Tom Henderson, Olivier Tilmans, Greg White
This document summarizes recent testbed and simulation results conducted to investigate potential issues raised by tsvwg members about the L4S architecture. The testbed results were conducted by Olivier Tilmans based on the scripts and methodology published recently by Pete Heist. Simulation experiments were conducted by Tom Henderson and Greg White.
We summarize here our key findings and provide pointers to other repositories for more details and instructions on how to reproduce our results. We will first discuss Issue 17 (the main area of investigation) but also present some results regarding Issue 16.
Issue 17 was raised by Jonathan Morton based on a topology described by Sebastian Moeller on the tsvwg mailing list. The experiment, as described by Jonathan is as follows:
> Here is a simple experiment that should verify the existence and extent of the problem:
>
> Control:
> [Sender] -> [Baseline RTT 10ms] -> [FQ_Codel, 100% BW] -> [Receiver]
>
> Subject:
> [Sender] -> [Baseline RTT 10ms] -> [Dumb FIFO, 105% BW] -> [FQ_Codel, 100% BW] -> [Receiver]
>
> Background traffic is a sparse latency-measuring flow, essentially a surrogate for gaming or
VoIP. The instantaneous latency experienced by this flow over time is the primary measurement.
>
> The experiment is simply to start up one L4S flow in parallel with the sparse flow, and let it
run in saturation for say 60 seconds. Repeat with an RFC-3168 flow (NewReno, CUBIC, doesn't
matter which) for a further experimental control. Flent offers a convenient method of
doing this.
>
> Correct behaviour would show a brief latency peak caused by the interaction of slow-start
with the FIFO in the subject topology, or no peak at all for the control topology; you
should see this for whichever RFC-3168 flow is chosen as the control. Expected results
