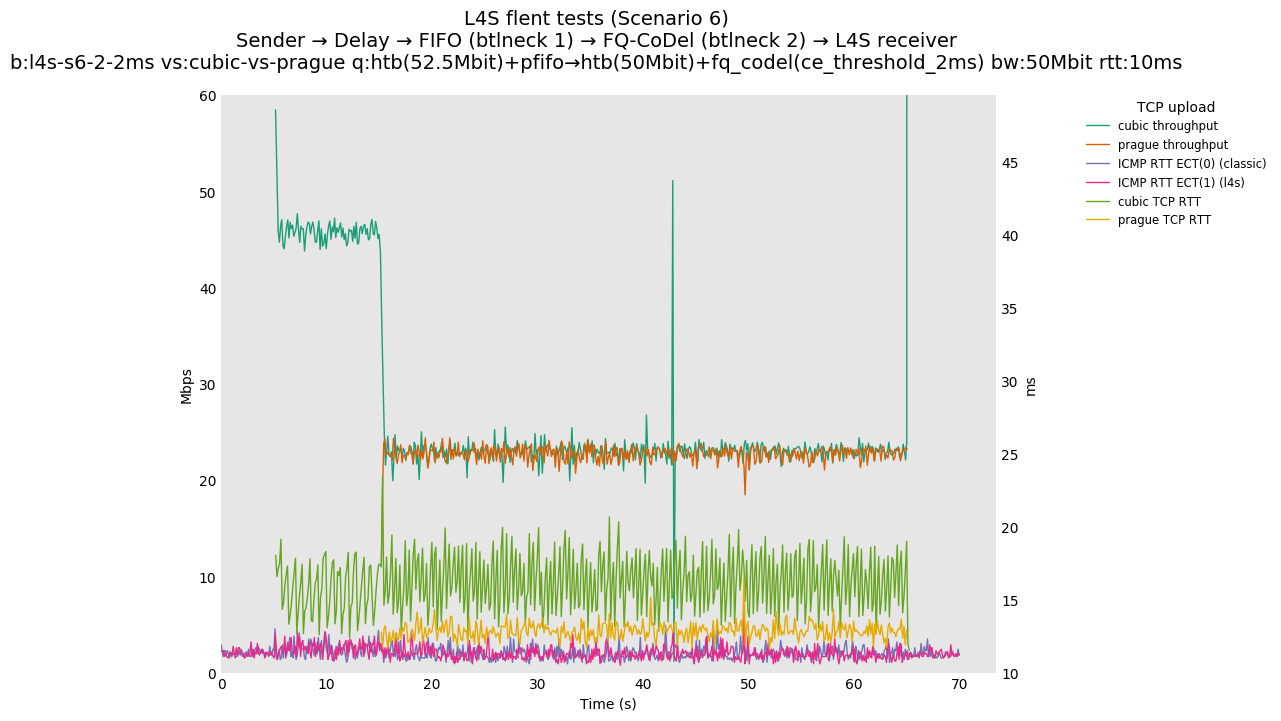
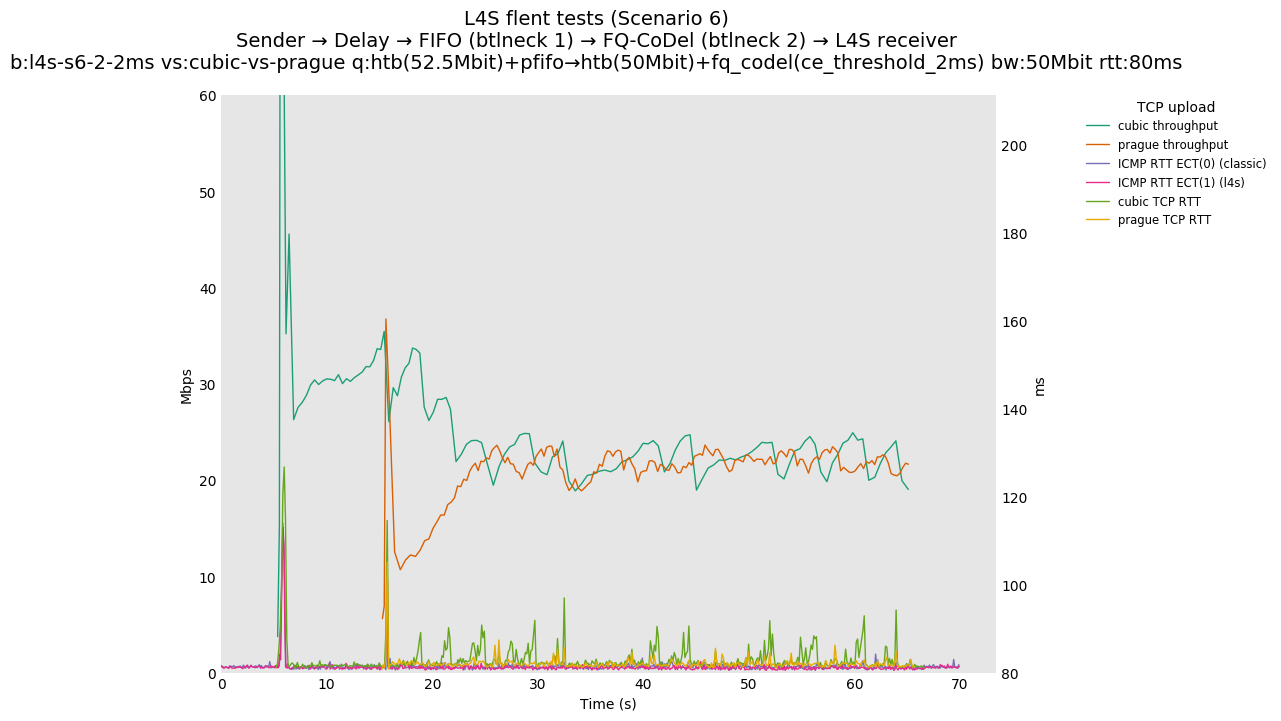
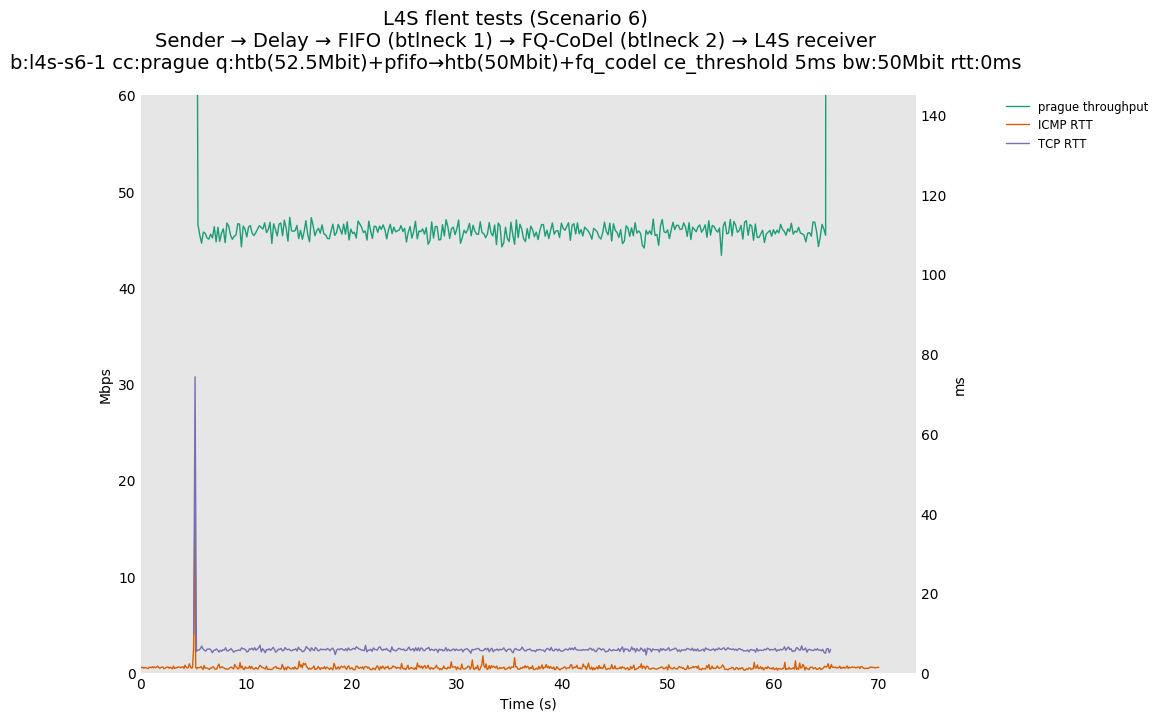
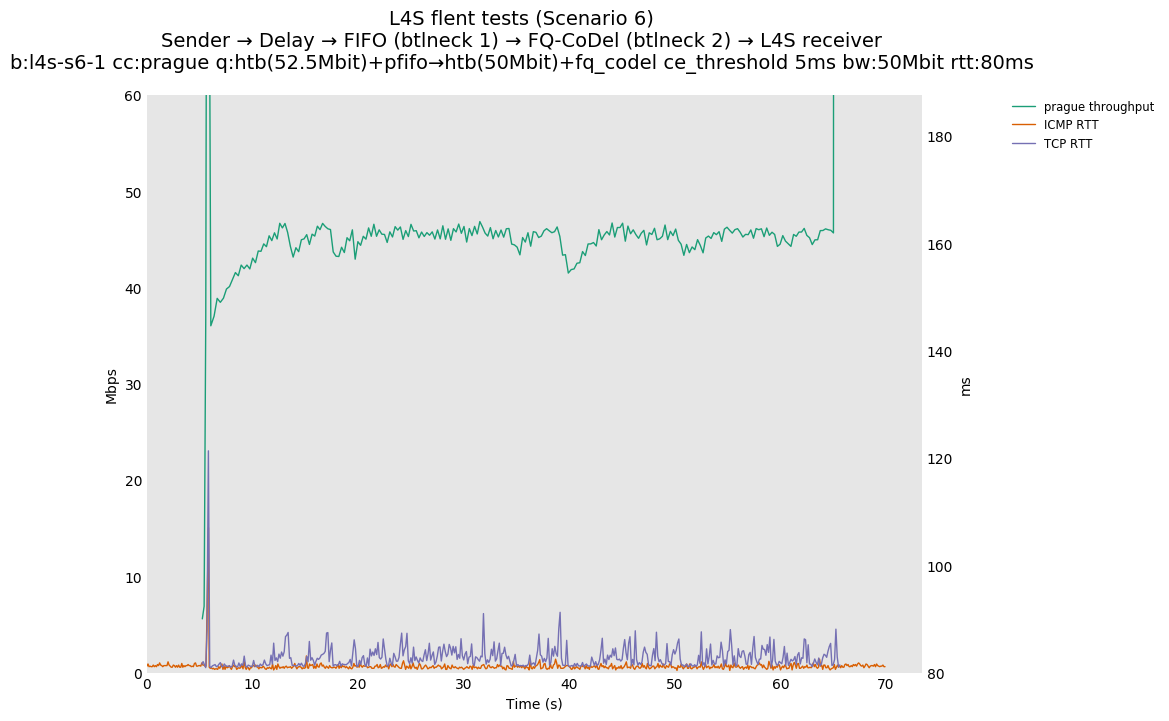
This is similar to Scenario 5, but narrowed down to just the FIFO and CoDel combination. Correct behaviour would show a brief latency peak caused by the interaction of slow-start with the FIFO in the subject topology, or no peak at all for the control topology; you should see this for whichever RFC 3168 flow is chosen as the control. Expected results with L4S in the subject topology, however, are a peak extending about 4 seconds before returning to baseline.
L4S: Sender → Delay → FIFO middlebox (bottleneck #1, 52.5Mbit) → FQ-AQM middlebox (bottleneck #2, 50Mbit) → L4S receiver
| 50Mb-0ms | 50Mb-10ms | 50Mb-80ms |
|---|---|---|
| reno | reno | reno |
| cubic | cubic | cubic |
| bbr | bbr | bbr |
| prague | prague | prague |
| prague-vs-prague | prague-vs-prague | prague-vs-prague |
| cubic-vs-prague | cubic-vs-prague | cubic-vs-prague |
| cubic-vs-bbr | cubic-vs-bbr | cubic-vs-bbr |
This scenario shows no significant difference from scenario 5.