with L4S in the subject topology, however, are a peak extending about 4 seconds before
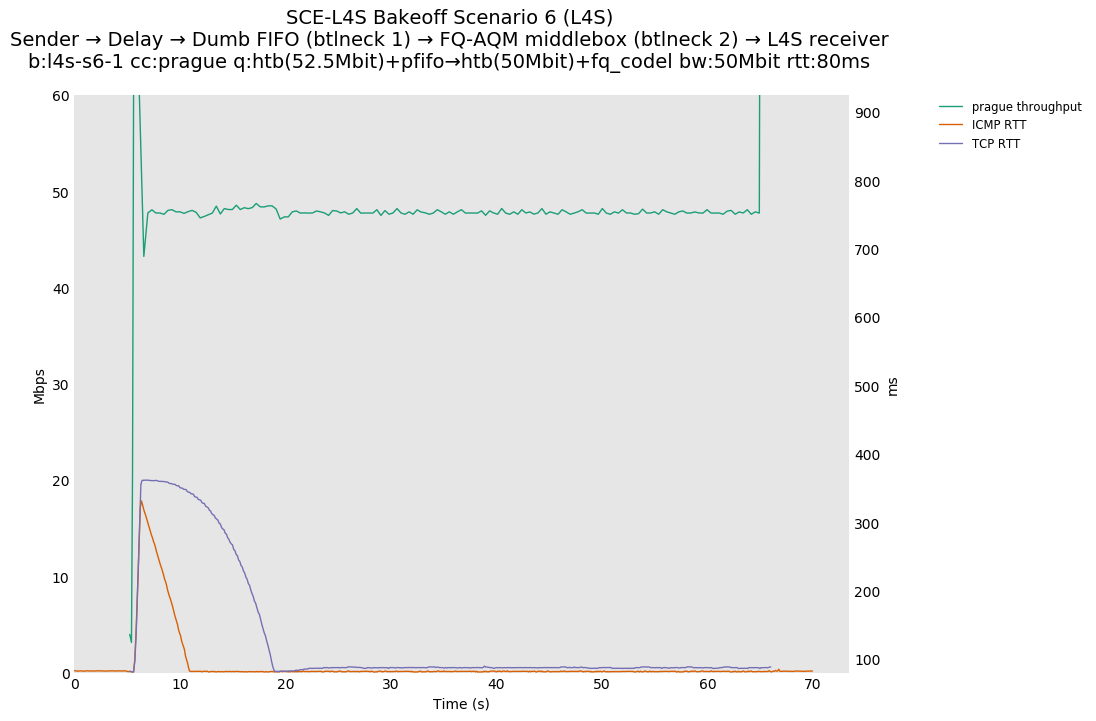
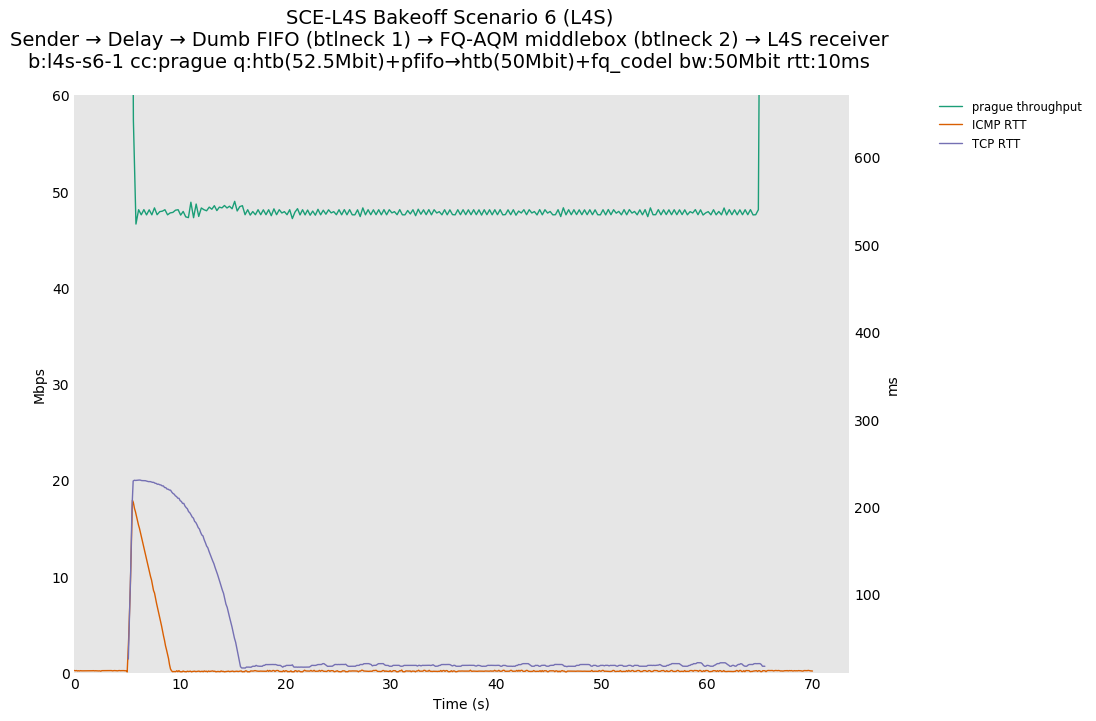
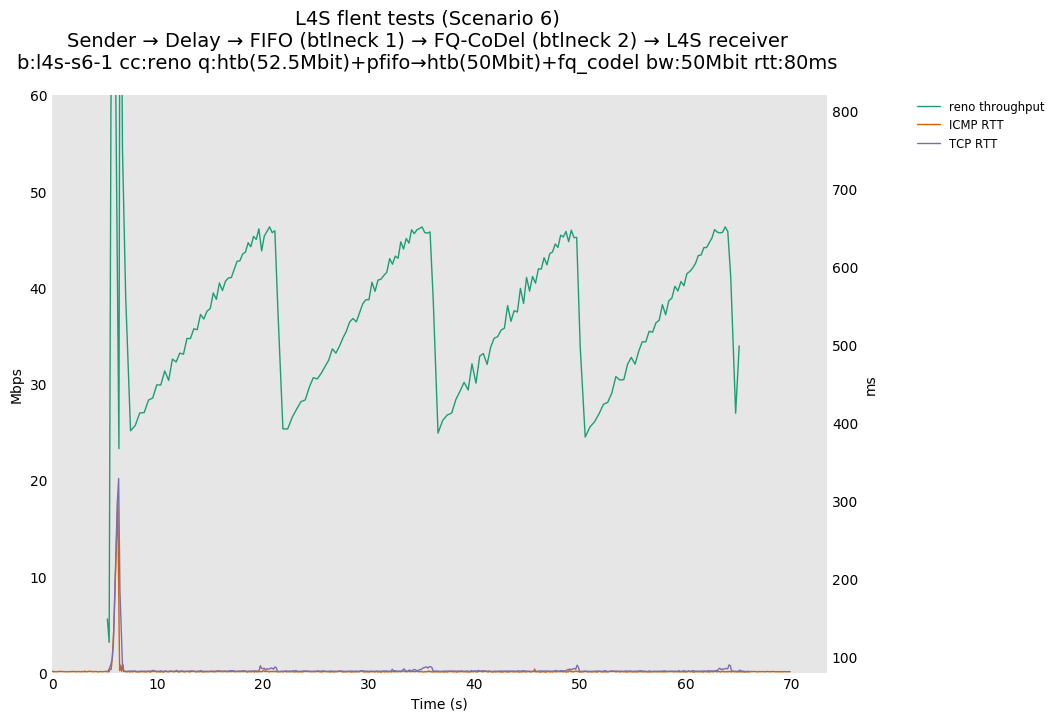
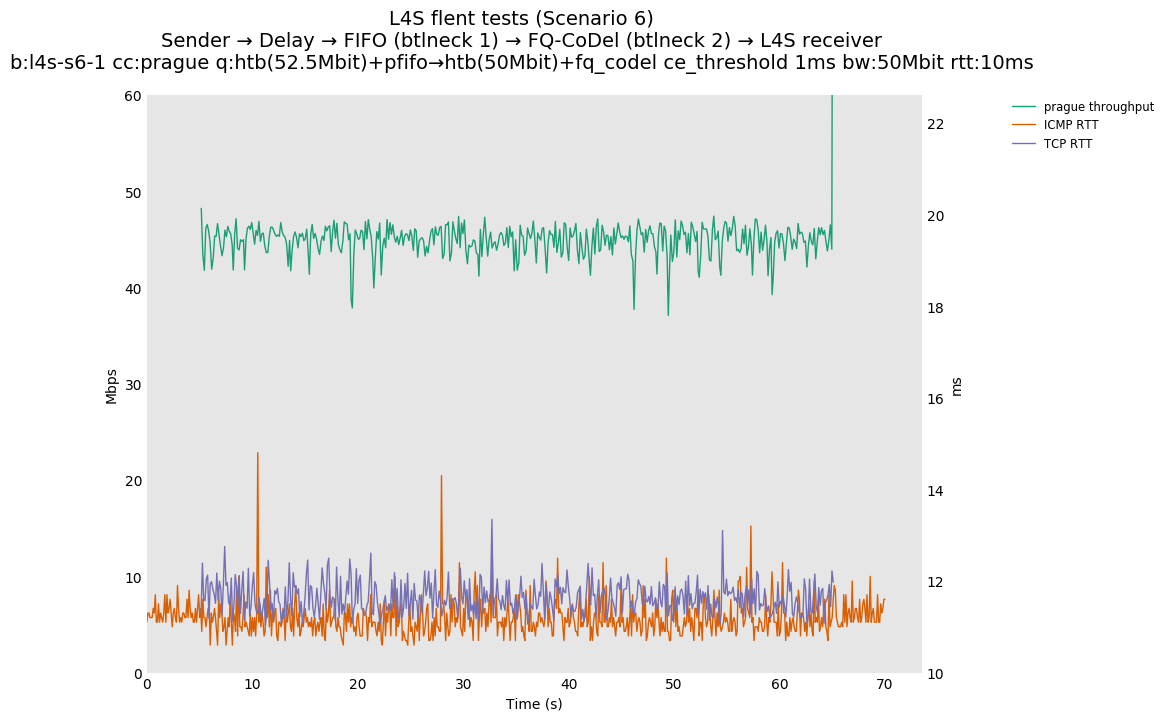
returning to baseline.L4S results from Pete Heist's "Scenario 6" showed that, when Prague is started in such a scenario, the impact on non-L4S flow latency can be substantial. This plot exemplifies the performance concern, where the ICMP flow is impacted by up to a six second period of queueing latency that peaks at around 250ms, because the overall burst of traffic due to Prague slow start overflows the FQ-CoDel queue into the FIFO queue, where it cannot be controlled. The Prague latency also takes about fifteen seconds to recover.
Using ns-3 simulations set up to mimic the testbed setup, we were able to recreate situations in which the FQ-CoDel queue overflowed into the FIFO queue. We used ns-3 models of DCTCP, Cubic, and NewReno (an ns-3 Prague model is not yet available). In ns-3, we are also able to use selected versions of the Linux TCP implementations through an environment called Direct Code Execution (DCE), in which the Linux kernel (in this case, kernel 4.4) is built in a special way as a user-space library. Because TCP Prague uses a conventional slow start, we hypothesized that DCTCP is suitable as a surrogate for this experiment which mainly deals with slow start effects.
Using ns-3, we were also able to sweep through a range of base RTTs and bottleneck link rates. However, we were not able to reproduce (neither with the Linux TCP implementations nor with the ns-3 TCP implementations) the behavior reported above; the latency spike is present for all congestion controls but rarely exceeds 160 ms and never lasts longer than about 1 second in duration.
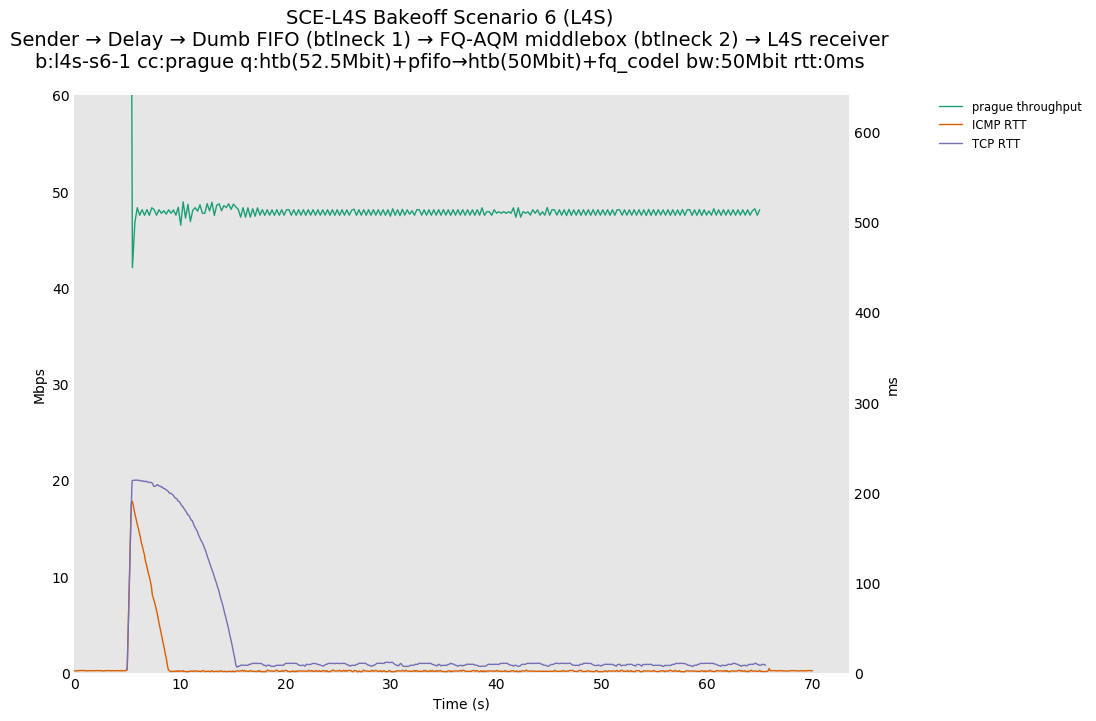
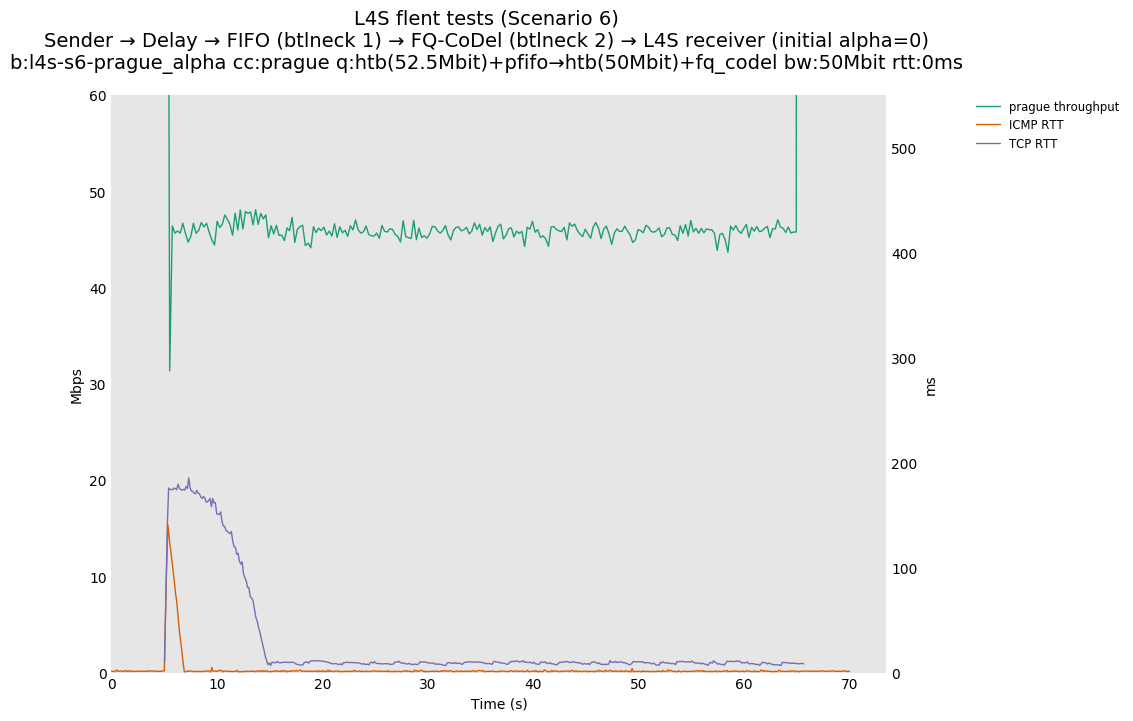
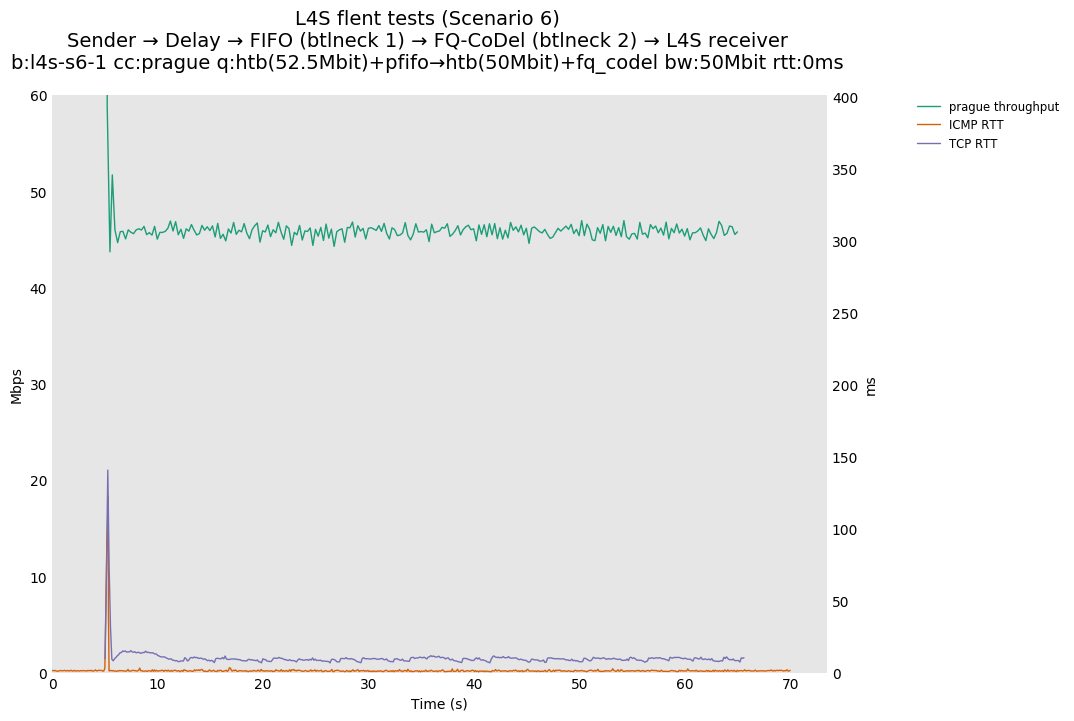
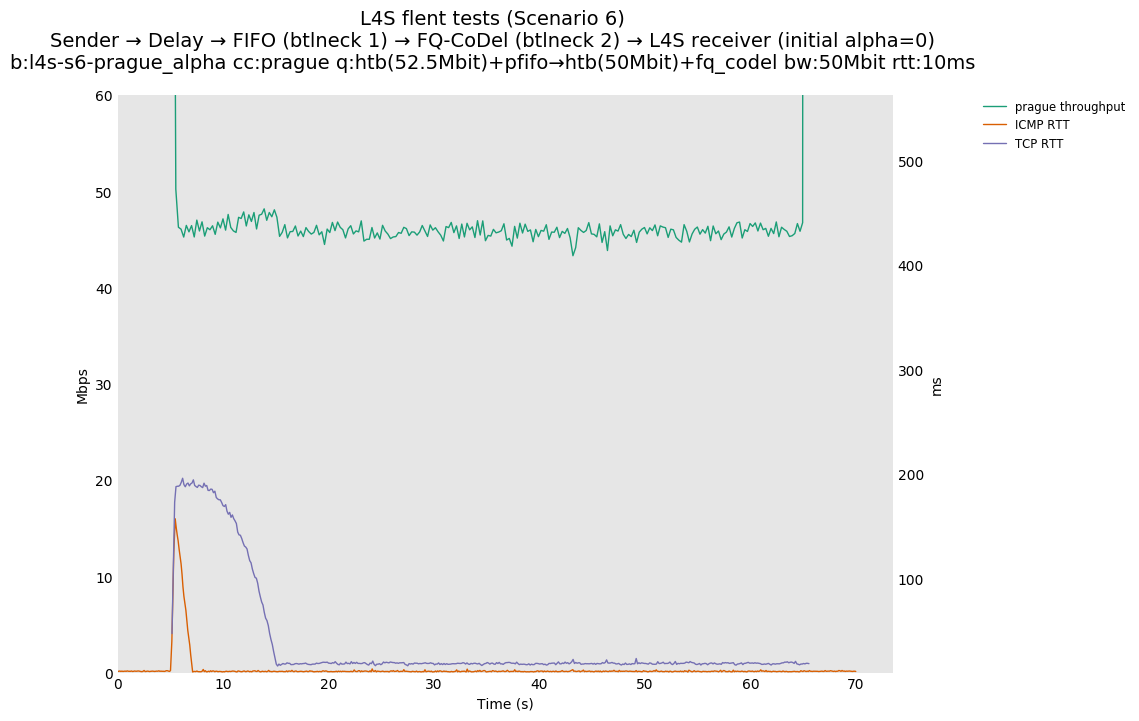
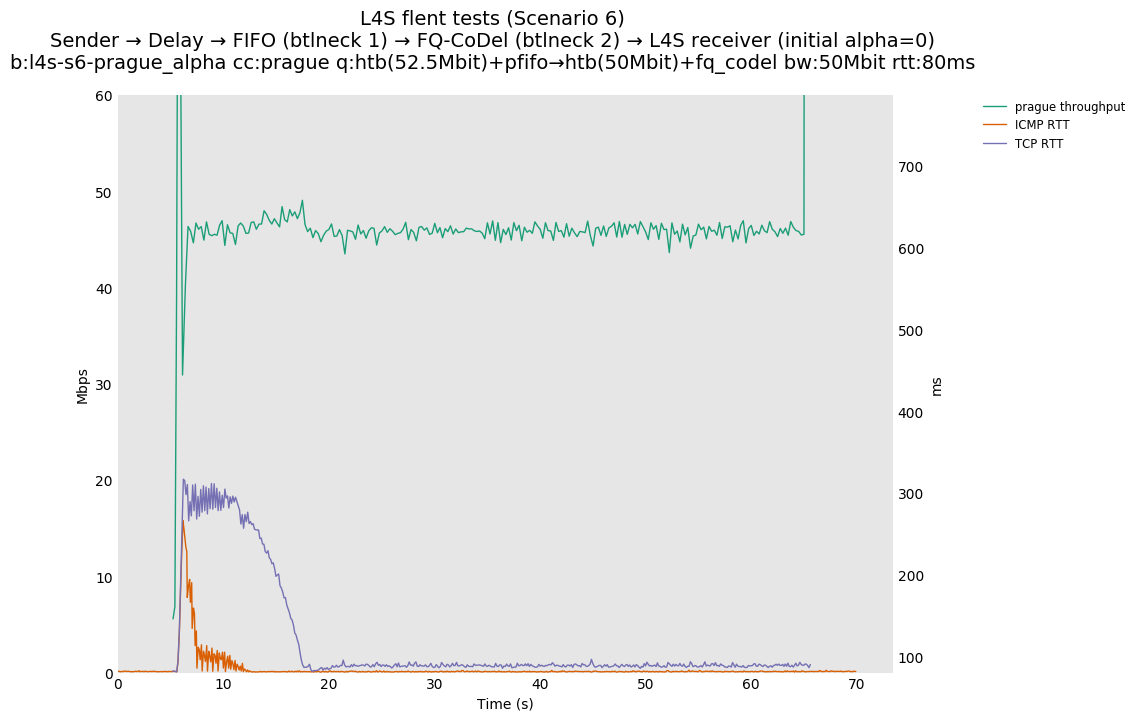
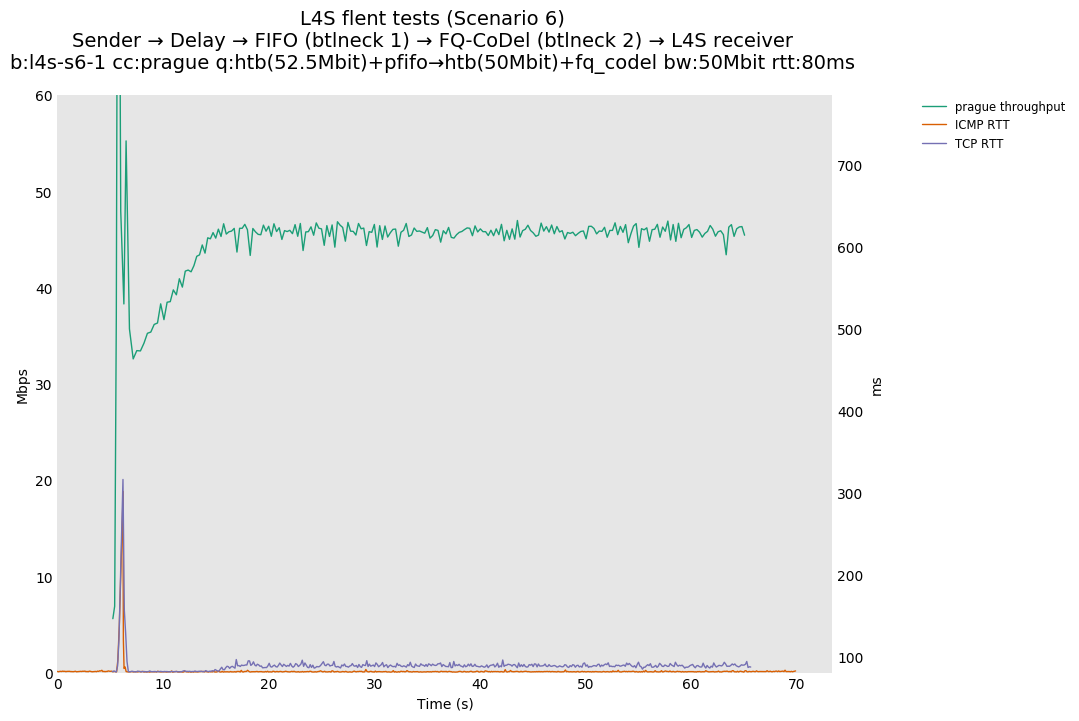
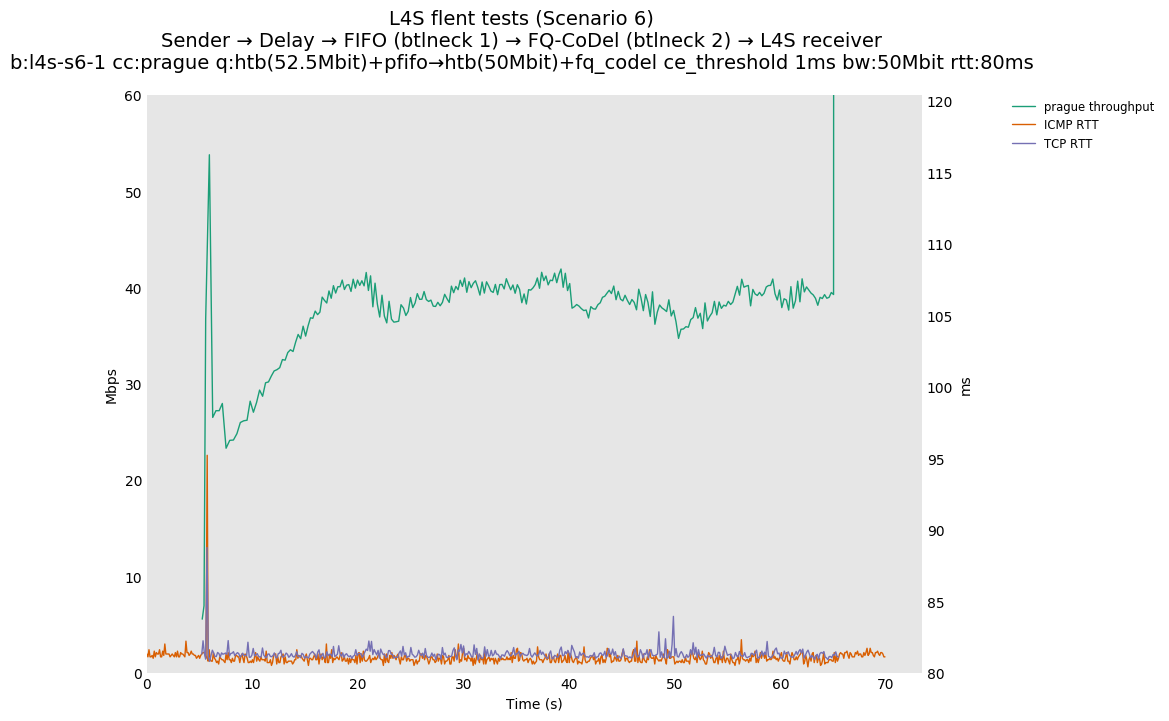
Based on this, Olivier Tilmans had a closer look at the full results posted by Pete Heist, and noticed that the DCTCP testbed results also did not show this pronounced effect, and were in line with the ns-3 results. He then spotted a bug in the version of Prague used in the testbed results. The value of initial alpha was incorrectly set to zero, which could