| 50Mb-0ms | 50Mb-10ms | 50Mb-80ms |
|---|---|---|
| prague | prague | prague |
| prague-vs-prague | prague-vs-prague | prague-vs-prague |
| cubic-vs-prague | cubic-vs-prague | cubic-vs-prague |
| 50Mb-0ms | 50Mb-10ms | 50Mb-80ms |
|---|---|---|
| prague | prague | prague |
| prague-vs-prague | prague-vs-prague | prague-vs-prague |
| cubic-vs-prague | cubic-vs-prague | cubic-vs-prague |
| 50Mb-0ms | 50Mb-10ms | 50Mb-80ms |
|---|---|---|
| prague | prague | prague |
| prague-vs-prague | prague-vs-prague | prague-vs-prague |
| cubic-vs-prague | cubic-vs-prague | cubic-vs-prague |
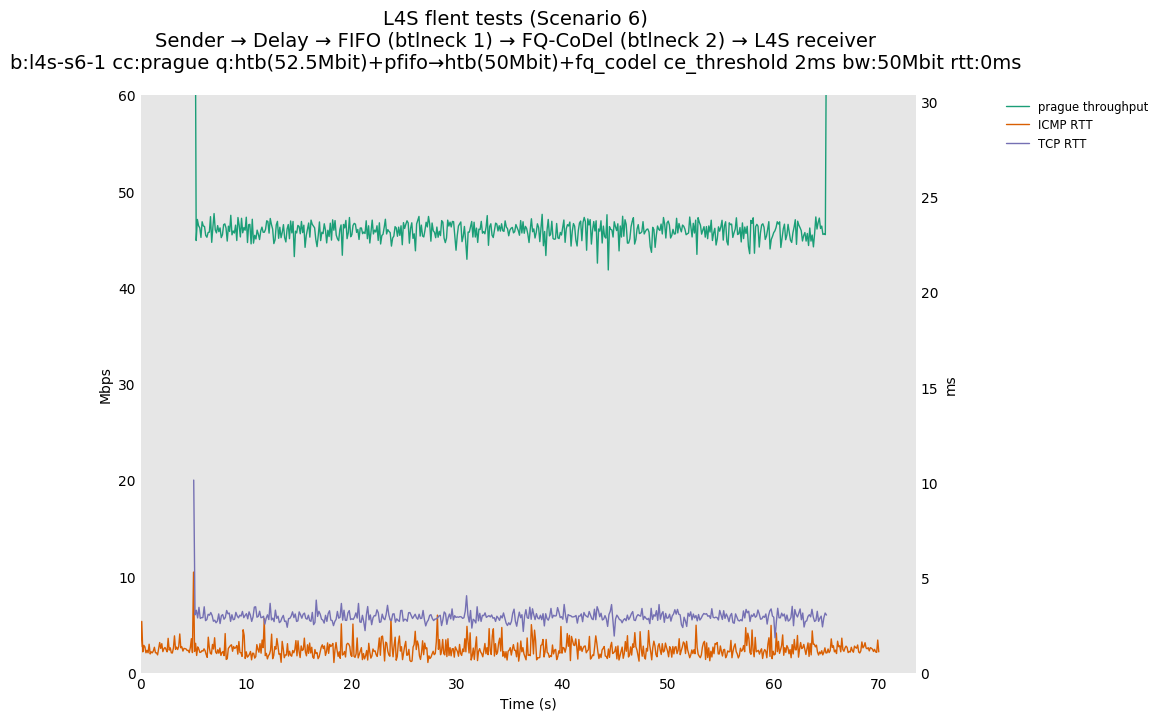
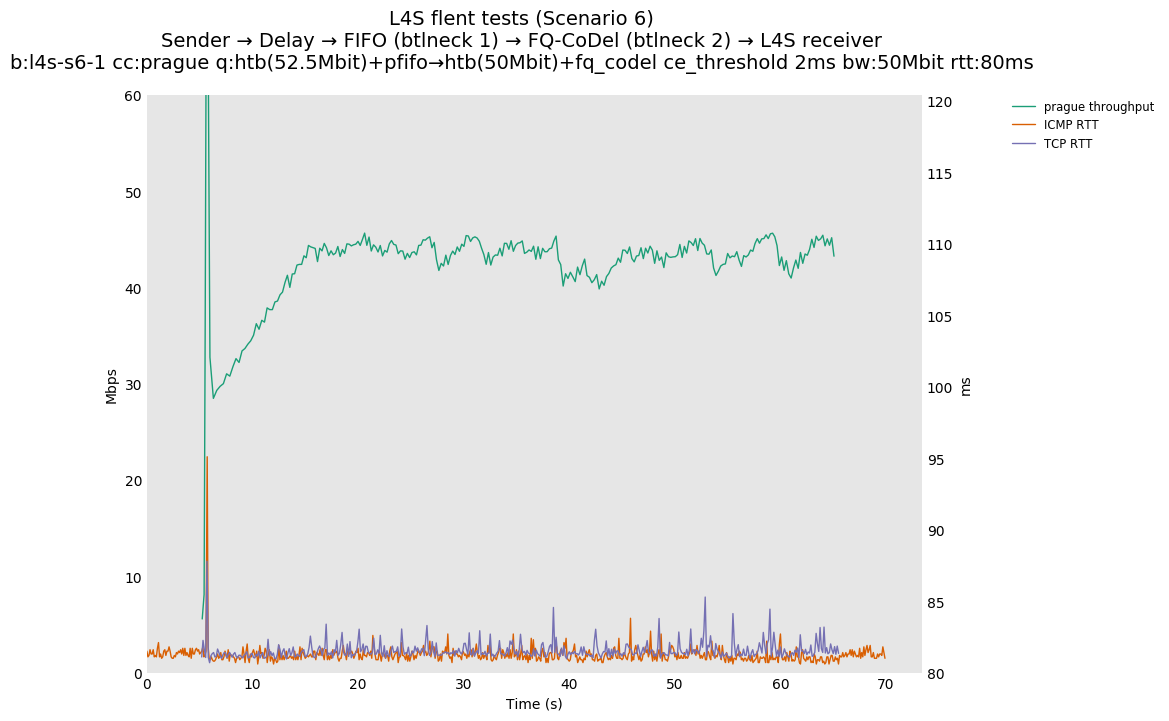