lead to the sluggish response observed by Pete Heist. Olivier Tilmans was able to reproduce results similar to Pete Heist's results by using an initial alpha of zero, and then able to correct this by using an initial alpha of 1 (as used in DCTCP).
| RTT | With Alpha Bug | Without Alpha Bug |
|---|---|---|
| 0 ms | pheist otilmans |
otilmans |
| 10 ms | pheist otilmans |
otilmans |
| 80 ms | pheist otilmans |
otilmans |
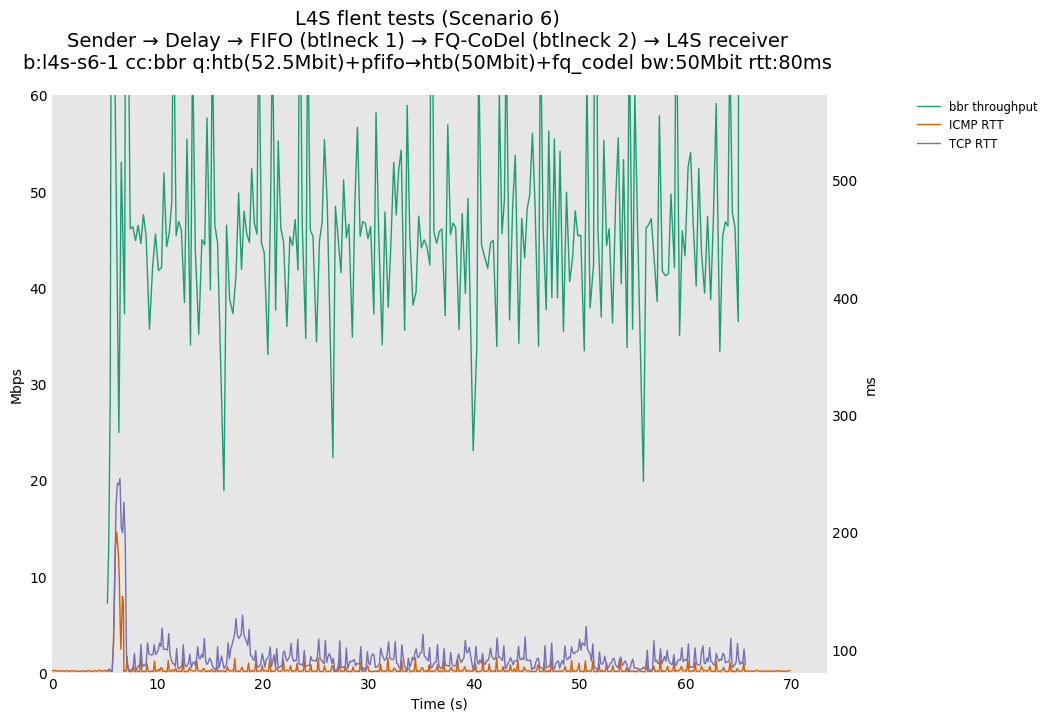
We also observed that an ICMP latency spike in this issue 17 topology is observable for many congestion controls (we tested Reno, BBRv1, Cubic, DCTCP and Prague) and is not heavily impacted by the selection of congestion control algorithms. Examples of: Reno, BBR, Cubic, and Prague. This latency spike is the result of the fact that the fq_codel rate shaper is set to a rate that is very close to (95% of) the FIFO egress rate and the CoDel algorithm delays its congestion signal by 100ms (multiple RTTs in some cases) which allows slow-start to briefly exceed the FIFO egress rate. In simulation, we experimented with adjusting the fq_codel shaper to 90% of the FIFO egress rate and observed an expected reduction in the magnitude of the FIFO latency spike (along with the expected reduction in bottleneck link utilization).
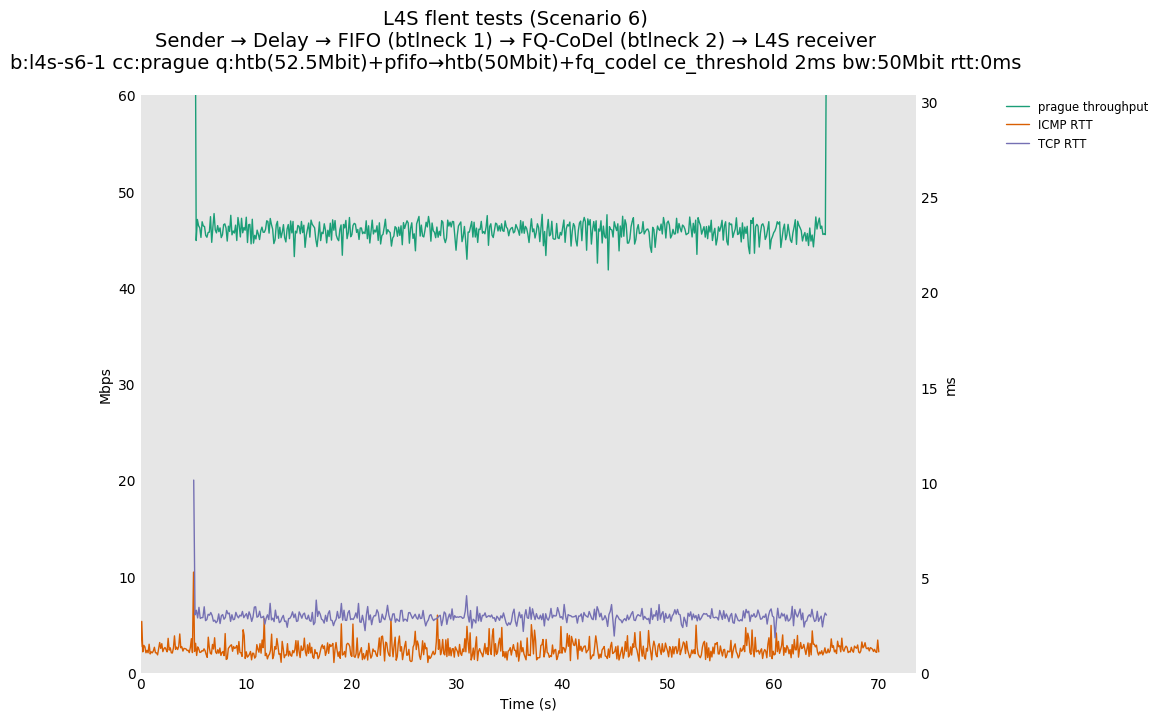
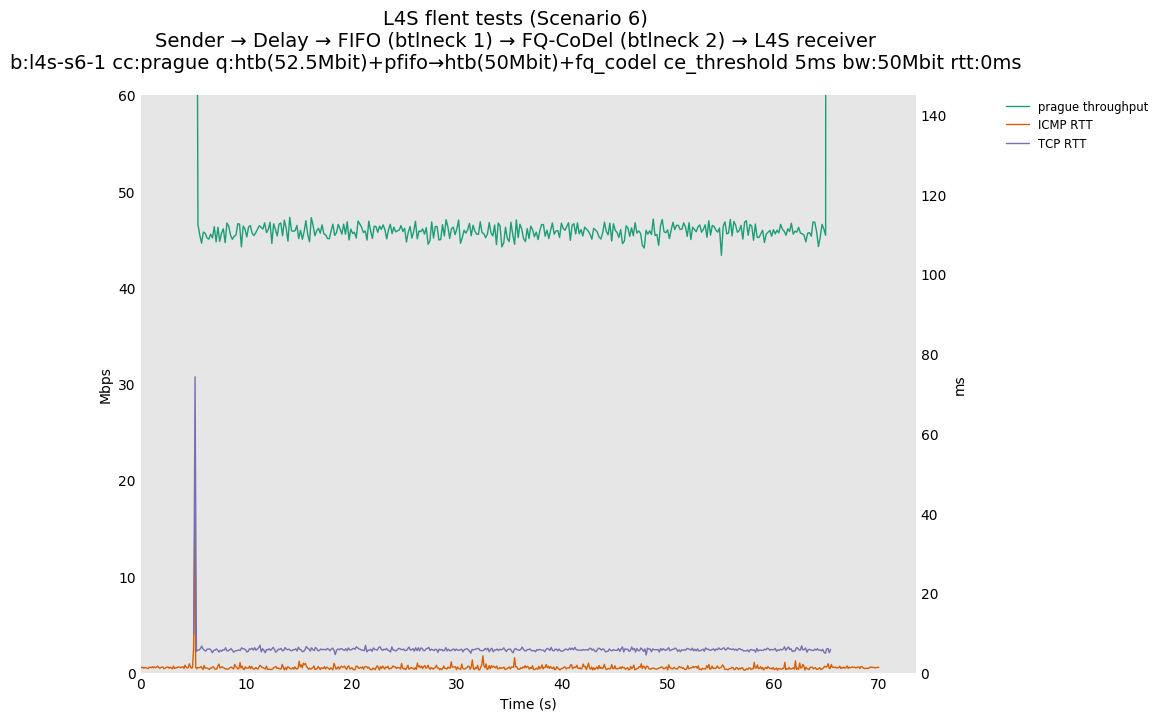
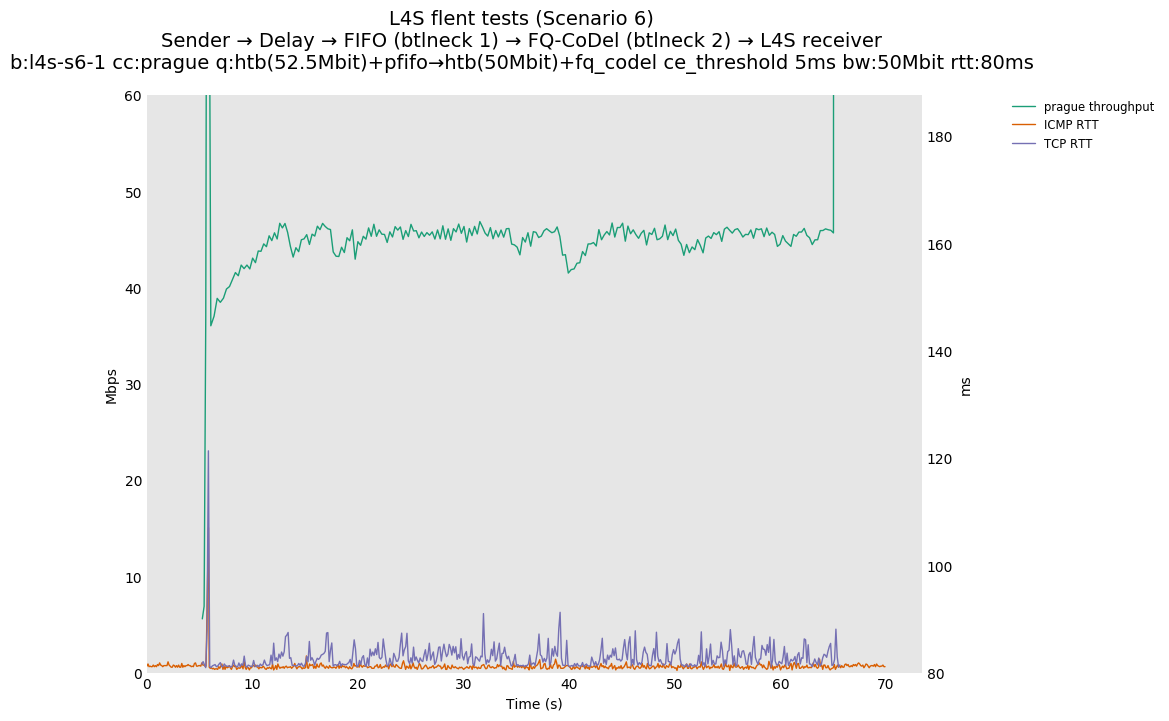
Furthermore, for TCP Prague traffic, this spike can be largely eliminated (while leaving the fq_codel rate shaper at 95% of the FIFO rate) by simply introducing support for Immediate AQM marking in the fq_codel queue. We performed some experiments approximating an L4S-compatible (Immediate AQM) response to the L4S traffic, for a future FQ_CoDel that is upgraded for L4S-awareness. Using the current Linux fq_codel implementation, the 'CE threshold' setting can be reused to provide a hard marking threshold for single-flow experiments. We experimented with CE threshold values of 1ms, 2ms and 5ms in the testbed and in simulation. In this case, the overrun into the M1 queue is very small and short-lived, and the ICMP traffic (sent at 100ms intervals) misses these short peaks entirely. Sample results are shown below.
| RTT | CE thresh = 1 ms | CE thresh = 2ms | CE thresh = 5 ms |
|---|---|---|---|
| 0 ms | testbed simulation |
testbed simulation |
testbed simulation |
| 10 ms | testbed simulation |
testbed simulation |
testbed simulation |
| 80 ms | testbed simulation |
testbed simulation |
testbed simulation |
In summary, we reached the following conclusions:
the main result of concern was due to a bug in initializing the value of TCP Prague alpha, which has been fixed and demonstrated to resolve the latency impact that was spanning multiple seconds
the remaining short duration latency spike in the FIFO queue is seen in all congestion control variants tested, including BBRv1, NewReno, and Cubic, and is not specific to Prague
if the CoDel queue is upgraded to perform Immediate AQM on L4S flows, the latency spike can be largely avoided.
The Issue 17 topology is intended to model a deployment configuration that is used in practice in CAKE-based rate shaping. As noted above, this configuration suffers from latency spikes caused the TCP slow-start behavior and inadequate control provided by the CoDel active queue management algorithm. Aside from the latency spikes, the configuration produces good latency performance, but unfortunately appears to suffer from significant underutilization of the bottleneck link when a single TCP Reno or Cubic flow is present, for example only achieving 85% link utilization with Cubic on a 100 Mbps / 80 ms connection.
As described in the tracker, Issue 16 (also called Issue A at IETF 105) notes that L4S senders need to safely transit non-L4S (e.g. RFC 3168-only) AQMs that are on the path of a data flow. The issue of concern is that RFC 3168 ECN feedback cannot control a sender rapidly enough to avoid rate unfairness between L4S and classic flows existing in the same bottleneck queue.