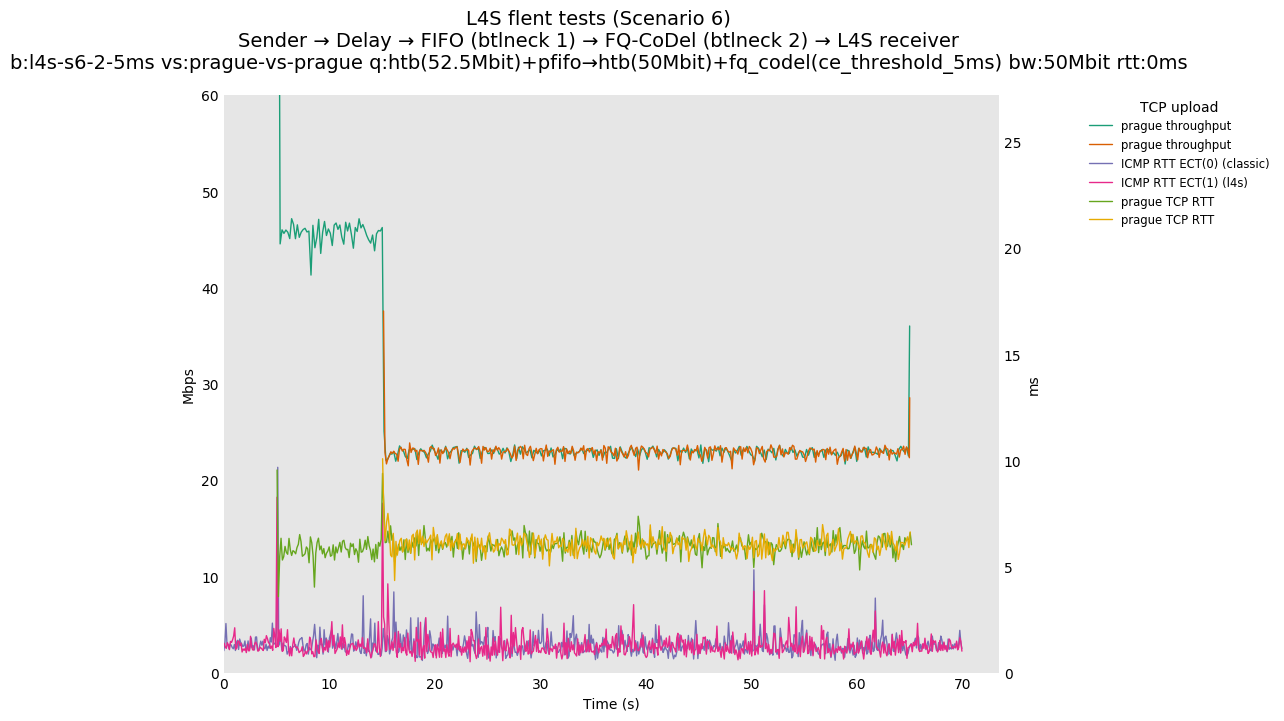
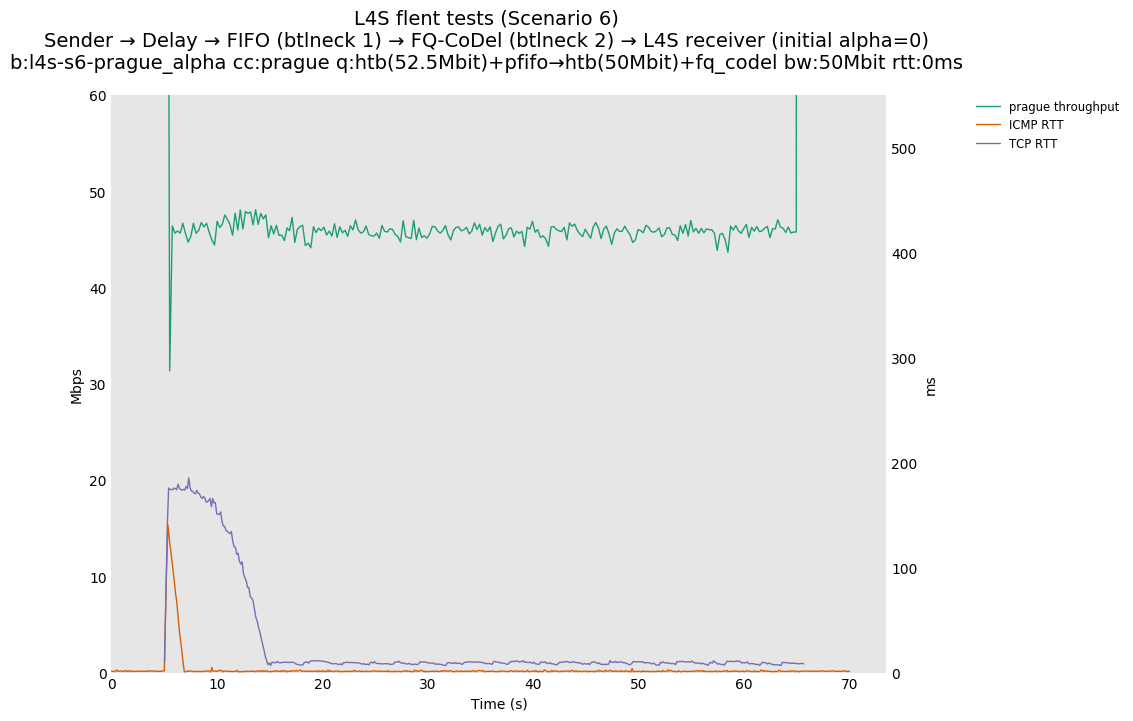
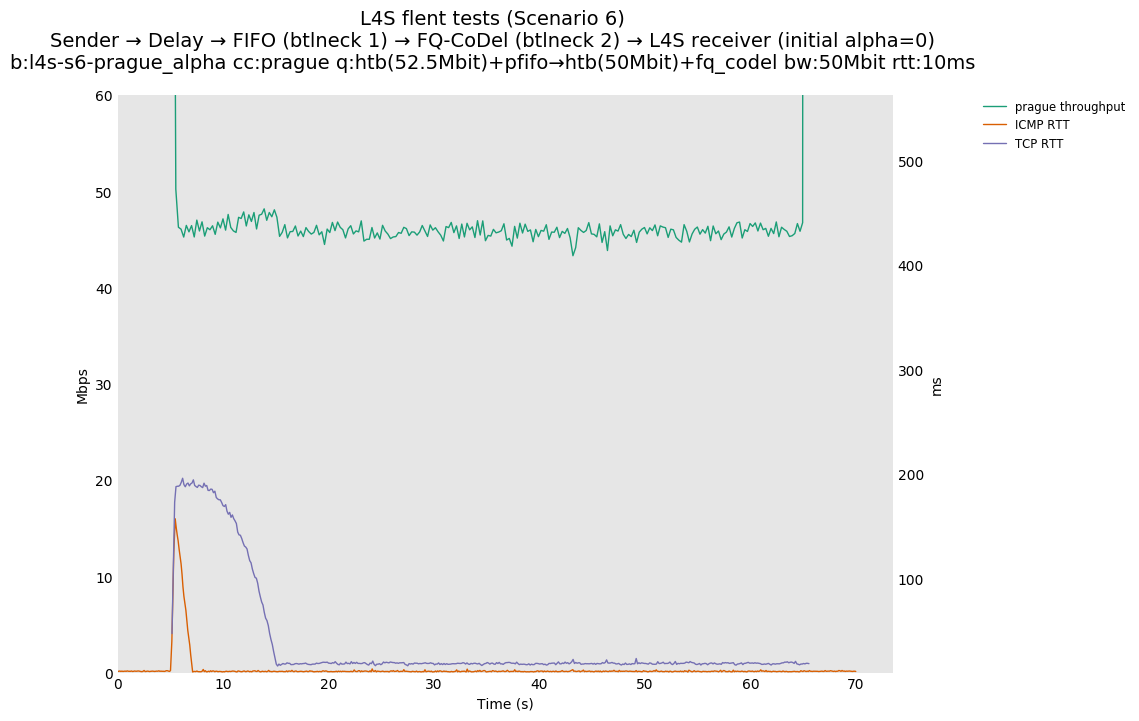
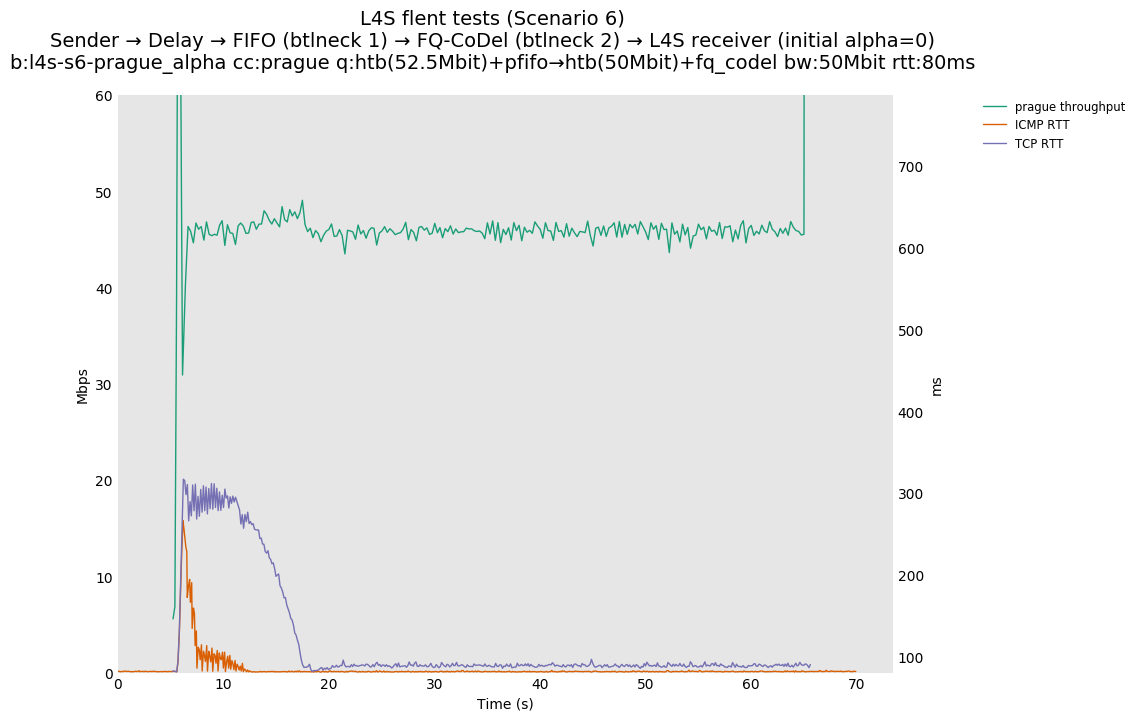
The internal alpha value is aligned to dctcp, i.e., is initialized to its maximal value. This is the single biggest source of the improvements reported in this document, as it aligns the behavior of TCP Prague to the one of dctcp in P.Heist's tests.
You can compare this against the previous default value of alpha (0) for scenario 6 (FIFO followed by fq_codel) on the following graphs:
| 50Mb-0ms | 50Mb-10ms | 50Mb-80ms |
|---|---|---|
| prague-alpha0 | prague-alph0 | prague-alpha0 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}