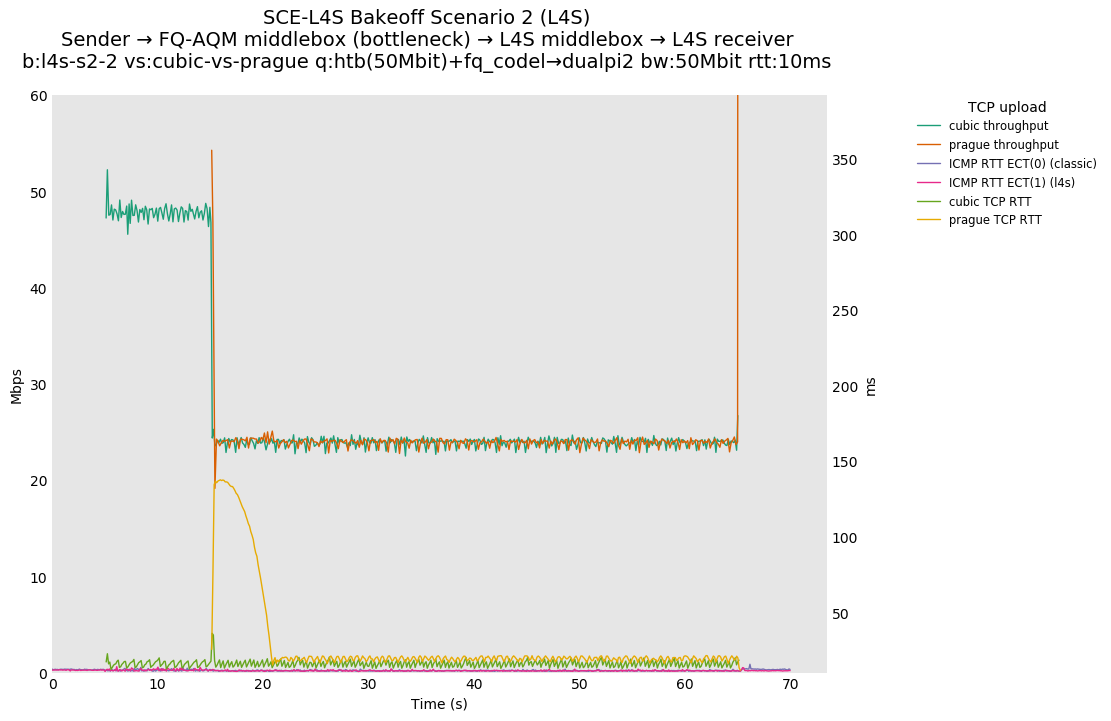
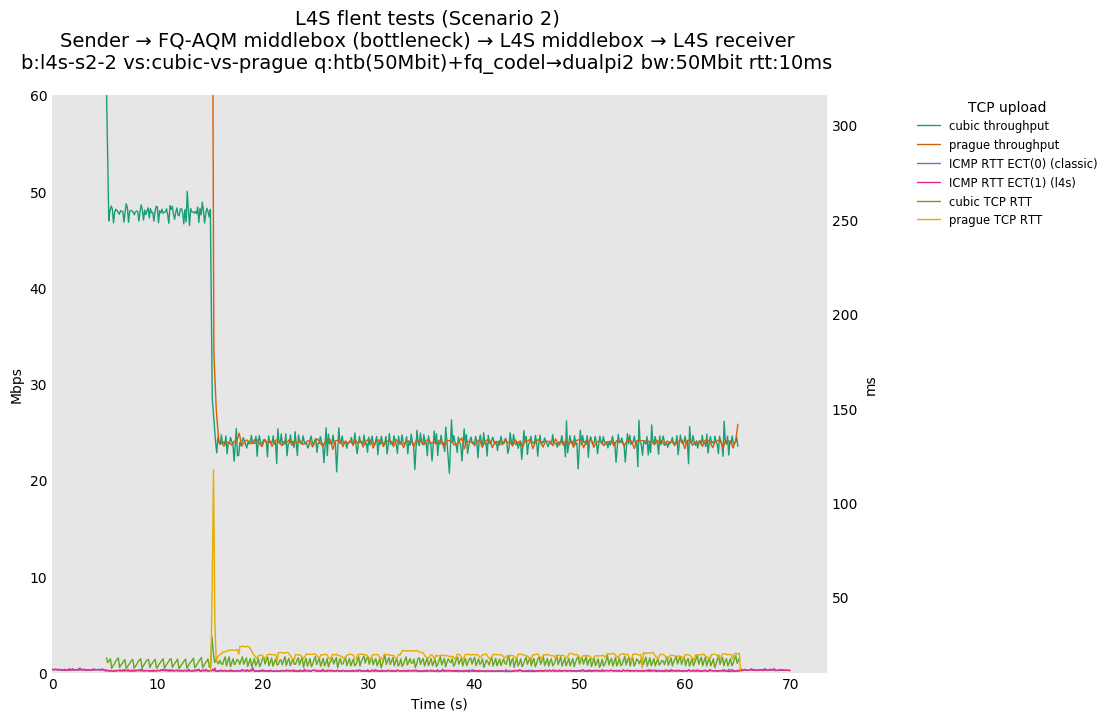
Scenario 2 test results from Pete Heist show examples of behavior when a Cubic flow is traversing a bottleneck FQ-CoDel queue, and then a Prague flow starts up. In a representative result, the two flows converge quickly to equal rate (due to the FQ-CoDel scheduler) but the Prague latency is impacted for approximately six seconds.
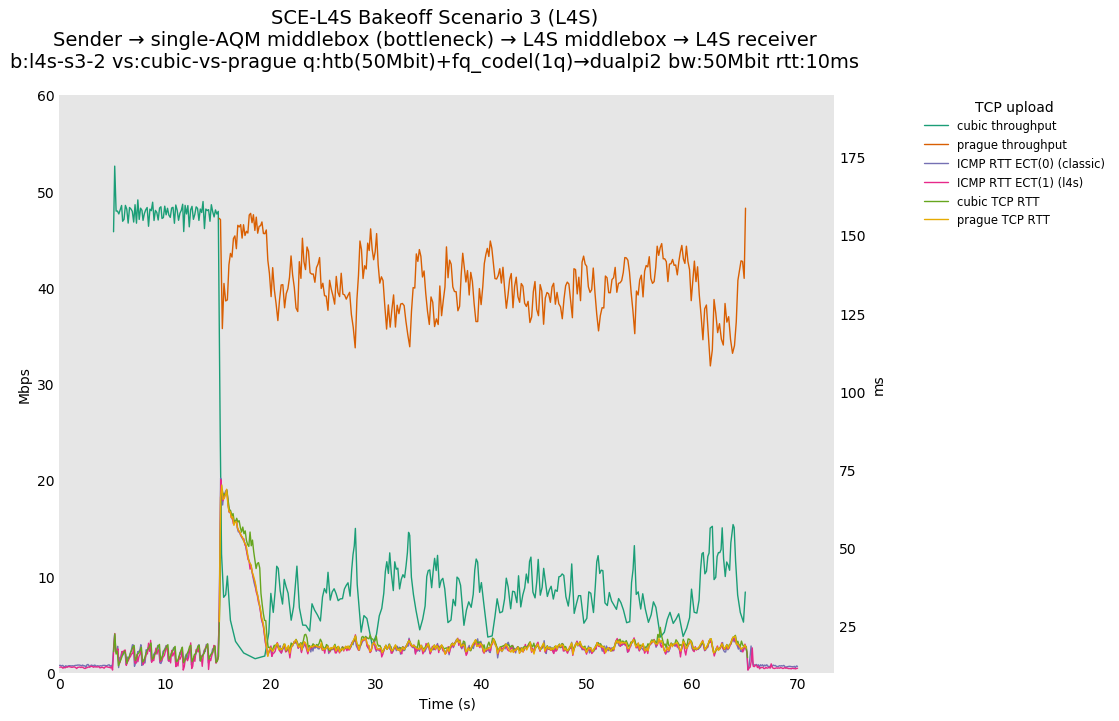
Scenario 3 test results show a similar experiment but for a single CoDel AQM (rather than a FQ-CoDel) bottleneck. A representative result is found in the two-flow observations, Cubic vs. Prague at 10ms.
As discussed above in the discussion around issue 16, the latency response of Prague is attributed to a bug in the version of Prague used, in which alpha is initialized to zero and not one. We are able to reproduce the Scenario 2 FQ-CoDel result in simulation and show that it is resolved by initializing alpha to one.
Regarding Scenario 3 (interaction with a single-queue AQM), we are able to reproduce similar rate unfairness results in both simulation and testbed. We hypothesize that this can be avoided if RFC 3168 detection mechanism is added to TCP Prague (the design details are documented in a discussion paper and for which prototyping has started).
We have published more details about our simulation and testbed experiments and results at the following locations:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}